本篇是基于我个人在实训过程中所运用到的一些关于Es的知识的讲解,包括基本的插入,删除等等操作
拉到最下面有全部代码
首先要在本机环境安装es,具体安装教程可见其他博文,本处不多赘述。本人安装的是7.9.3版本,因为涉及到了ik分词器的使用,而ik分词器的版本需要与Es的版本相对应,所以选择了当下最新的7.9.3版本进行安装
然后导入相关的包
import csv #从csv导入内容到es中
from elasticsearch import Elasticsearch #基本的导包
from elasticsearch.helpers import bulk #使用bulk导入信息至es中需要
导包结束后,接下来是es工具类的实现,本处使用到的csv的信息每行共有五列,具体讲解请见代码注释
代码如下:
class ElasticObj:
def __init__(self, index_name,index_type,ip ="127.0.0.1"): # 初始化
self.index_name = index_name
self.index_type = index_type
self.es = Elasticsearch([ip], timeout = 60)
def create_index(self,index_name="ott",index_type="_doc"): # 创建映射
_index_mappings = {
"mappings": {
"properties": { #这里的内容对应的是想要在es中存储的格式,本处共有五列,分别对应的是标题,时间,链接,内容,情感
"title": {
"type": "text",
},
"time": {
"type": "date", # 格式为时间
"format":"yyyy-MM-dd HH:mm:ss" #format可以控制导入的时间的格式,需要从csv中导入的信息格式一致,否则会报错
},
"url": {
"type": "text"
},
"content": {
"type": "text",
"analyzer": "ik_smart", # 本处使用的是ik_smart模式,会将文本做最粗粒度的拆分,如果需要更细粒度的拆分可以使用ik_max_word模式
"search_analyzer": "ik_smart",
"fielddata":True, #聚类查询,默认是false
},
"sentiment":{
"type":"text",
}
}
}
}
if self.es.indices.exists(index=self.index_name) is not True:
res = self.es.indices.create(index=self.index_name, body=_index_mappings)
print(res)
def Get_data(self, csvfile): # 从csv中导入数据
f = open(csvfile, ‘r‘, encoding=‘utf-8‘) #注意编码
csvreader = csv.reader(f)
l = list(csvreader) #用列表存储
return l
def Index_Data_FromCSV(self, csvfile): # 从csv读取数据存到es中(bulk)
l = self.Get_data(csvfile)
ACTIONS = []
index = 0
for line in l:
index = index + 1
if index % 5000 == 0: # 分批次处理,每5000打印一次,并且清空一次ACTIONS, 加快插入速度
success, _ = bulk(self.es, ACTIONS, index=self.index_name)
ACTIONS = []
print(‘Performed %d actions‘ % success)
if index > 1:
action = {
"_index": self.index_name,
"_type":"_doc",
"_id": index,
"_source": {
"title": line[0],
"time":line[1],
"url": line[2],
"content": line[3],
"sentiment": line[4]
}
}
ACTIONS.append(action)
if (len(ACTIONS) > 0):
bulk(self.es, ACTIONS, index=self.index_name)
def Get_Data_By_Body(self, stype, where, word): # 基础搜索
doc = {
"query": {
stype: {
where:word, #查找指定词汇 ,可以根据自己实际情况发生变化
}
}
}
_searched = self.es.search(index=self.index_name, doc_type=self.index_type, body=doc,params={"size":20}) #这里的20指的是评分最高的前20条 可以根据实际情况调整
