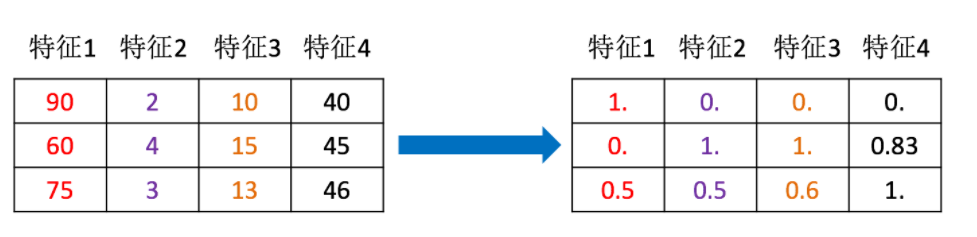
通过一些转换函数将特征数据转换成更加适合算法模型的特征数据过程。
我们需要用到一些方法进行无量纲化,使不同规格的数据转换到同一规格
通过对原始数据进行变换把数据映射到(默认为[0,1])之间
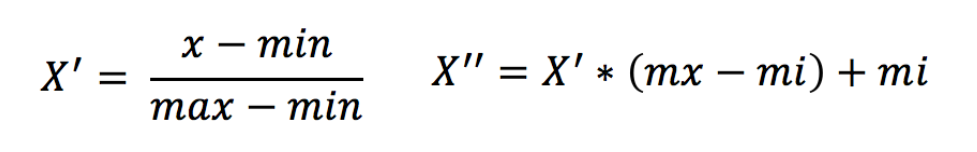
作用于每一列,max为一列的最大值,min为一列的最小值,那么X’’为最终结果,mx,mi分别为指定区间值默认mx为1,mi为0
那么怎么理解这个过程呢?我们通过一个例子
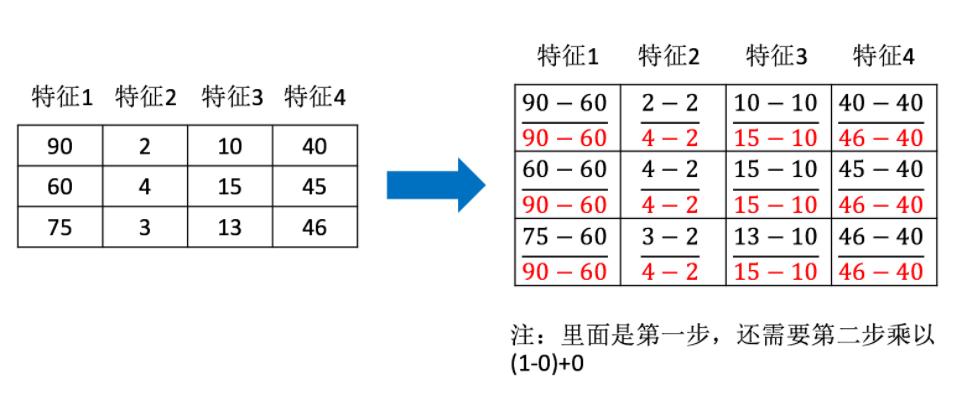
样例计算:

sklearn.preprocessing.MinMaxScaler (feature_range=(0,1)… ) MinMaxScalar.fit_transform(X) X:numpy array格式的数据[n_samples,n_features] 返回值:转换后的形状相同的array
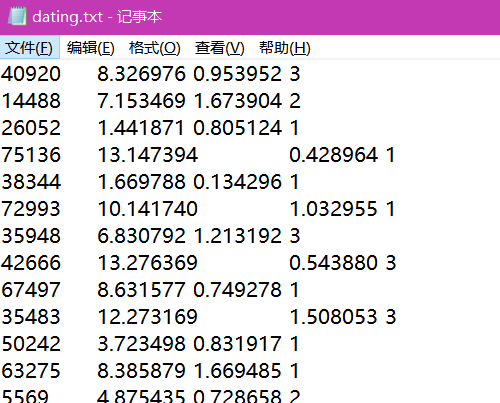
数据样例:
#归一化演示
def minmax_demo():
"""
归一化演示
:return: None
"""
data = pd.read_csv("dating.txt")
#只要前三列
data=data.iloc[:,:3]
print(data)
# 1、实例化一个转换器类
transfer = MinMaxScaler(feature_range=(2, 3))#参数是设定归一化的范围
# 2、调用fit_transform
data1 = transfer.fit_transform(data)
