之前我们讨论了使用ROC曲线来描述分类器的优势,有人说它描述了“随机猜测类别的策略”,让我们回到ROC曲线来说明。考虑一个非常简单的数据集,其中包含10个观测值(不可线性分离)
在这里我们可以检查一下,确实是不可分离的
plot(x1,x2,col=c("red","blue")[1+y],pch=19)
考虑逻辑回归
reg = glm(y~x1+x2,data=df,family=binomial(link = "logit"))
我们可以使用我们自己的roc函数
或R包
performance(prediction(S,Y),"tpr","fpr")我们可以在这里同时绘制两个
因此,我们的代码在这里可以正常工作。让我们考虑一下对角线。第一个是:每个人都有相同的概率(例如50%)
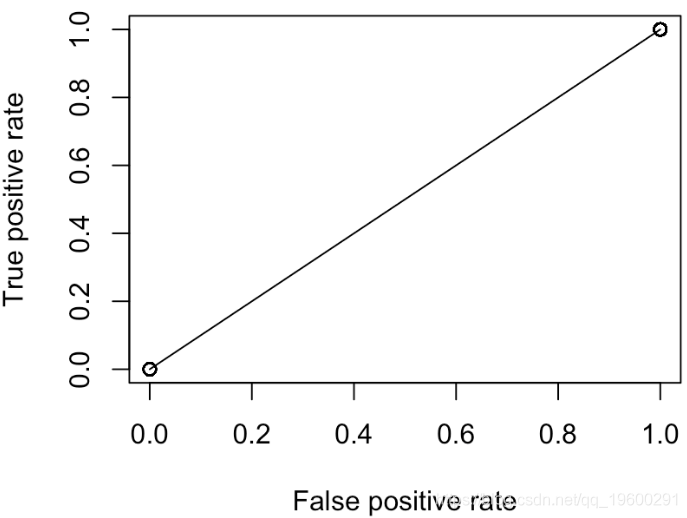