return _searched[‘hits‘][‘hits‘]
def Get_Data_By_Body1(self, stype, where, word, date1, date2): # 进阶搜素1
doc = {
"query": {
stype: {
where:word,
},
"range":{ #此时的搜索内容会进行进一步的处理,本处是筛选指定时间段内的相关内容
"time":{
"from": date1,
"to":date2
}
}
}
}
_searched = self.es.search(index=self.index_name, doc_type=self.index_type, body=doc,params={"size":20})
return _searched[‘hits‘][‘hits‘]
def Delete_of_all(self): # 清空es内存储的所有内容
body = {
"query":{
"match_all":{}
}
}
res = self.es.search(index = self.index_name, body = body)
self.es.delete_by_query(index = self.index_name, body = body)
print("清空完成")
def Delete_Index(self, my_index): #清空索引
self.es.indices.delete(index=my_index, ignore=[400, 404])
def Get_data_time(self, date1, date2, word): #每天的关键词的情感趋势
doc = {
"query":{
"bool":{
"must":[{
"range":{
"time":{
"from": date1,
"to":date2
}
}
},
{
"match":{
"content":word,
}
}]
}
}
}
_searched = self.es.search(index=self.index_name, doc_type=self.index_type, body=doc,params={"size":200})
return _searched[‘hits‘][‘hits‘]
def Hot_words_time(self, date1, date2): # 根据日期挑选热词
doc = {
"aggs":{
"date_ranges":{
"range":{
"field":"time",
"ranges":[
{
"from":date1,
"to":date2
},
]},
"aggs":{
"content":{
"terms":{
"field":"content",
"size":50,
"order":[{"_count":"desc"}] #降序
}
}
}
}
}
}
_searched = self.es.search(index=self.index_name, doc_type=self.index_type, body=doc)
return _searched[‘aggregations‘]
下面是对于es类的一些功能的基本调用
首先是创建索引,索引的名称为ott,索引类型为_doc,注意如果需要使用ik分词器的功能,索引类型一定要是_doc
obj = ElasticObj("ott", "_doc") #此时创建的索引不可使用ik分词器,因为不是按照mappings创建的
obj.Delete_Index("ott") #删除
obj.create_index(index_name="ott",index_type="_doc") #创建新的索引
清空全部数据
如果原索引下有废弃数据,可以先清空
#obj.Delete_of_all()
将csv的文件导入es
#csvfile = ‘G:/大学课程/大三上/实训一/代码/datasets/data.csv‘
#obj.Index_Data_FromCSV(csvfile)
根据指定词查找相关信息
data = obj.Get_Data_By_Body("match", "content", "王一博") 从左到右分别是匹配模式,匹配的信息内容,这里是content,然后查询词为王一博(捂脸)
for hit in data:
print(hit) 具体想要打印的东西可以自行调整,也可以在上面的return调整
打印出来的样例展示,我们可以看到打印的排序是按照score的从大到小来的
{‘_index‘: ‘ott‘, ‘_type‘: ‘_doc‘, ‘_id‘: ‘19345‘, ‘_score‘: 15.318817, ‘_source‘: {‘title‘: ‘4464409064170710‘, ‘time‘: ‘2020-01-24 23:58:00‘, ‘url‘: "[‘https://wx1.sinaimg.cn/large/48f988e6gy1gb6zfzddjzj20zk0k00ta.jpg‘]", ‘content‘: ‘新年快乐,愿大家健健康康//@王一博粉丝后援会:\ue627王一博wyb#正能量艺人王一博#防控疫情,从你我做起!@UNIQ-王一博//@王一博粉丝后援会:\ue627王一博wyb#正能量艺人王一博#防控疫情,从你我做起!@UNIQ-王一博‘, ‘sentiment‘: ‘1‘}}