#data[[‘milage‘,‘Liters‘,‘Consumtime‘]]这样也是去那些列
print("最小值最大值归一化处理的结果:\n", data1)
return None
if __name__=="__main__":
minmax_demo()
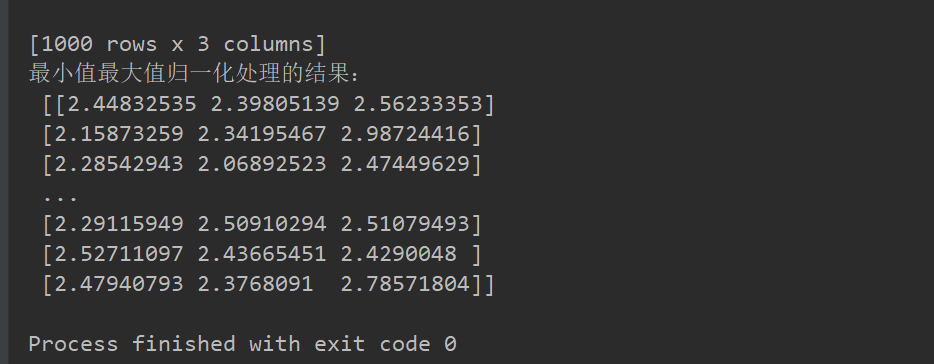
注意最大值最小值是变化的,另外,最大值与最小值非常容易受异常点影响(也包括缺省值等等),所以这种方法鲁棒性较差(健壮性较差),只适合传统精确小数据场景。
通过对原始数据进行变换把数据变换到均值为0,标准差为1范围内
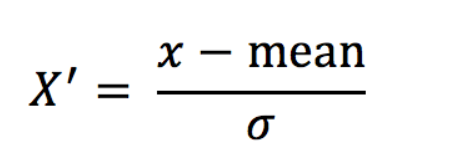
作用于每一列,mean为平均值,σ为标准差
所以回到刚才异常点的地方,我们再来看看标准化
sklearn.preprocessing.StandardScaler( )
处理之后每列来说所有数据都聚集在均值0附近标准差差为1
StandardScaler.fit_transform(X)
X:numpy array格式的数据[n_samples,n_features]
返回值:转换后的形状相同的array
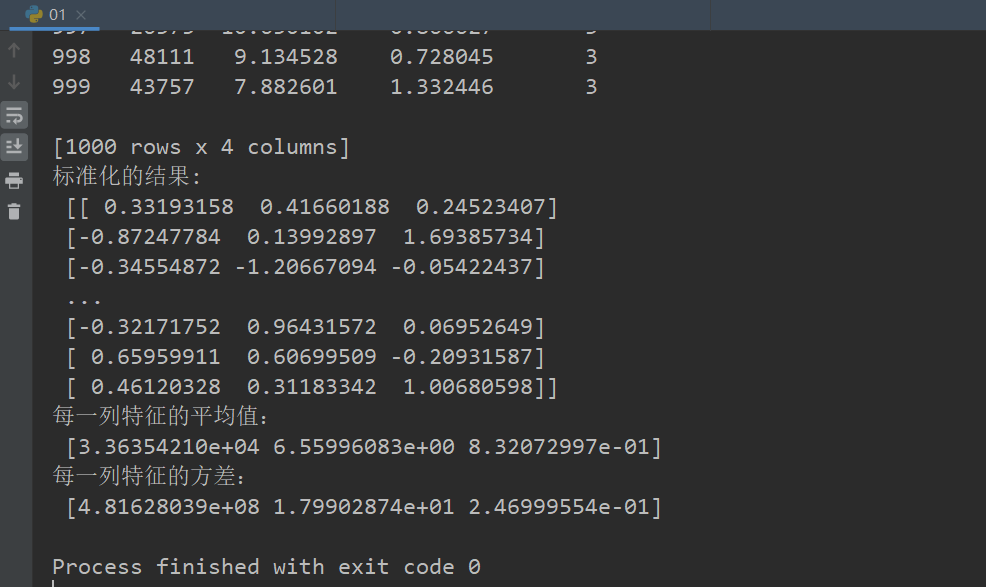
#标准化演示 def stand_demo(): """ 标准化演示 :return: None """ data = pd.read_csv("dating.txt") # 只要前三列data = data.iloc[:, :3]和后边data[[‘milage‘,‘Liters‘,‘Consumtime‘]]和效果一样 