ElasticStack数据流
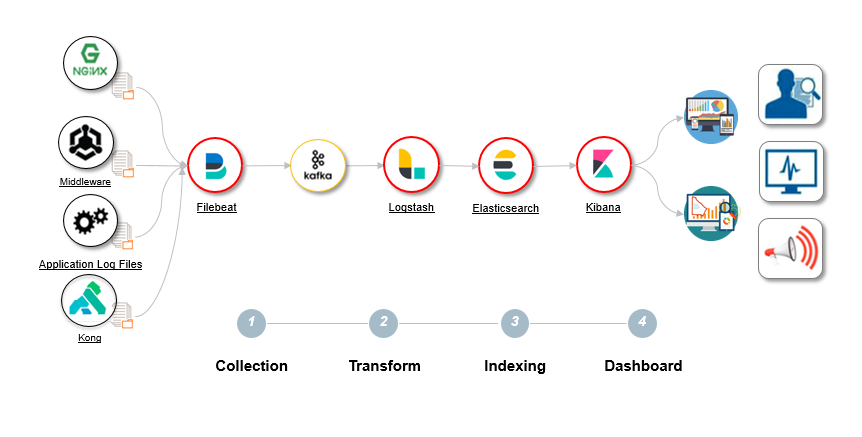
ElasticSearch
建立索引和类型
- 在Elasticsearch集群中,节点是对等的,节点间会通过自己的一些规则选取集群的Master,Master节点会负责集群状态信息的改变,并同步给其他节点。
- 建立索引和类型的请求先发送到Master节点,Master建立完索引后,将集群状态同步至Slave节点。
- 只有建立索引和类型需要经过Master节点,数据的写入有一个简单的Routing规则,可以Route到集群中的任意节点,所以数据写入压力是分散在整个集群的。
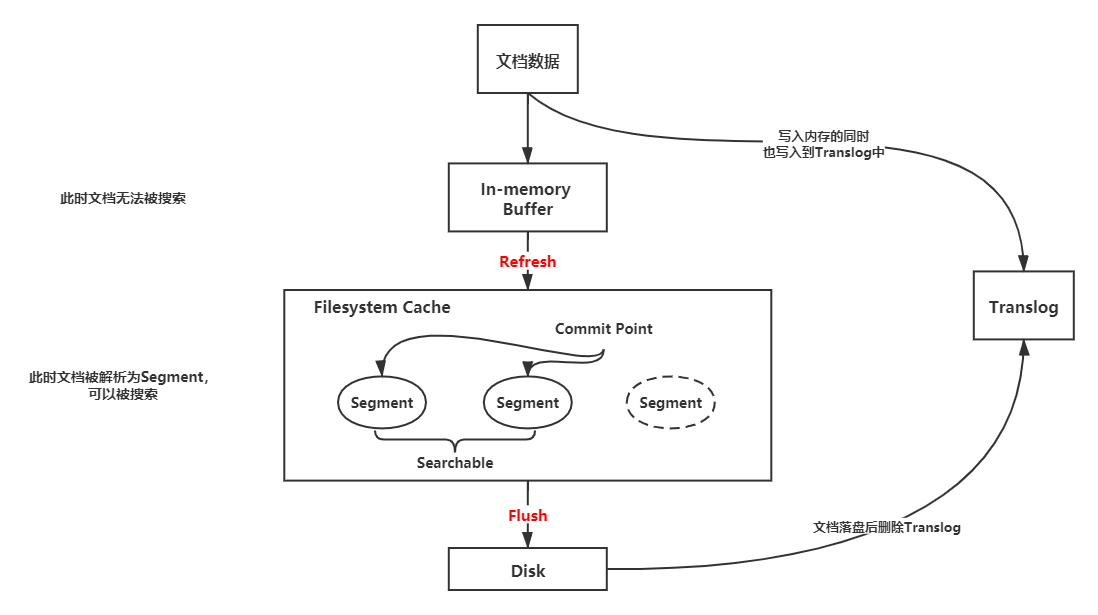
分片内文档写入流程
-
In-memory Buffer
在主分片节点上,文档会先被写入到内存(In-memory Buffer)中,此时数据还不能被搜索到。
-
Refresh
经过一段时间(refresh_interval)或者内存缓冲满了,Elasticsearch会将内存中的文档Refresh到文件系统缓存(Filesystem Cache)中,并清除内存中的对应文档。
-
Filesystem Cache
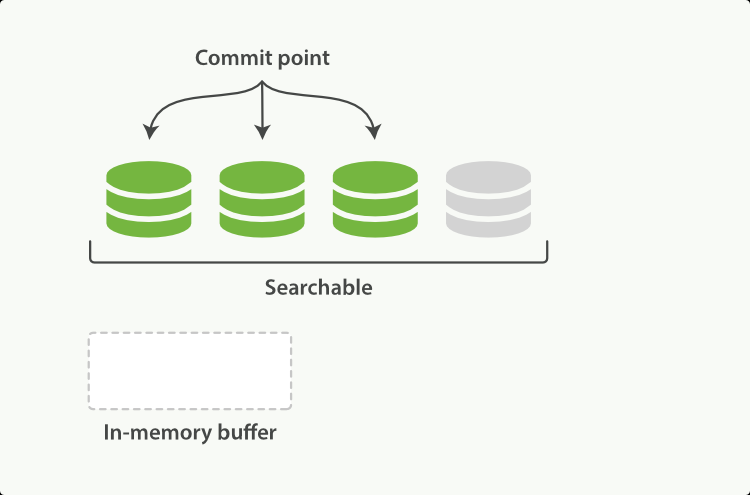
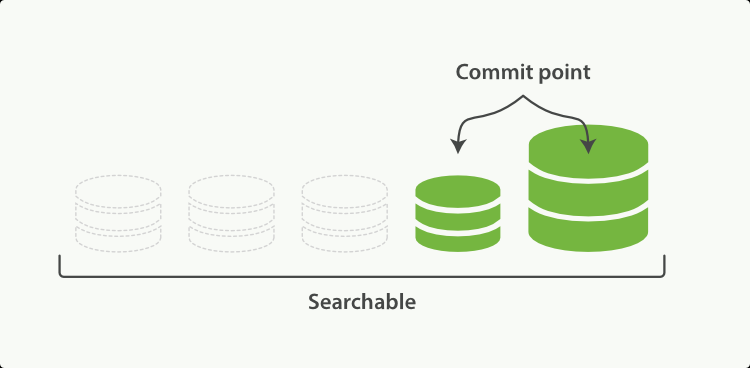
