python多线程爬虫
进程:
进程就是一个程序在一个数据集上的一次动态执行过程。进程一般由程序、数据集、进程控制块三部分组成。我们编写的程序用来描述进程要完成哪些功能以及如何完成;数据集则是程序在执行过程中所需要使用的资源;进程控制块用来记录进程的外部特征,描述进程的执行变化过程,系统可以利用它来控制和管理进程,它是系统感知进程存在的唯一标志。
线程:
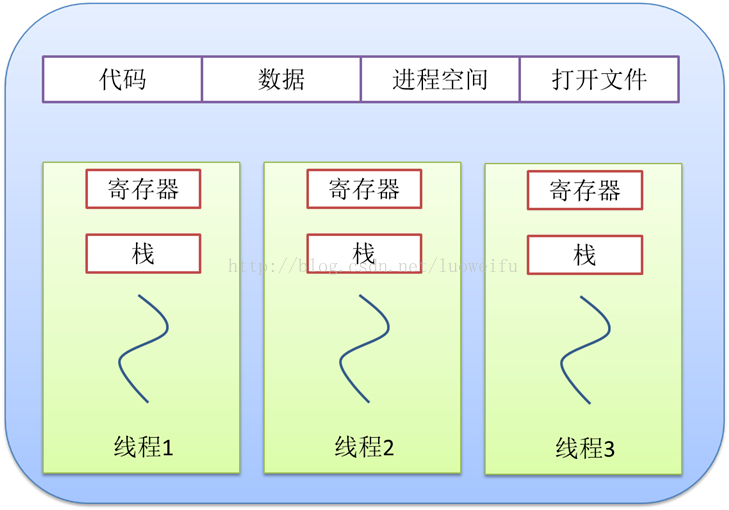
线程也叫轻量级进程,它是一个基本的CPU执行单元,也是程序执行过程中的最小单元,是处理器调度和分派的基本单位,由线程ID、程序计数器、寄存器集合和堆栈共同组成。线程的引入减小了程序并发执行时的开销,提高了操作系统的并发性能。
进程与线程的关系
(1)一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程。
(2)资源分配给进程,同一进程的所有线程共享该进程的所有资源。
(3)CPU分给线程,即真正在CPU上运行的是线程。
简单点理解:电脑上同时运行微信、QQ、钉钉,这就是多进程。在QQ上一边视频一边发信息就是多线程。
t = threading.Thread(target=xxx, name=xxx, args=(xx, xx))
target: 线程启动之后要执行的函数
name: 线程的名字
获取线程名字 :threading.current_thread().name
args: 主线程向子线程传递参数
t.start() : 启动线程
t.join() : 让主线程等待子线程结束
#面向过程的实现方法 import threading import time def sing(key): for item in range(1,7): print("我在唱歌") time.sleep(1) def dance(key): for item in range(1,7): print("我在跳舞") time.sleep(1) if __name__=="__main__": key="小强" # 面向过程方式创建线程 sThread = threading.Thread(target=sing, name="唱歌", args=(key,)) dThread = threading.Thread(target=dance, name="跳舞", args=(key,)) sThread.start() dThread.start() sThread.join() dThread.join() print("主线程结束")
#面向对象的实现方法 import threading import time """ 定义一个类,继承自threading.Thread """ class singThread(threading.Thread): def __init__(self,name,args): super().__init__() self.name=name self.args=args def run(self): for i in range(1,7): print(‘线程{}----{}:i am sing‘.format(self.name,self.args)) time.sleep(0.5) class danceThread(threading.Thread): def __init__(self, name, args): super().__init__() self.name = name self.args = args def run(self): for i in range(1,7): print(‘线程{}----{}:i am dance‘.format(self.name,self.args)) time.sleep(0.5) def main(): #创建线程 sing =singThread(1,‘小丽‘) dance =danceThread(2,‘小强‘) #启动线程 sing.start() dance.start() #设置主线程等待子线程结束 sing.join() dance.join() if __name__ == "__main__": main()
线程之间共享全局变量,当同时需要对某个全局变量进行操作的时候会出现数据混乱的现象,这个时候要使用线程锁来处理这种情况。多个线程之间谁抢到谁上锁,谁使用,完毕之后将锁释放。
创建锁:s = threading.Lock()
上锁:s.acquire()
释放锁:s.release()
先进先出原则
创建队列:q = Queue(5)
给队列添加数据:q.put(‘xxx‘)
q.put(‘xxx‘, False) 如果队列满,程序直接报错
q.put(‘xxx‘, True, 3) 如果队列满,程序等待3s再报错
q.get() 获取数据,如果队列为空卡在这里等待
q.get(False) 如果队列为空,程序直接报错
q.get(True, 3) 如果队列为空,程序等待3s报错
q.empty() 判断队列是否为空
q.full() 判断队列是否已满
q.qsize() 获取队列长度
构建两类线程:爬取、解析
url队列:爬取线程从url队列get数据,获取需要爬取的地址,爬取数据
内容队列:爬取线程往队列中put数据,解析线程从队列get数据,并负责写入数据。
写数据:上锁
#-*-coding:gb2312-*- import requests import threading from queue import Queue from lxml import etree import time import json #定义标记位 data_flag=False #创建队列 def creatQueue(): #创建存储爬取的页码的url队列 page_queue=Queue() #创建存储爬取到的网页内容的队列 data_queue=Queue() #爬取50页内容 for i in range(1,11): page_queue.put(i) return page_queue,data_queue #crawl 爬取 #parse 解析 #创建爬取线程存储列表 Crawl_thread_list=[] #创解析取线程存储列表 Parse_thread_list=[] #创建爬取线程类 class Crawl_thread(threading.Thread): def __init__(self,name,page_queue,data_queue): super(Crawl_thread, self).