print(data) # 1、实例化一个转换器类 transfer = StandardScaler() # 2、调用fit_transform data = transfer.fit_transform(data[[‘milage‘,‘Liters‘,‘Consumtime‘]]) print("标准化的结果:\n", data) print("每一列特征的平均值:\n", transfer.mean_) print("每一列特征的方差:\n", transfer.var_) return None if __name__=="__main__": stand_demo()
在已有样本足够多的情况下比较稳定,适合现代嘈杂大数据场景。
(在这里降维是将二维数组进行处理。降的是特征的个数)
降维是指在某些限定条件下,降低随机变量(特征)个数,得到一组“不相关”主变量的过程
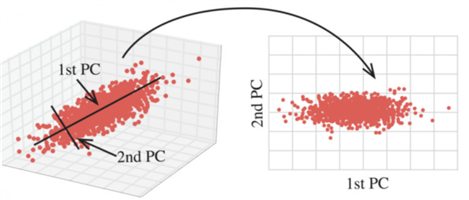
正是因为在进行训练的时候,我们都是使用特征进行学习。如果特征本身存在问题或者特征之间相关性较强,对于算法学习预测会影响较大
数据中包含冗余或无关变量(或称特征、属性、指标等),旨在从原有特征中找出主要特征。
对于Embedded方式,只能在讲解算法的时候在进行介绍,更好的去理解
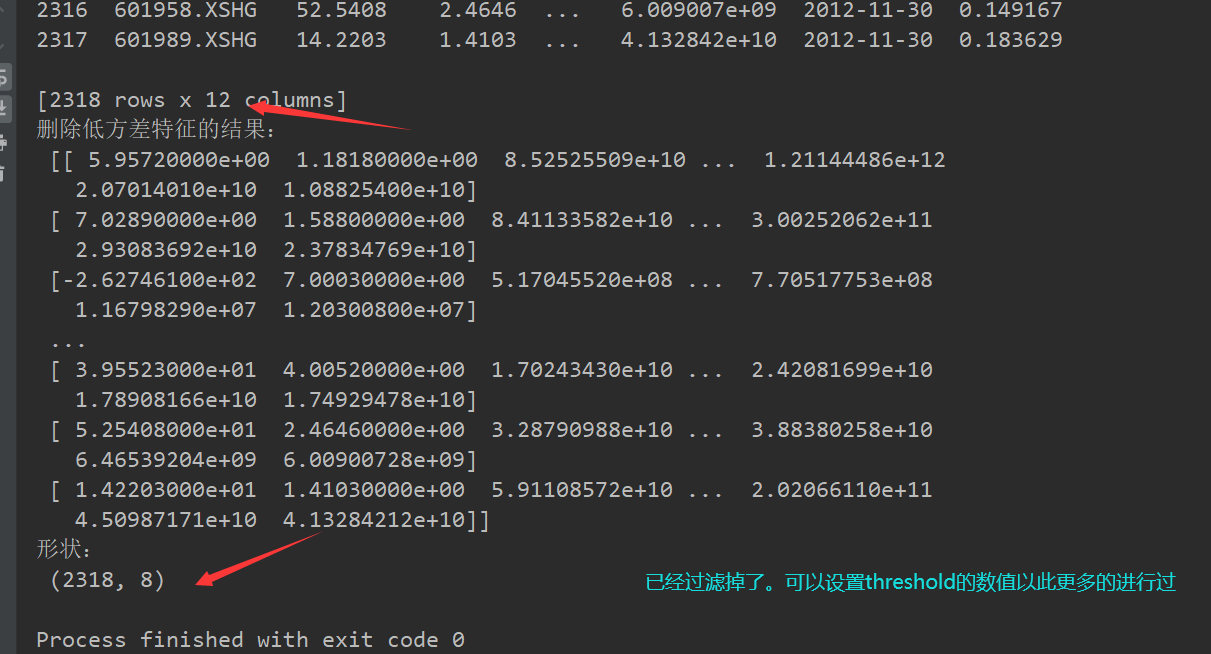
删除低方差的一些特征,前面讲过方差的意义。再结合方差的大小来考虑这个方式的角度。