文档在文件系统缓存中被解析为Lucene的底层文件Segment中,同时建立倒排索引。这个时候文档是可以被搜索到的,因此减少了后续写入磁盘的大量时间,体现了Elasticsearch搜索的实时性(下图中的绿色和灰色图标分别代表已写入磁盘和未写入磁盘的文档)。
-
Segment
Lucene把每次生成的倒排索引,叫做一个段(Segment),它无法被修改,只能被合并和删除。另外使用一个Commit文件,记录索引内所有的Segment。由于每次打开一个Segment就会消耗一个文件句柄,随着Segment越来越多,将导致查询性能越来越差。这时,ElasticSearch后台会有一个单独线程专门合并Segment,将零碎的小的Segment合并成一个大的Segment。
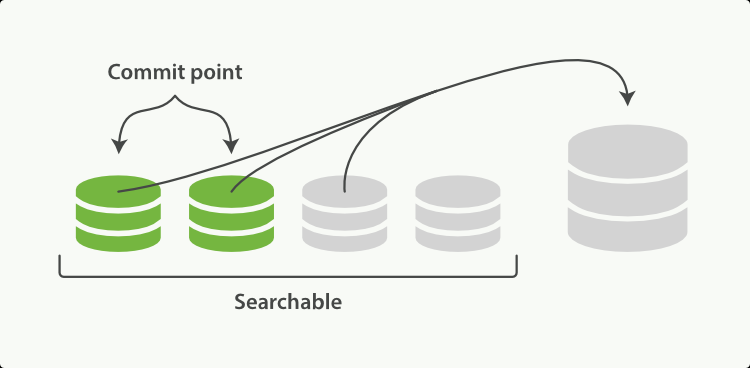
-
Flush
将Segment写入磁盘中,更新Commit文件并删除文档对应的Translog文件。
-
Translog
Elasticsearch在把数据写入到Index Buffer的同时,其实还另外记录了一个Translog日志。它是以顺序写文件的形式写入到磁盘中的,速度较快。如果发生异常,Elasticsearch会从Commit位置开始,恢复整个Translog文件中的记录,保证数据一致性。
多个分片的文档写入
确定文档存储位置
计算方式:
shard = hash(routing) % number_of_primary_shards
