| 类型 | 描述示例 |
|---|---|
| NULL | 表示空值或者不存在的字段,{"x" : null} |
| Boolean | 布尔型有 true 和 false,{"x" : true} |
| Number | 数值:客户端默认使用 64 位浮点型数值。{"x" : 3.14} 或 {"x" : 3}。对于整型值,包括 NumberInt(4 字节符号整数)或 NumberLong(8 字节符号整数),用户可以指定数值类型,{"x" : NumberInt("3")} |
| String | 字符串:BSON 字符串是 UTF-8,{"x" : "中文"} |
| Regular Expression | 正则表达式:语法与 JavaScript 的正则表达式相同,{"x" : /[cba]/} |
| Array | 数组:使用“[]”表示,{"x" : ["a", "b", "c"]} |
| Object | 内嵌文档:文档的值是嵌套文档,{"a" : {"b" : 3}} |
| ObjectId | 对象 id:对象 id 是一个 12 字节的字符串,是文档的唯一标识,{"x" : objectId()} |
| BinaryData | 二进制数据:二进制数据是一个任意字节的字符串。它不能直接在 Shell 中使用。如果要将非 UTF-8 字符保存到数据库中,二进制数据是唯一的方式 |
| JavaScript | 代码:查询和文档中可以包括任何 JavaScript 代码,{"x" : function(){/.../}} |
| Data | 日期:{"x" : new Date()} |
| Timestamp | 时间戳:var a = new Timestamp() |
use dbName // 切换或创建数据库
show dbs // 查看当前数据库
db.stats() // 查看当前数据库的信息
db.dropDatabase() // 删除当前数据库
db.getCollectionNames() // 查询当前数据库下所有集合名称
// 创建集合
db.createCollection(name, options)
db.createCollection("mySet", {capped:true,size:6142800, max :10000 })
// 重命名
db.coll.renameCollection("myColl2")
// 删除
db.myColl2.drop()
创建集合的选项
| 参数 | 类型 | 描述 |
|---|---|---|
| capped | Boolean | (可选)如果为 true,则启用封闭的集合。上限集合是固定大小的集合,它在达到其最大时自动覆盖其最旧的条目。如果指定 true,则还需要指定 size 参数 |
| size | 数字 | (可选)指定上限集合的最大大小(以字节为单位)。如果 capped 为 true,那么还需要指定次字段的值 |
| max | 数字 | (可选)指定上限集合中允许的最大文档数 |
// 插入,集合不存在时自动创建
insertOne()
insertMany()
db.myColl.insert(
{"name":"value"}/[{"name1":"value1"}, {"name2":"value2"}]
{
writenConcern:<document>, // 自定义写出错的级别
ordered:<boolean> // 为 true 有序插入,一个出错终止插入,默认
// 为 false 无序插入,出错后继续
}
)
>var result = db.users.findOne({"name":"Tom Benzamin"},{"address_ids":1})
>var addresses = db.address.find({"_id":{"$in":result["address_ids"]}})
{
"_id":ObjectId("52ffc33cd85242f436000001"),
"contact": "987654321",
"dob": "01-01-1991",
"name": "Tom Benzamin",
"address_ids": [
ObjectId("52ffc4a5d85242602e000000"),
ObjectId("52ffc4a5d85242602e000001")
]
}
db.collection.update(
<query>, // 参数设置查询条件
<update>, // 更新操作符
{
upsert, // 为true,在不存在update记录时插入新文档
multi, // 为false,只更新找到的的第一条记录,否则更新全部
writeConcern, // 出错级别
collation // 指定语言
}
)
db.test.update( // 更新{item: "card", qty: 36}
{item:"card"},
{$set: {qty: 35}}
)
db.test.save(obj) // 已存在相同"_id"记录时覆盖,用insert会报错
// 只更新第一条记录:
db.col.update( { "count" : { $gt : 1 } } , { $set : { "test2" : "OK"} } );
// 全部更新:
db.col.update( { "count" : { $gt : 3 } } , { $set : { "test2" : "OK"} },false,true );
// 只添加第一条:
db.col.update( { "count" : { $gt : 4 } } , { $set : { "test5" : "OK"} },true,false );
// 全部添加进去:
db.col.update( { "count" : { $gt : 5 } } , { $set : { "test5" : "OK"} },true,true );
// 全部更新:
db.col.update( { "count" : { $gt : 15 } } , { $inc : { "count" : 1} },false,true );
