spider_QiuShi.py
import scrapy class SpiderQiushiSpider(scrapy.Spider): #爬虫名字 name = ‘spider_QiuShi‘ #域名限制列表,列表值可以设置多个,限制爬虫只爬取该域名下的网页 allowed_domains = [‘www.qiushibaike.com‘] #初始爬取地址 start_urls = [‘http://www.qiushibaike.com/text‘] def parse(self, response): div_list= response.xpath(‘//div[@class="col1 old-style-col1"]/div‘) items=[] for li in div_list: name= li.xpath(‘.//h2/text()‘)[0].extract().strip(‘\n‘).strip(‘ ‘) face_src= "https:"+li.xpath(‘.//div[1]/a[1]/img/@src‘)[0].extract().split(‘?‘)[0] item= { "名称":name, "链接":face_src } items.append(item) print(items) return items
2.response的常用方法和属性
text: 字符串类型
body: 字节类型
xpath(): scrapy内部已经集成了xpath,直接使用即可,但这里的xpath其他 包中的xpath略有不同,定位后提取出来的元素为selector对象
因此要获取其中的值需要使用.extract()方法。
3.运行爬虫
scrapy crawl spider_QiuShi
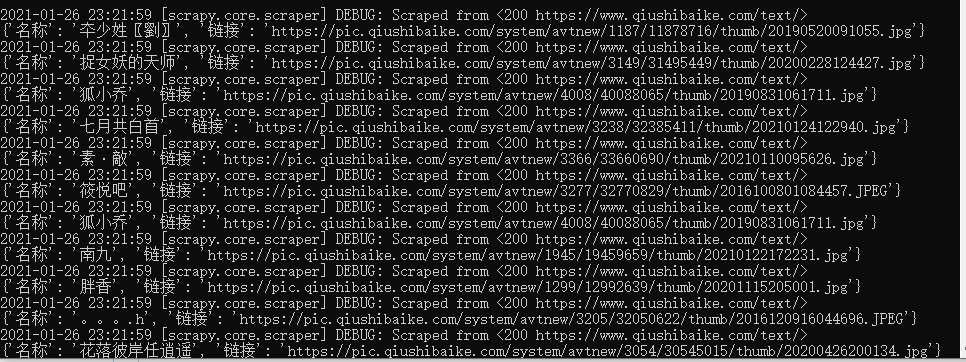
scrapy crawl spider_QiuShi -o qiushibaike.json
scrapy crawl spider_QiuShi -o qiushibaike.xml
scrapy crawl spider_QiuShi -o qiushibaike.csv
原文:https://www.cnblogs.com/gostClimbers/p/14333023.html