前言:哎呀妈呀,组队学习要结束了。感觉自己划水划得...最近忙成狗了。前几天老师让把数据实现。我终于找到了,然后花了两天时间把文本文件转化成了字典。啊,效率极低。而且论文的Sxy到底是什么意义,我有有些搞不懂了。有点怀疑自己到底行不行。除此之外,最近有点腰疼。不敢碰电脑了都。哭。最后一次打卡。好好完成吧(厚着脸皮说)
# 导入所需的package import seaborn as sns #用于画图 from bs4 import BeautifulSoup #用于爬取arxiv的数据 import re #用于正则表达式,匹配字符串的模式 import requests #用于网络连接,发送网络请求,使用域名获取对应信息 import json #读取数据,我们的数据为json格式的 import pandas as pd #数据处理,数据分析 import matplotlib.pyplot as plt #画图工具
data = [] #初始化 #使用with语句优势:1.自动关闭文件句柄;2.自动显示(处理)文件读取数据异常 with open(r"path", ‘r‘) as f: for idx, line in enumerate(f): d = json.loads(line) d = {‘authors_parsed‘: d[‘authors_parsed‘]} data.append(d) data = pd.DataFrame(data) #将list变为dataframe格式,方便使用pandas进行分析
(dataframe,matplotlib见论文1)
import networkx as nx # 创建无向图 G = nx.Graph() # 只用1000篇论文进行构建 for row in data.iloc[:50].itertuples(): authors = row[1] authors = [‘ ‘.join(x[:-1]) for x in authors] # 第一个作者 与 其他作者链接 for author in authors[1:]: G.add_edge(authors[0],author) # 添加节点2,3并链接23节点
画出最短路径图。
nx.draw(G, with_labels=True)
两个作者间的关联。
try: print(nx.dijkstra_path(G, ‘Balázs C.‘, ‘Nadolsky P.M.‘)) except: print(‘No path‘)
(https://blog.csdn.net/weixin_44828950/article/details/91471459)try与except的用法。
# 计算论文关系中有多少个联通子图 print(len(nx.communicability(G))) plt.loglog(degree_sequence, "b-", marker="o") plt.title("Degree rank plot") plt.ylabel("degree") plt.xlabel("rank") # draw graph in inset plt.axes([0.45, 0.45, 0.45, 0.45]) Gcc = G.subgraph(sorted(nx.connected_components(G), key=len, reverse=True)[0]) pos = nx.spring_layout(Gcc) plt.axis("off") nx.draw_networkx_nodes(Gcc, pos, node_size=20) nx.draw_networkx_edges(Gcc, pos, alpha=0.4) plt.show()
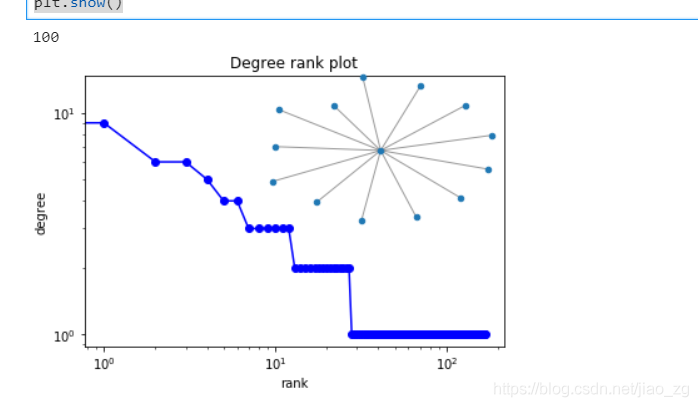
(摘自https://global-fairy-top.blog.csdn.net/article/details/113098372)
原文:https://www.cnblogs.com/LiangEn/p/14328152.html