但是,我们这里只有两点:(0,0)和(1,1)。实际上,无论我们选择何种概率,都是这种情况
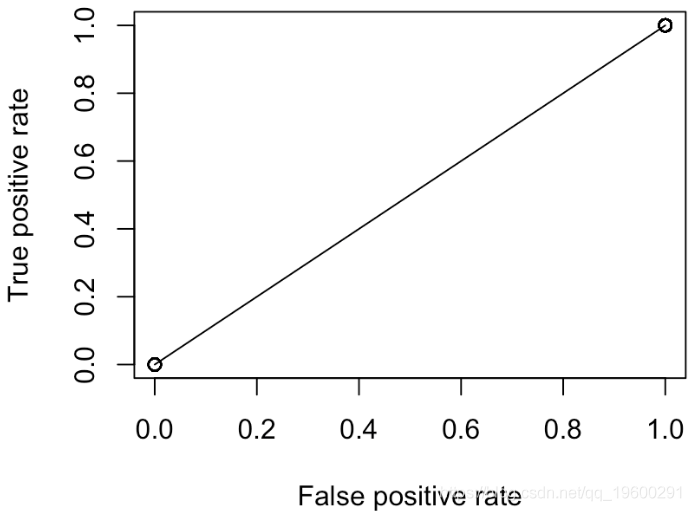
我们可以尝试另一种策略,例如“通过扔无偏硬币进行预测”。我们得到
我们还可以尝试“随机分类器”,在其中我们随机选择分数
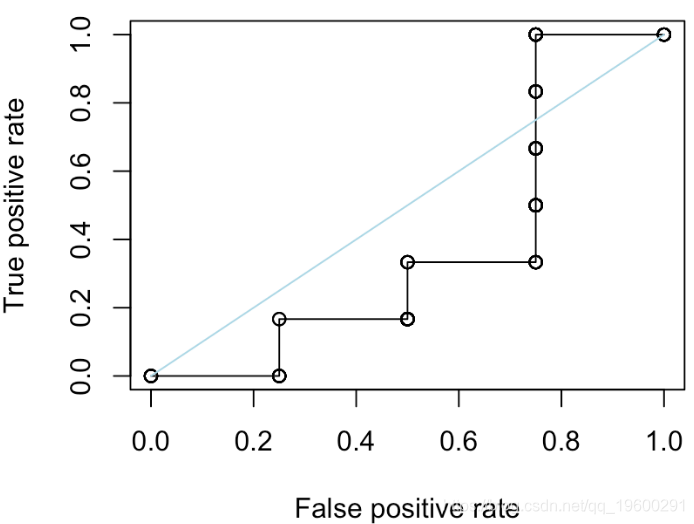
更进一步。我们考虑另一个函数来绘制ROC曲线
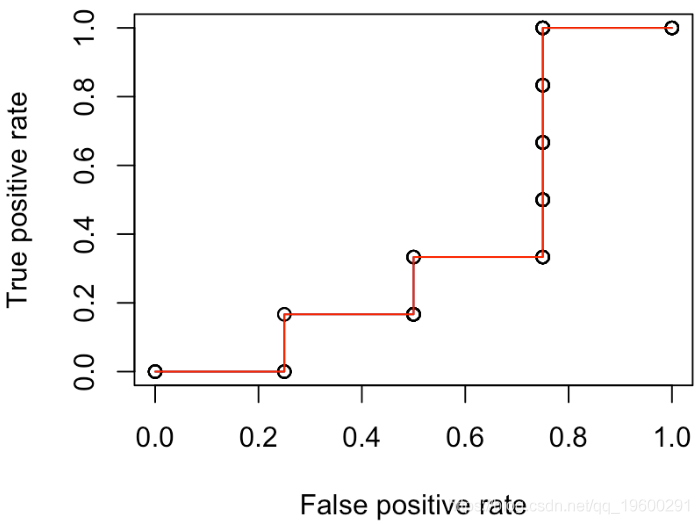
但是现在考虑随机选择的策略
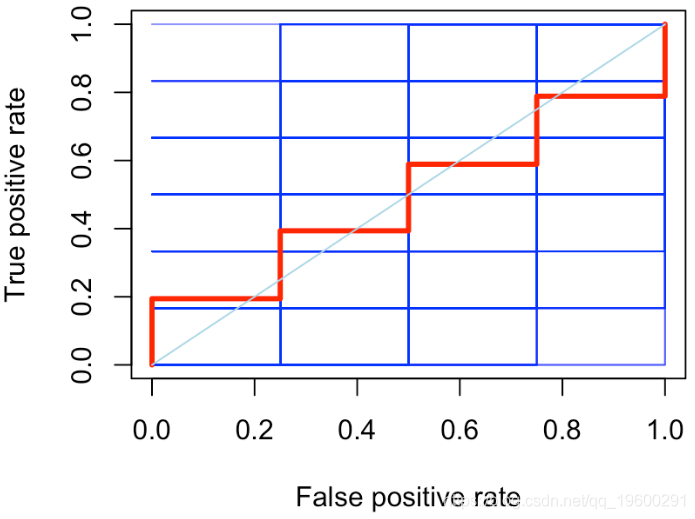
红线是所有随机分类器的平均值。它不是一条直线,我们观察到它在对角线周围的波动。