// 只更新第一条记录:
db.col.update( { "count" : { $gt : 10 } } , { $inc : { "count" : 1} },false,false );
db.collection.remove(
<query>, // 删除的过滤条件
{
justOne: <boolean>, // 默认false
writeConcern: <document>
}
)
db.test.remove({"title": "MongoDB"})
db.repairDatabase() // 使用remove后用此命令才能释放磁盘
db.test.deleteOne({"tetle": "A"})
db.test.deleteMany({"title": "B"})
db.collection.find(query, projection)
db.collection.findOne().pretty()
// 顺序是 sort -> skip -> limit
db.test.find({tags:[‘MongoDB‘, ‘NoSQL‘, ‘database‘]}).limit(3) // 限制
db.test.find({tags: {$size: 3}}).skip(1) // 略过第一个
db.test.find({name: "value3"}).sort({"price": 1}) // 1是升序 -1降序
db.test.find({tags: {$regex: "MongoDB"}}) // 正则
db.test.find({"title" : {$type : ‘string‘}}) // 获取 title 为 String 的数据
查询条件
| 操作符 | 格式 | 实例 | 与 RDBMS where 语句比较 |
|---|---|---|---|
| 等于(=) | { |
db.test.find( {price : 24} ) | where price = 24 |
| 大于(>) | { |
db.test.find( {price : {$gt : 24}} ) | where price > 24 |
| 小于(<) | { |
db.test.find( {price : {$lt : 24}} ) | where price < 24 |
| 大于等于(>=) | { |
db.test.find( {price : {$gte : 24}} ) | where price >= 24 |
| 小于等于(<=) | { |
db.test.find( {price : {$lte : 24}} ) | where price <= 24 |
| 不等于(!=) | { |
db.test.find( {price : {$ne : 24}} ) | where price != 24 |
| 与(and) | {key01 : value01, key02 : value02, ...} | db.test.find( {name : "《MongoDB 入门教程》", price : 24} ) | where name = "《MongoDB 入门教程》" and price = 24 |
| 或(or) | {$or : [{key01 : value01}, {key02 : value02}, ...]} | db.test.find( {$or:[{name : "《MongoDB 入门教程》"},{price : 24}]} ) | where name = "《MongoDB 入门教程》" or price = 24 |
游标
| 方法名 | 作用 |
|---|---|
| hasNext | 判断是否有更多的文档 |
| next | 用来获取下一条文档 |
| toArray | 将查询结构放到数组中 |
| count | 查询的结果为文档的总数量 |
| limit | 限制查询结果返回数量 |
| skip | 跳过指定数目的文档 |
| sort | 对查询结果进行排序 |
| objsLeftlnBatch | 查看当前批次剩余的未被迭代的文档数量 |
| addOption | 为游标设置辅助选项,修改游标的默认行为 |
| hint | 为查询强制使用指定索引 |
| explain | 用于获取查询执行过程报告 |
| snapshot | 对查询结果使用快照 |
>var cursor = db.test.find()
>while (cursor.hasNext()){
var doc = cursor.next();
print(doc.name); //把每一条数据都单独拿出来进行逐行的控制
print(doc); //将游标数据取出来后,其实每行数据返回的都是一个[object BSON]型的内容
printjson(doc); //将游标获取的集合以JSON的形式显示
}
db.col.createlndex ( { key: 1 } ) //1 为升序,-1 为降序
db.col.find({score:1034}).explain() // 可查看查询过程
db.col.createIndex ({ <key1> : <type>, <key2> : <type2>, ...}) // 复合索引
db.col.getIndexes() // 查看索引
db.col.totalIndexSize()
db.col.dropIndex({"score": 1}) // 删除score的升序索引
db.col.dropIndexes() // 删除索引
select cust_id as _id, sum(amount) as total
from orders
where status like "%A%"
group by cust_id;
//类似
db.collection.aggregate([
{$match : {< query >},}
{$group: {< fieldl >: < field2 >}}
])
select by_user as _id, count(*) as num_tutorial
from mycol