sklearn.feature_selection.VarianceThreshold(threshold = 0.0) 删除所有低方差特征 Variance.fit_transform(X) X:numpy array格式的数据[n_samples,n_features] 返回值:训练集差异低于threshold的特征将被删除。默认值是保留所有非零方差特征,即删除所有样本中具有相同值的特征。
#删除低方差特征——特征选择 def variance_demo(): """ 删除低方差特征——特征选择 :return: None """ data = pd.read_csv("factor_returns.csv") print(data) # 1、实例化一个转换器类 transfer = VarianceThreshold(threshold=1) # 2、调用fit_transform data = transfer.fit_transform(data.iloc[:, 1:10])#先说行再说列用逗号分隔 print("删除低方差特征的结果:\n", data) print("形状:\n", data.shape)#多少行多少列 return None if __name__=="__main__": variance_demo()
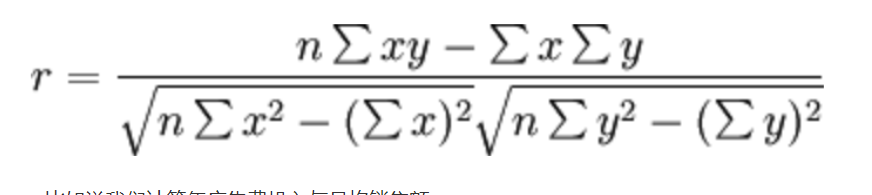
相关系数的值介于–1与+1之间,即–1≤ r ≤+1。其性质如下:
这个符号:|r|为r的绝对值, |-5| = 5
from scipy.stats import pearsonr x : (N,) array_like y : (N,) array_like Returns: (Pearson’s correlation coefficient, p-value)
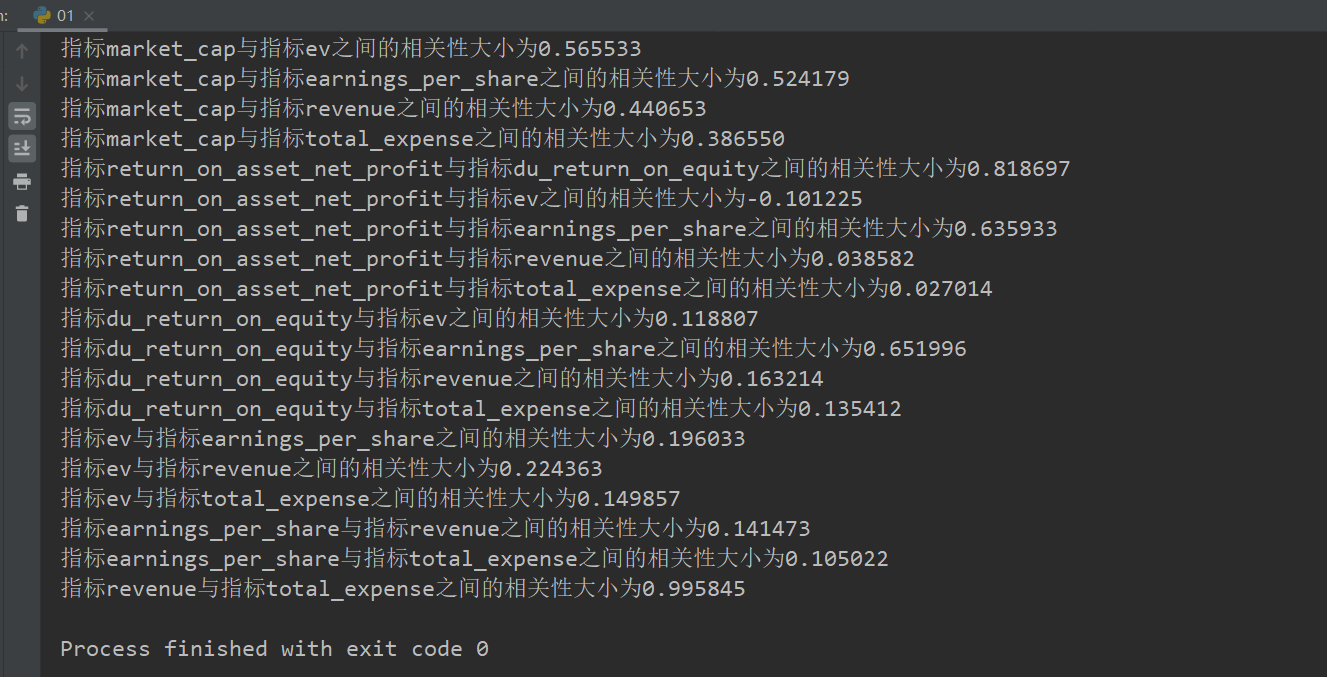