每个文档都有一个routing参数,默认情况下就使用其 _id 值。将其 _id 值计算哈希后,对索引的主分片数取余,就得到了文档实际应该存储到的分片。因此索引的主分片数不可以随意修改,一旦主分片数改变,所有文档的存储位置计算结果都会发生改变,索引数据就完全不可读了。
同步副本
.jpg)
- 客户端请求发送给Node 1节点,注意图中Node 1是Master节点,实际完全可以不是;
- Node 1用文档的 _id 取余计算得到应该将数据存储到shard 0上。通过Cluster State信息发现shard 0的主分片已经分配到了Node 3上。Node 1转发请求数据给Node 3;
- Node 3完成请求数据的索引过程,存入主分片 0。然后并行转发数据给分配有shard 0的副本分片的Node 1和Node 2。当收到任一节点汇报副本分片数据写入成功,Node 3即返回给初始的接收节点 Node 1,宣布数据写入成功。Node 1返回成功响应给客户端;
- 当集群中某个节点宕机,该节点上所有分片中的数据全部丢失(既有主分片,又有副分片)。丢失的副分片对数据的完整性没有影响,丢失的主分片在其他节点上的副分片会被选举成主分片;所以整个索引的数据完整性没有被破坏。
注:图中P代表主分片(Primary Shard),R代表副本(Replica Shard)。
根据_id查询文档
GET /[index]/_doc/[_id]
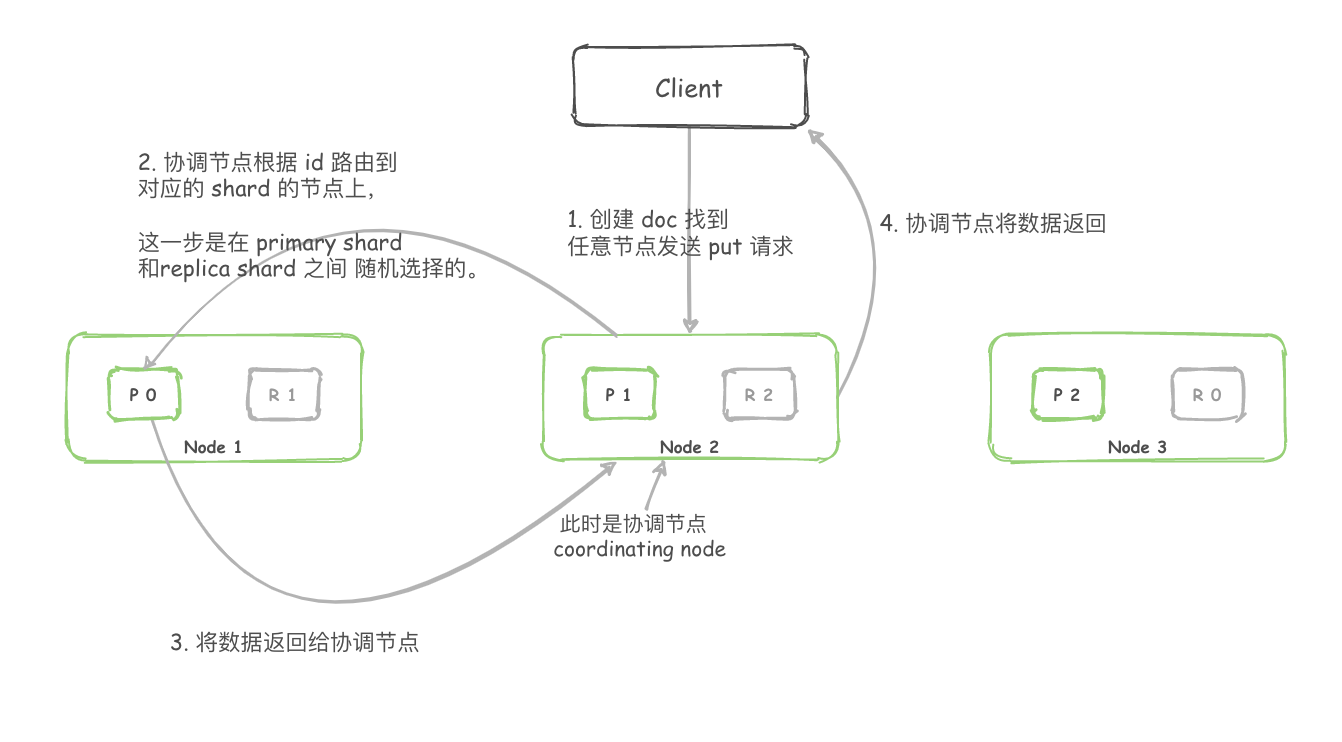
- Elasticsearch集群中的任意节点都可以作为协调(Coordinating)节点接受请求,每个节点都知道集群中任一文档位置;