__init__() self.name=name self.page_queue=page_queue self.data_queue=data_queue self.url=r‘http://www.ifanjian.net/jiantu-{}‘ self.header={‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36‘} def run(self): print(‘%s-------启动‘%self.name) while 1: #爬取线程退出 if self.page_queue.empty(): print(‘{}爬取完毕,线程退出‘.format(self.name)) break # 获取要采集的页码序号并拼接url print(‘{}开始爬取数据‘.format(self.name)) url= self.url.format(self.page_queue.get()) #爬取网页信息 r= requests.get(url=url,headers=self.header) #将爬取的网页信息放入数据队列中 self.data_queue.put(r.text) print(‘%s-------结束‘%self.name) #创建解析线程类 class Parse_thread(threading.Thread): def __init__(self,name,data_queue,fp,lock): super(Parse_thread, self).__init__() self.name=name self.data_queue = data_queue self.fp=fp self.lock=lock def run(self): print(‘%s-------启动‘%self.name) #count=1 while 1: #解析线程结束 if data_flag: print(‘{}数据解析完毕,线程退出‘.format(self.name)) break #从数据队列中获取要采集到的数据 data= self.data_queue.get() print(‘{}开始解析数据‘.format(self.name)) self.parse_content(data) #count += 1 print(‘%s-------结束‘%self.name) def parse_content(self, data): tree = etree.HTML(data) # 对取出的数据进行解析 # 获取 标题和图片地址所在的位置 li = tree.xpath("//div[@class=‘page-body clearfix‘]//li[@class=‘cont-item‘]") # 建立列表临时存储解析出的数据 items = [] for temp in li: # 获取标题 tittle = temp.xpath(".//h2/a/text()") # 获取图片src,懒加载 image_src = temp.xpath("./div[2]//img/@data-src") item = {‘标题‘: tittle, ‘链接‘: image_src} # 临时存储数据 items.append(item) print(items) # 将数据写入文件 # 获取全局锁 self.lock.acquire() # 写入数据 print(‘{}开始写入数据‘.format(self.name)) self.fp.write(json.dumps(items, ensure_ascii=False) + ‘\n‘) # 释放全局锁 self.lock.release() #定义爬取线程创建函数 def Creat_crawl_thread(num,page_queue,data_queue): #创建线程名称列表 name_list=[‘爬取线程{}‘.format(i) for i in range(1,num+1)] #创建爬取线程 for name in name_list: crawl_thread= Crawl_thread(name,page_queue,data_queue) Crawl_thread_list.append(crawl_thread) #定义解析线程创建函数 def Creat_parse_thread(num,data_queue,fp,lock): #创建线程名称列表 name_list=[‘解析线程{}‘.format(i) for i in range(1,num+1)] #创建爬取线程 for name in name_list: parse_thread= Parse_thread(name,data_queue,fp,lock) Parse_thread_list.append(parse_thread) def main(): #创建队列 page_queue,data_queue= creatQueue() #创建数据存储文件 fp= open(‘fangjian.json‘,‘a‘,encoding=‘utf8‘) #创建全局锁 lock= threading.Lock() #创建线程 #创建爬取线程 Creat_crawl_thread(3,page_queue,data_queue) #创建解析线程 Creat_parse_thread(3,data_queue,fp,lock) #启动爬取线程 for crawl_thread in Crawl_thread_list: crawl_thread.start() #等待10秒 #time.sleep(10) # 启动解析线程 for parse_thread in Parse_thread_list: parse_thread.start() # 判断数据是否爬取解析完毕 while 1: if page_queue.empty(): break while 1: if data_queue.empty(): global data_flag data_flag = True break #设置主线程等待子线程结束 for crawl_thread in Crawl_thread_list: crawl_thread.join() for parse_thread in Parse_thread_list: parse_thread.join() #数据写入结束,关闭文件 fp.close() print(‘主线程结束‘) if __name__ == ‘__main__‘: main()
原文:https://www.cnblogs.com/gostClimbers/p/14323049.html