 View Code
View Code进入spark/bin目录下输入spark-shell启动spark
(1)该系共有多少学生;
(2)该系共开设来多少门课程;
实验代码:
package sy4 import org.apache.spark.{SparkConf, SparkContext} object sjqc { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("Sjqc") val sc = new SparkContext(conf) val dataFile = "E:\\IntelliJ IDEA 2019.3.3\\WorkSpace\\MyScala\\src\\main\\scala\\sy4\\A.txt,E:\\IntelliJ IDEA 2019.3.3\\WorkSpace\\MyScala\\src\\main\\scala\\sy4\\B.txt" val lines = sc.textFile(dataFile,2) val distinct_lines = lines.distinct() distinct_lines.repartition(1).saveAsTextFile("./src/main/scala/sy4/C.txt") } }
实验结果:
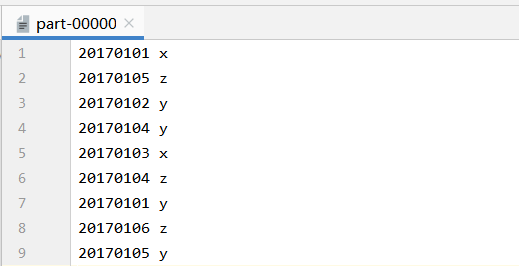
实验代码:
package sy4 import org.apache.spark.SparkContext import org.apache.spark.SparkConf import org.apache.spark.HashPartitioner object exercise03 { def main(args:Array[String]) { val conf = new SparkConf().setAppName("exercise03") val sc = new SparkContext(conf) val dataFile = "file://E:/IntelliJ IDEA 2019.3.3/WorkSpace/MyScala/src/main/scala/sy4/student.txt" val data = sc.textFile(dataFile,3) val res=data.filter( _.trim().length>0).map(line=>(line.split(" ")(0).trim(),line.split(" ")(1).trim().toInt)).partitionBy(new HashPartitioner(1)).groupByKey().map(x=>{ var n=0 var sum=0.0 for(i<-x._2){ sum=sum+i n=n+1 } val avg=sum/n val format=f"$avg%1.2f".toDouble (x._1,format)}) res.saveAsTextFile("./result") } }
实验结果:
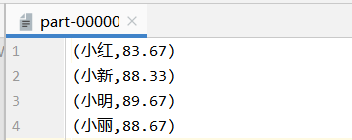
原文:https://www.cnblogs.com/hhjing/p/14322990.html
