GBDT是以决策树(CART)为基学习器的GB算法,xgboost扩展和改进了GDBT,xgboost算法更快,准确率也相对高一些。
GBDT算法的步骤:根据上一步迭代出来的残差(残差:样本实际值 – 样本预测值,初始值为样本值),GBDT是根据残差(xgboost根据一阶导G和二阶导H)来训练基学习器,计算基学器的权重,更新样本残差以及对应的权重,直到代价函数收敛为止。当预测样本进来时,依次用每个基学习器预测值相加作为整个的预测结果。
1.初始化模型为常数值:
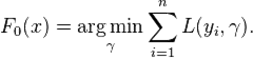
2.迭代生成M个基学习器
1.计算伪残差即该次迭代样本对应的权重
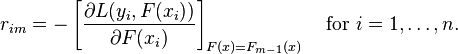
2.基于 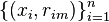 生成基学习器
生成基学习器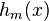
3.计算最优的 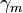 即该次迭代基学习器 的权重
即该次迭代基学习器 的权重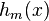
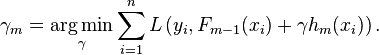
4.更新模型
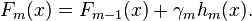
xgboost与gbdt比较大的不同就是目标函数的定义。 xgboost利用泰勒展开三项,做一个近似,最终的目标函数只依赖于每个数据点的在误差函数上的一阶导数和二阶导数。

其中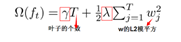
通过对 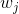 求导等于0,可以得到
求导等于0,可以得到 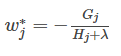
然后把 最优解代入得到目标函数得到目标最优
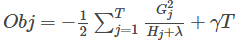
接下来就是在我们构造树的时候选择特征分裂节点
1)枚举所有不同树结构的贪心法
从树深度0开始,每一节点都遍历所有的特征,对于某个特征,先按照该特征里的值进行排序,然后依次计算假设按照整个特征这个值对树划分成左右子树,分别计算左右子树对应的目标值 ,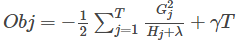
再减去没划分前的目标值得(类似信息增益,用分裂后的熵的累计减去分裂前的熵得这次分裂带来的信息增益)
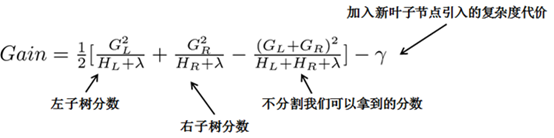
选出里面最大的值作为最好的分割点,最后对所有特征进行分割后。
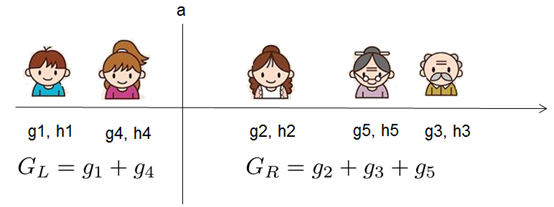
具体算法如下:

2)近似算法
主要针对数据太大,不能直接进行计算 。
在寻找最佳分割点时,考虑传统的枚举每个特征的所有可能分割点的贪心法效率太低,xgboost实现了一种近似的算法。大致的思想是根据百分位法列举几个可能成为分割点的候选者,然后从候选者中根据上面求分割点的公式计算找出最佳的分割点。

xgboost与gdbt异同点
Xgboost是gdbt算法的高效改进, 都是boost系增强算法(串行强上下游依赖关系),xgboost中的基学习器除了可以是CART回归树也可以是线性分类器,目标函数加了正则化项(与叶子节点和叶子节点的值有关)避免过拟合,目标计算的时候利用了泰勒展开前三项近似,同层级节点支持并行化,再节点划分选择的时候提供了近似的算法减少计算量(根据特征百分位法列举几个可能成为分割点的候选者再去寻找最优的划分)。
原文:https://www.cnblogs.com/Hailong-Said/p/14318736.html