- 协调节点对文档的_id进行路由,从而判断该数据在哪个Shard,然后将请求转发给对应的节点,此时会使用随机轮询算法,在Primary Shard和Replica Shard中随机选择一个,从而对请求负载均衡;
- 处理请求的节点返回文档给协调节点;
- 协调节点返回文档给客户端。
根据字段值检索数据
GET /[index]/_search?q=[field]: [value]
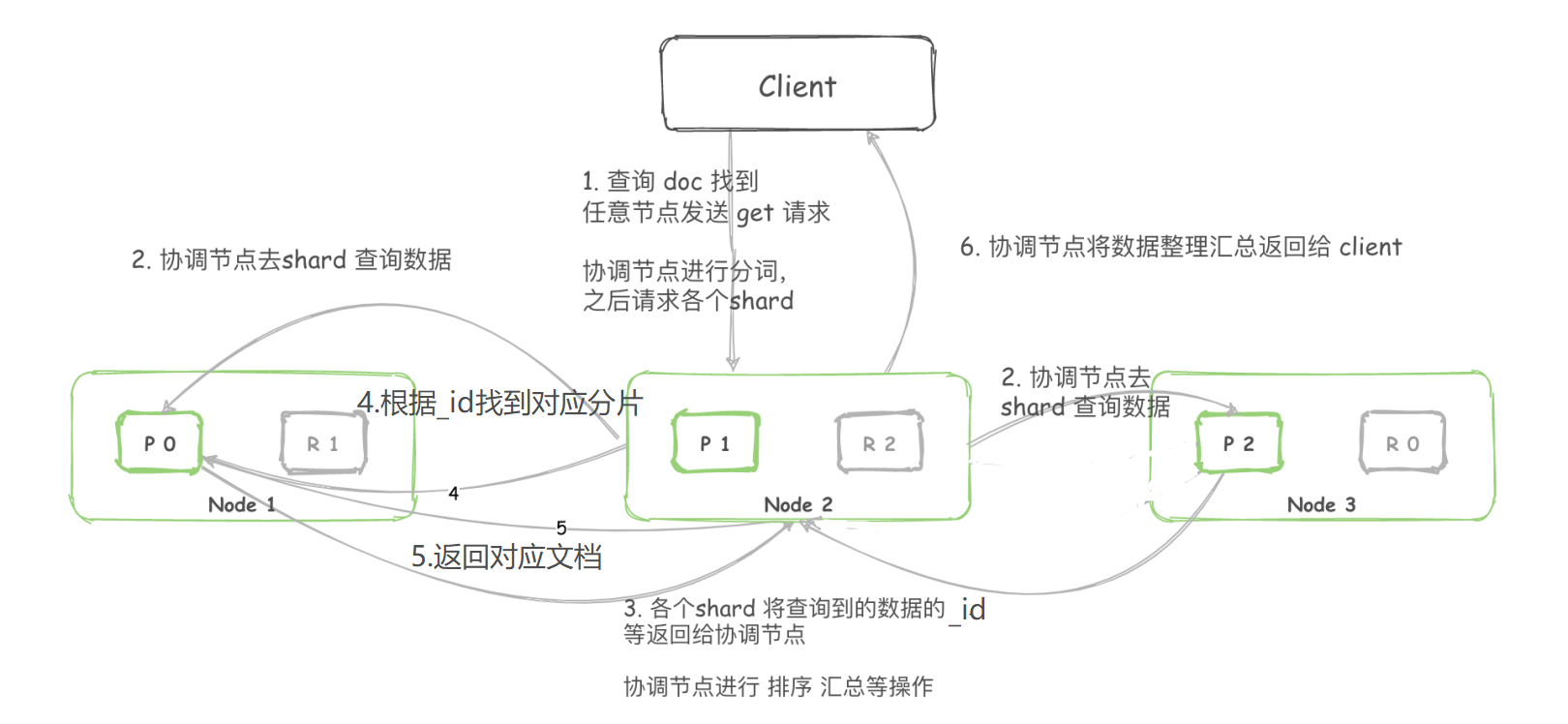
- Elasticsearch集群中的任意节点都可以作为协调(Coordinating)节点接受请求,每个节点都知道集群中任一文档位置;
- 协调节点进行分词等操作后,向所有的shard节点发送检索请求;
- ElasticSearch已建立字段的倒排索引,即可通过字段值检索到所在文档的_id。随后Shard将满足条件的数据(_id、排序字段等)信息返回给协调节点;
- 协调节点将数据重新进行排序,获取到真正需要返回的文档的_id。协调节点再次向对应的Shard发起请求(此时已经有_id 了,可以直接定位到对应的Shard);
- Shard将_id对应的文档的完整内容返回给协调节点;
- 协调节点获取到全部检索结果,返回给客户端。
上述流程和根据_id查询文档相比,只是多了一个从倒排索引中根据字段值寻找文档_id的过程,其中的4~6步完全相同。
ElasticSearch架构原理
原文:https://www.cnblogs.com/koktlzz/p/14303609.html