一、原始数据
数据量:5000条 119kb
二、任务目标
1.获取原始数据:时间戳、省份、城市、用户、广告编号
2.将原始数据转换为((省份,广告),1)的形式
3.将转换后的数据进行聚合((省份,广告),1)=>((省份,广告),sum)
4.将聚合后的数据进行结构的转换:((省份,广告),sum)=>(省份,(广告,sum))
5.将得到的数据按照省份来进行分组,转换为(省份,(广告,sum),(广告,sum),(广告,sum)... )的格式
6.将分组后的数据组内排序(降序),取前三名
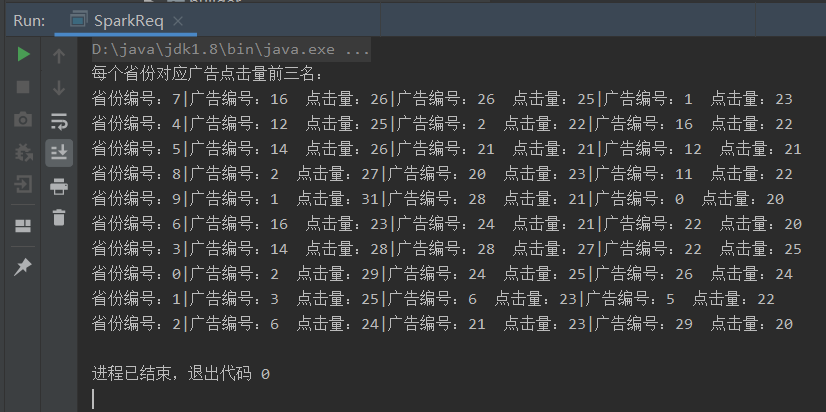
package rdd.operator.transform import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object SparkReq { def main(args: Array[String]): Unit = { val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator") val sc = new SparkContext(sparkConf) //1.获取原始数据:时间戳、省份、城市、用户、广告编号 val dataRDD: RDD[String] = sc.textFile("datas/agent.log") //2.将原始数据转换为((省份,广告),1)的形式 val mapRDD: RDD[((String, String), Int)] = dataRDD.map( (line: String) => { val datas: Array[String] = line.split(" ") ((datas(1), datas(4)), 1) } ) //3.将转换后的数据进行聚合((省份,广告),1)=>((省份,广告),sum) val reduceRDD: RDD[((String, String), Int)] = mapRDD.reduceByKey(_ + _) //4.将聚合后的数据进行结构的转换:((省份,广告),sum)=>(省份,(广告,sum)) val newmapRDD: RDD[(String, (String, Int))] = reduceRDD.map({ case ((prv, ad), sum) => (prv, (ad, sum)) }) //5.将得到的数据按照省份来进行分组 val groupRDD: RDD[(String, Iterable[(String, Int)])] = newmapRDD.groupByKey() //6.将分组后的数据组内排序(降序),取前三名 val resultRDD: RDD[(String, List[(String, Int)])] = groupRDD.map( str => { val list: List[(String, Int)] = str._2.toList.sortBy(_._2)(Ordering.Int.reverse).take(3) val sheng=str._1 println("省份编号:"+sheng+"|广告编号:"+list.head._1+" 点击量:"+list.head._2+ "|广告编号:"+list(1)._1+" 点击量:"+list(1)._2+ "|广告编号:"+list(2)._1+" 点击量:"+list(2)._2) (str._1, list) } ) /*val resultRDD: RDD[(String, List[(String, Int)])] = groupRDD.mapValues( (iter: Iterable[(String, Int)]) => { iter.toList.sortBy(_._2)(Ordering.Int.reverse).take(3) } )*/ //7.打印结果 println("每个省份对应广告点击量前三名:") resultRDD.collect() sc.stop() } }
五、运行结果
原文:https://www.cnblogs.com/dd110343/p/14319556.html