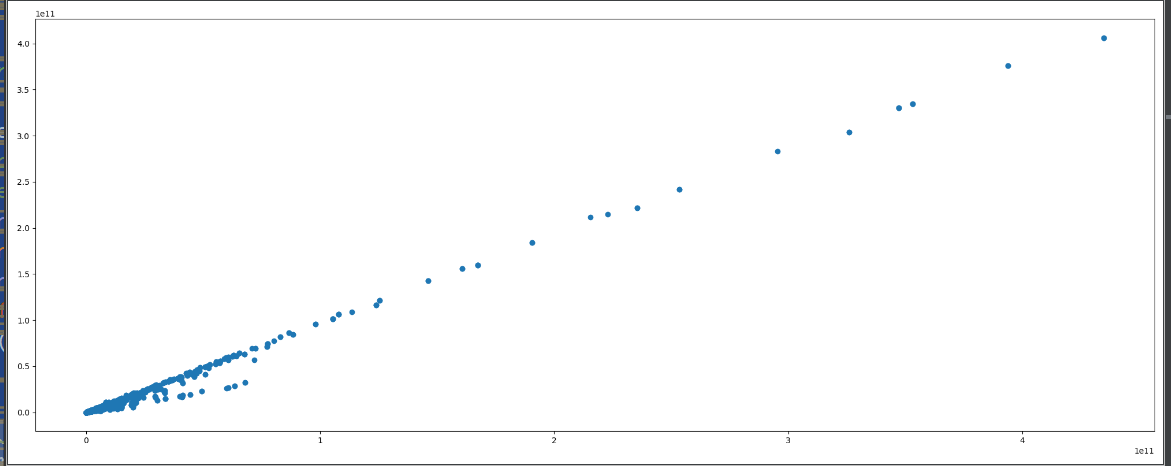
#相关系数计算 def pearsonr_demo(): """ 相关系数计算 :return: None """ data = pd.read_csv("factor_returns.csv") factor = [‘pe_ratio‘, ‘pb_ratio‘, ‘market_cap‘, ‘return_on_asset_net_profit‘, ‘du_return_on_equity‘, ‘ev‘, ‘earnings_per_share‘, ‘revenue‘, ‘total_expense‘] for i in range(len(factor)): for j in range(i, len(factor) - 1): print("指标%s与指标%s之间的相关性大小为%f" % (factor[i], factor[j + 1], pearsonr(data[factor[i]], data[factor[j + 1]])[0])) plt.figure(figsize=(20, 8), dpi=100) plt.scatter(data[‘revenue‘], data[‘total_expense‘]) plt.show() return None if __name__=="__main__": pearsonr_demo()
定义:高维数据转化为低维数据的过程,在此过程中可能会舍弃原有数据、创造新的变量
作用:是数据维数压缩,尽可能降低原数据的维数(复杂度),损失少量信息。
对于信息一词,在决策树中会进行介绍