group by by_user;
//类似
db.mycol.aggregate([
{$group : {_id : "$by_user", num_tutorial : {$sum : 1}}}
])
| 表达式 | 描述 | 实例 |
|---|---|---|
| $sum | 计算总和。 | db.mycol.aggregate([{\(group : {_id : "\)by_user", num_tutorial : {\(sum : "\)likes"}}}]) |
| $avg | 计算平均值 | db.mycol.aggregate([{\(group : {_id : "\)by_user", num_tutorial : {\(avg : "\)likes"}}}]) |
| $min | 获取集合中所有文档对应值得最小值。 | db.mycol.aggregate([{\(group : {_id : "\)by_user", num_tutorial : {\(min : "\)likes"}}}]) |
| $max | 获取集合中所有文档对应值得最大值。 | db.mycol.aggregate([{\(group : {_id : "\)by_user", num_tutorial : {\(max : "\)likes"}}}]) |
| $push | 在结果文档中插入值到一个数组中。 | db.mycol.aggregate([{\(group : {_id : "\)by_user", url : {\(push: "\)url"}}}]) |
| $addToSet | 在结果文档中插入值到一个数组中,但不创建副本。 | db.mycol.aggregate([{\(group : {_id : "\)by_user", url : {\(addToSet : "\)url"}}}]) |
| $first | 根据资源文档的排序获取第一个文档数据。 | db.mycol.aggregate([{\(group : {_id : "\)by_user", first_url : {\(first : "\)url"}}}]) |
| $last | 根据资源文档的排序获取最后一个文档数据 | db.mycol.aggregate([{\(group : {_id : "\)by_user", last_url : {\(last : "\)url"}}}]) |
db.collection.mapReduce(
function() { emit(key,value); },
function(key, values) { return reduceFunction }
{ query: document, out: collection }
)
mongodump -h dbhost -d dbname -o dbdirectory
mongorestore -h <hostname><:port> -d dbname <path>
mongostat
mongotop
建立一个主节点和一个或多个从节点,一个主节点提供所有的增、删、改、查,从节点不提供服务,可通过设置使从节点提供查询服务。
另外,每个从节点要知道主节点的地址,主节点记录在其上的所有操作,从节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作,从而保证从节点的数据与主节点一致。
在主从复制的集群中,当主节点出现故障时,只能人工介入,指定新的主节点,从节点不会自动升级为主节点。同时,在这段时间内,该集群架构只能处于只读状态。
可以说,MongoDB 的副本集是自带故障转移功能的主从复制。区别在于:主节点发生故障时,副本集可以自动投票,并引导其余从节点连接新节点,过程相对透明。
另外,从节点会定时轮询读取 oplog 日志,根据日志内容同步更新自身的数据,保持与主节点一致
副本集中的各节点会通过心跳信息来检测各自的健康状况,当主节点出现故障时,多个从节点会触发一次新的选举操作,并选举其中一个作为新的主节点。为了保证选举票数不同,副本集的节点数保持为奇数。
# 主机上运行
mongod --port 27017 --dbpath "D:\set up\mongodb\data" --replSet rs0
rs.add(HOST_NAME:PORT)
db.isMaster() # 判断是否为主节点
副本集可以解决主节点发生故障导致数据丢失或不可用的问题,但遇到需要存储海量数据的情况时,副本集机制就束手无策了。副本集中的一台机器可能不足以存储数据,或者说集群不足以提供可接受的读写吞吐量。这就需要用到 MongoDB 的分片(Sharding)技术,这也是 MongoDB 的另外一种集群部署模式。
分片是指将数据拆分并分散存放在不同机器上的过程。有时也用分区来表示这个概念。将数据分散到不同的机器上,不需要功能强大的大型计算机就可以存储更多的数据,处理更大的负载。
MongoDB 支持自动分片,可以使数据库架构对应用程序不可见,简化系统管理。对应用程序而言,就如同始终在使用一个单机的 MongoDB 服务器一样。
MongoDB 的分片机制允许创建一个包含许多台机器的集群,将数据子集分散在集群中,每个分片维护着一个数据集合的子集。与副本集相比,使用集群架构可以使应用程序具有更强大的数据处理能力。
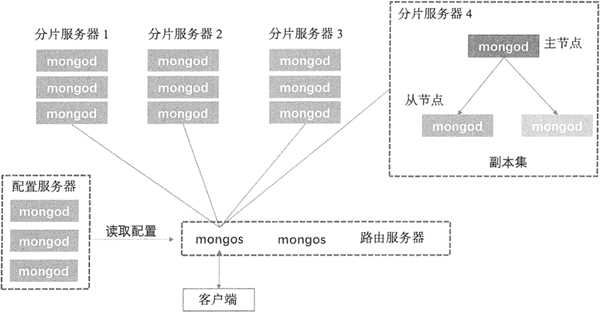
构建一个 MongoDB 的分片集群,需要三个重要的组件,分别是分片服务器(Shard Server)、配置服务器(Config Server)和路由服务器(Route Server)。
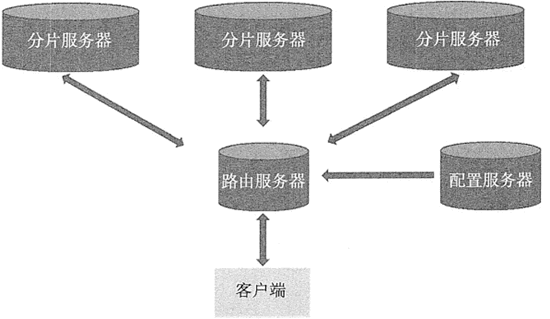
每个 Shard Server 都是一个 mongod 数据库实例,用于存储实际的数据块。整个数据库集合分成多个块存储在不同的 Shard Server 中。
在实际生产中,一个 Shard Server 可由几台机器组成一个副本集来承担,防止因主节点单点故障导致整个系统崩溃。
这是独立的一个 mongod 进程,保存集群和分片的元数据,在集群启动最开始时建立,保存各个分片包含数据的信息。
