论文:Automated Phrase Mining from Massive Text Corpora
工具:https://github.com/shangjingbo1226/AutoPhrase
论文核心思想: 自动短语挖掘
AutoPhrase可以支持任何语言,只要该语言中有通用知识库。与当下最先进的方法比较,新方法在跨不同领域和语言的5个实际数据集上的有效性有了显著提高。
算法概览:
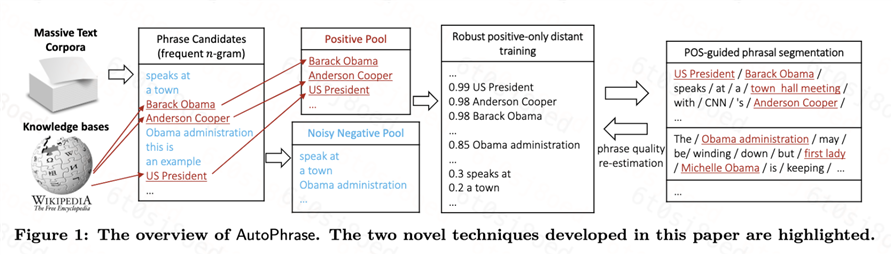
1)利用已有的知识库(如Wikipedia)做远程监督训练
Step1: 根据输入语料和知识库构建训练样本
Step2: 负样本去躁、训练分类器
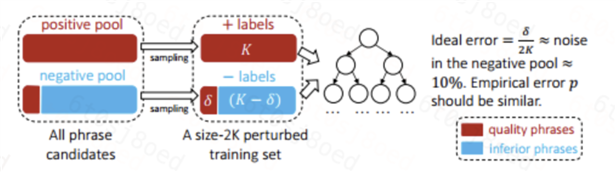
有的n-gram是关键短语,但是并不在Wikipedia中,但是在Step1中,我们把它作为负样本了,这种n-gram就成为了负样本中的噪音
解决方案:使用一个集成分类器来解决,这种方法最大程度上减轻噪声对训练的影响,论文中用的是随机森林
Step3: 对输入语料中的高频n-gram进行分类,得到n-gram是质量短语的评估score
2) POS-Guided短语分割
目的:利用词性信息来增加抽取的准确性
核心思想:根据词性进行分割,将文本划分成若干个短语(有点类似中文分词得意思,只不过分的是短语,因为前面我们得到的n-gram可能是一个不成词没有意义的序列)
使用最大似然法:
在给定词性序列? 的情况下,每个片段是高质量短语的概率乘积是最大的,那么就是最优分割

3)短语质量评估score修正
经过POS-Guided分割之后,对短语质量进行第二次评估,修正第一次评估的score,选取修正后的score比较高的作为质量短语输出
Automated Phrase Mining from Massive Text Corpora 论文解读
原文:https://www.cnblogs.com/zhangkl/p/14325589.html