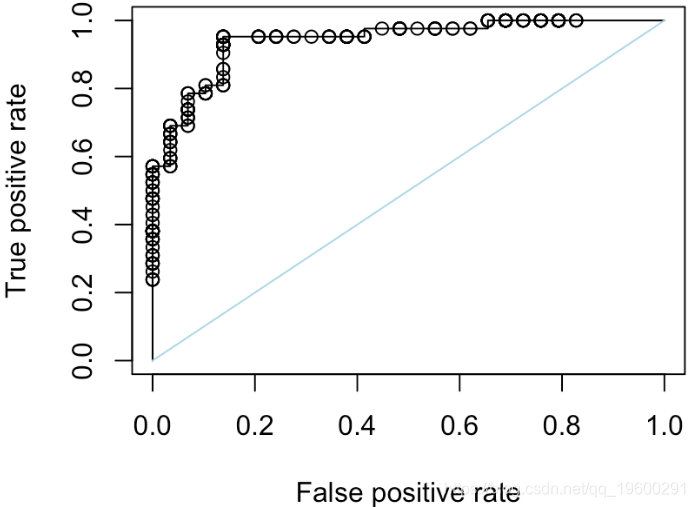
这是一个“随机分类器”,我们在单位区间上随机绘制分数
如果我们重复500次,我们可以获得
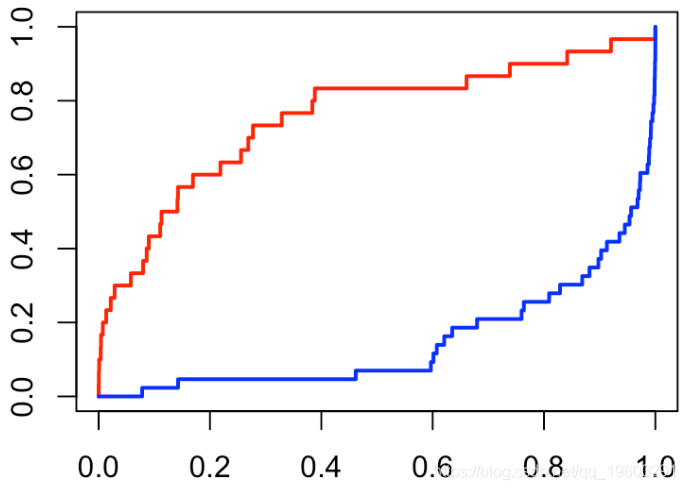
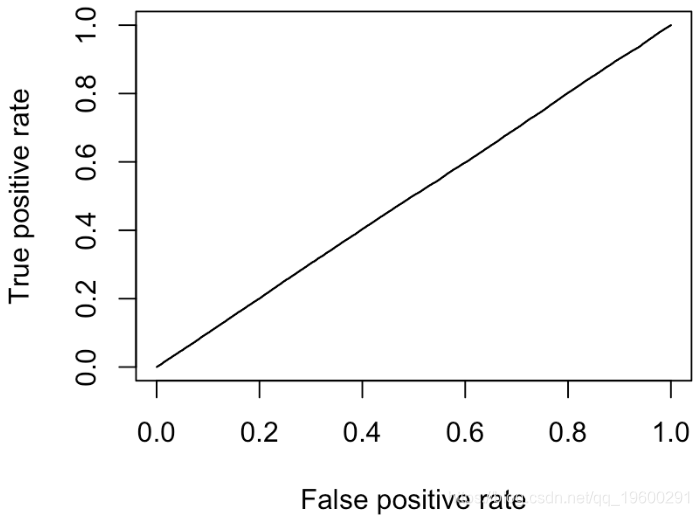
因此,当我在单位区间上随机绘制分数时,就会得到对角线的结果。给定Y,我们可以绘制分数的两个经验累积分布函数
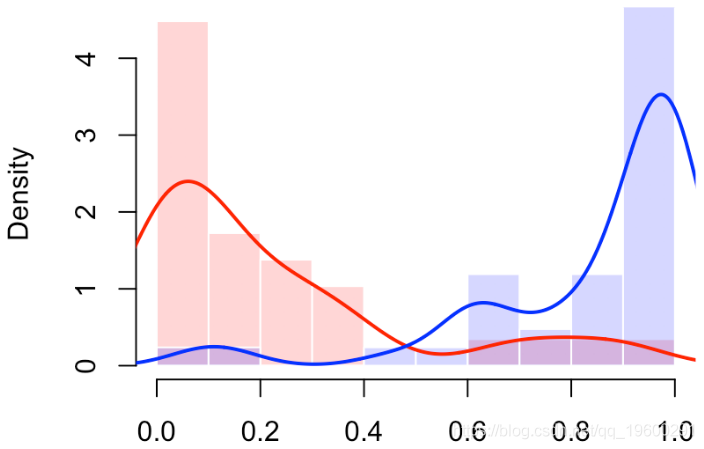
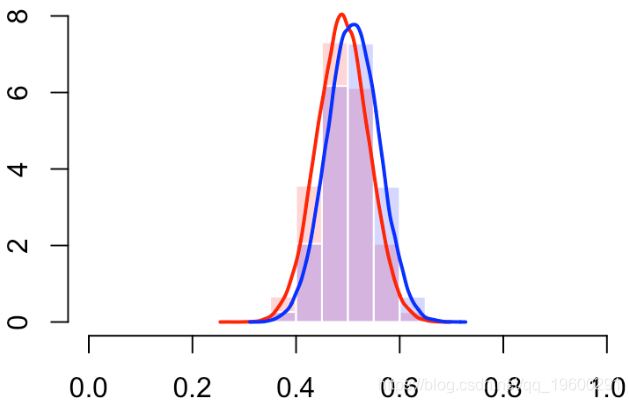
我们还可以使用直方图(或密度估计值)查看分数的分布
我们确实有一个“完美的分类器”(曲线靠近左上角)
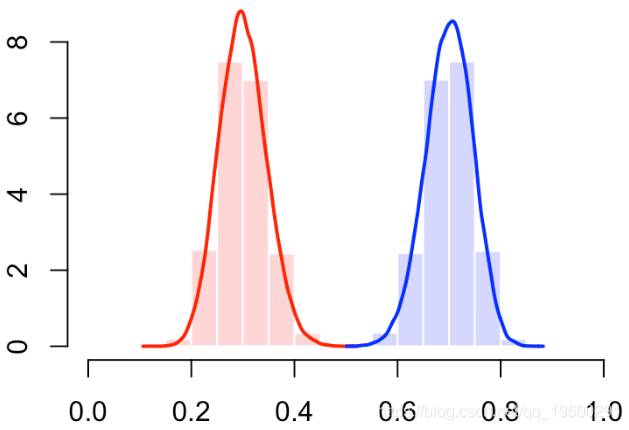