这是独立的一个 mongos 进程,Route Server 在集群中可作为路由使用,客户端由此接入,让整个集群看起来像是一个单一的数据库,提供客户端应用程序和分片集群之间的接口。
Route Server 本身不保存数据,启动时从 Config Server 加载集群信息到缓存中,并将客户端的请求路由给每个 Shard Server,在各 Shard Server 返回结果后进行聚合并返回客户端。
import com.mongodb.MongoClient;
import com.mongodb.client.MongoDatabase;
import com.mongodb.dient.MongoCollection;
public class App {
public static void main(String[] args) {
try {
//连接MongoDB服务器,端口号为27017
MongoClient mongoClient = new MongoClient("localhost", 27017);
//连接数据库
MongoDatabase mDatabase = mongoClient.getDatabase("test"); //test可选
System.out.printin("Connect to database successfully!");
System.out.printIn("MongoDatabase inof is : "+mDatabase.getName());
} catch (Exception e) {
System.err.printIn(e.getClass().getName() + ": " + e.getMessage());
}
}
}
// 切换集合
MongoCollection collection = database.getCollection("myTestCollection");
// 定义文档
Document document = new Document("name", "value")
.append("name1", "value1")
.append("number", 30);
// 插入文档
collection.insertOne(document);
List<Document> documents = new ArrayList<Document>();
documents.add(document1);
collection.insertMany(documents);
// 删除文档
collection.deleteOne(document);
collection.deleteMany(new Document ("likes", 30));
// 更新数据
collection.updataOne (eq ("likes", 30), new Document ("$set", new Document ("likes", 50)));
// 查询数据
import com.mongodb.client.MongoCursor;
document Doc = (Document)collection.find(eq("likes", 30)).iterator();
MongoCursor<Document> cursor =collection.find().iterator();
try{
while (cursor.hasNext()){
System.out.printin(cursor.next().toJson());
}
} finally{
Cursor.close();
}
// 删除数据库或集合
mDatabase.drop();
collection.drop();
// 关闭连接
mongoClient.close();
import pymongo
Client = MongoClient(host= ‘127.0.0.1‘, port=27017)
Client=MongoClient(host=‘10.90.9.101: 27018, 10.90.9.102: 27018,10.90.9.103: 27018‘) # 连接集群
# 获取所有集合
db.list_collection_names()
db = client.myDB # 或 client["myDB"]
coll = db.test_collection # db["test-collection"]
# 插入文档
coll = db.get_collection("myCollection")
post_data = {
‘item‘ : ‘book1‘,
‘qty‘ : 18 }
result = coll.insert_one(post_data)
# 插入多个文档
result = coll.insert_many([post_1, post_2, post_3])
# 查询
find_post = coll.find_one({‘item‘ : ‘book‘})
find_posts = coll.find({‘item‘ : ‘book1‘})
doc = client.db.collection.find_one({‘_id‘:‘‘})
# counting
c = colls.count_documents({})
# 索引
result = db.profiles.create_index([(‘user_id‘, pymongo.ASCENDING)], unique=True)
# 更新
condition = {‘item‘ : ‘book‘}
pty{‘$set‘ : {‘pty‘ : 22}}
result = col.update(condition, pty)
# 删除
result = coll.remove({‘item‘ : ‘book‘})
result = coll.delete_one({‘item‘ : ‘book‘})
resuIt = collection.delete_many({‘item‘ : book1})
原文:https://www.cnblogs.com/zhh567/p/14119827.html