sklearn.decomposition.PCA(n_components=None)
将数据分解为较低维数空间
n_components:
小数:表示保留百分之多少的信息
整数:减少到多少特征
PCA.fit_transform(X) X:numpy array格式的数据[n_samples,n_features]
返回值:转换后指定维度的array
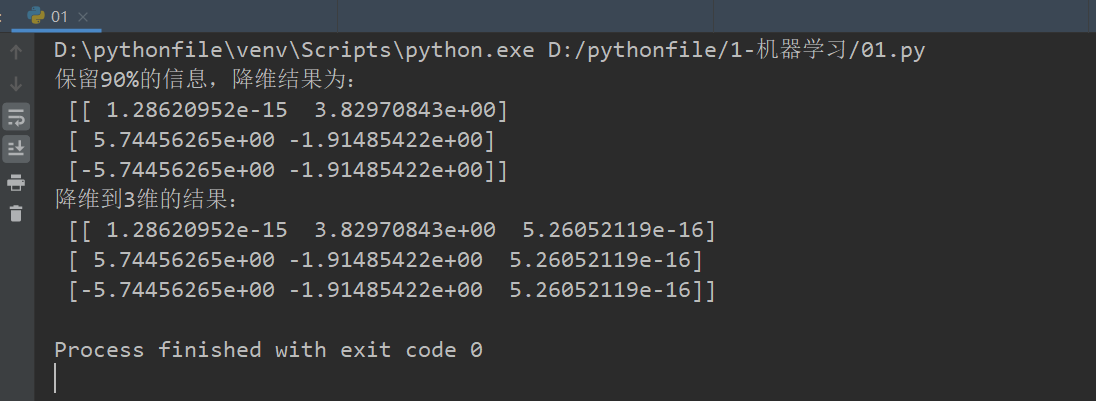
#对数据进行PCA降维 def pca_demo(): """ 对数据进行PCA降维 :return: None """ data = [[2,8,4,5], [6,3,0,8], [5,4,9,1]] # 1、实例化PCA, 小数——保留多少信息。 transfer = PCA(n_components=0.9) # 2、调用fit_transform data1 = transfer.fit_transform(data) print("保留90%的信息,降维结果为:\n", data1) # 1、实例化PCA, 整数——指定降维到的维数 transfer2 = PCA(n_components=3) # 2、调用fit_transform data2 = transfer2.fit_transform(data) print("降维到3维的结果:\n", data2) return None if __name__=="__main__": pca_demo()
机器学习进度02(数据预处理、降维、低方差特征、相关系数、主成分分析)
原文:https://www.cnblogs.com/dazhi151/p/14299810.html