有错误。那应该是下面的情况
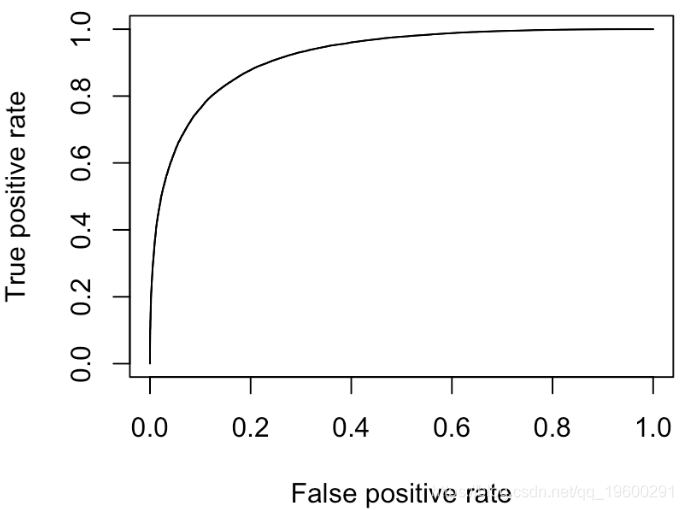
在10%的情况下,我们可能会分类错误
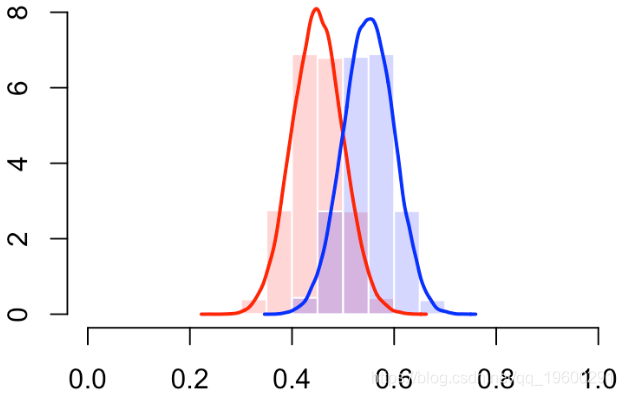
更多的错误分类
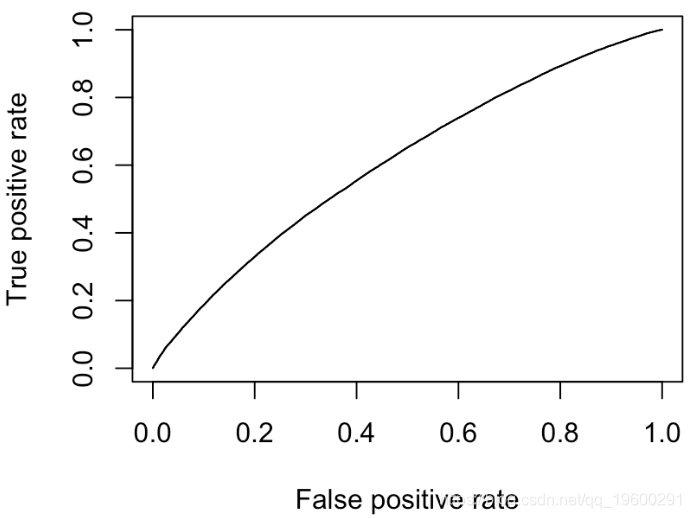
最终我们有对角线

最受欢迎的见解
3.matlab中的偏最小二乘回归(PLSR)和主成分回归(PCR)
5.R语言回归中的Hosmer-Lemeshow拟合优度检验
6.r语言中对LASSO回归,Ridge岭回归和Elastic Net模型实现
9.R语言如何在生存分析与Cox回归中计算IDI,NRI指标
原文:https://www.cnblogs.com/tecdat/p/14311196.html