{‘_index‘: ‘ott‘, ‘_type‘: ‘_doc‘, ‘_id‘: ‘45523‘, ‘_score‘: 15.318817, ‘_source‘: {‘title‘: ‘4464409064170710‘, ‘time‘: ‘2020-01-24 23:58:00‘, ‘url‘: "[‘https://wx1.sinaimg.cn/large/48f988e6gy1gb6zfzddjzj20zk0k00ta.jpg‘]", ‘content‘: ‘新年快乐,愿大家健健康康//@王一博粉丝后援会:\ue627王一博wyb#正能量艺人王一博#防控疫情,从你我做起!@UNIQ-王一博//@王一博粉丝后援会:\ue627王一博wyb#正能量艺人王一博#防控疫情,从你我做起!@UNIQ-王一博‘, ‘sentiment‘: ‘1‘}}
{‘_index‘: ‘ott‘, ‘_type‘: ‘_doc‘, ‘_id‘: ‘11204‘, ‘_score‘: 15.241138, ‘_source‘: {‘title‘: ‘4470884200733640‘, ‘time‘: ‘2020-02-11 20:48:00‘, ‘url‘: "[‘https://wx3.sinaimg.cn/orj480/007QLKuBgy1gbspsf5v11j31hc0u07wh.jpg‘]", ‘content‘: ‘//@王一博数据组:\ue627王一博wyb#天天向上王一博#听妈妈的话,坚持增强抵抗力!一博@UNIQ-王一博你好可爱!‘, ‘sentiment‘: ‘1‘}}
根据日期和指定词查找,注意左边是比较靠前的日期(因为对应代码中的range的 from 和 to)
data = obj.Get_data_time("2020-01-01 00:00:00", "2020-01-03 00:00:00", "王一博")
for hit in data:
print(hit)
可以看出来的确在指定日期区间内了(展示部分)
{‘_index‘: ‘ott‘, ‘_type‘: ‘_doc‘, ‘_id‘: ‘88326‘, ‘_score‘: 15.336415, ‘_source‘: {‘title‘: ‘4455879775049460‘, ‘time‘: ‘2020-01-01 11:06:00‘, ‘url‘: ‘[]‘, ‘content‘: ‘#王一博丸子头#惊喜到呼吸困难\ue627王一博?‘, ‘sentiment‘: ‘1‘}}
{‘_index‘: ‘ott‘, ‘_type‘: ‘_doc‘, ‘_id‘: ‘15587‘, ‘_score‘: 13.824566, ‘_source‘: {‘title‘: ‘4456435633056360‘, ‘time‘: ‘2020-01-02 23:55:00‘, ‘url‘: "[‘https://ww1.sinaimg.cn/orj360/007zChz8gy1gadocwxb7wj30u0190npd.jpg‘, ‘https://ww4.sinaimg.cn/orj360/007zChz8gy1gadocxbosdj30u0190qv5.jpg‘]", ‘content‘: ‘#王一博唱囧妈#//@UNIQ-王一博:治愈囧途,音乐相伴,大年初一看《囧妈》!给您比个心???//@徐峥:#王一博唱囧妈#够不够惊喜?够不够意外?掌声欢迎我们的新乘客一博!大年初一,比个心~‘, ‘sentiment‘: ‘1‘}}
{‘_index‘: ‘ott‘, ‘_type‘: ‘_doc‘, ‘_id‘: ‘41766‘, ‘_score‘: 13.824566, ‘_source‘: {‘title‘: ‘4456435633056360‘, ‘time‘: ‘2020-01-02 23:55:00‘, ‘url‘: "[‘https://ww1.sinaimg.cn/orj360/007zChz8gy1gadocwxb7wj30u0190npd.jpg‘, ‘https://ww4.sinaimg.cn/orj360/007zChz8gy1gadocxbosdj30u0190qv5.jpg‘]", ‘content‘: ‘#王一博唱囧妈#//@UNIQ-王一博:治愈囧途,音乐相伴,大年初一看《囧妈》!给您比个心???//@徐峥:#王一博唱囧妈#够不够惊喜?够不够意外?掌声欢迎我们的新乘客一博!大年初一,比个心~‘, ‘sentiment‘: ‘1‘}}
{‘_index‘: ‘ott‘, ‘_type‘: ‘_doc‘, ‘_id‘: ‘91035‘, ‘_score‘: 11.179046, ‘_source‘: {‘title‘: ‘4455719112023000‘, ‘time‘: ‘2020-01-01 00:28:00‘, ‘url‘: ‘[]‘, ‘content‘: ‘#2020新年第一个愿望#中考考好加油!!!!天天开心家里人身体健康,去见王一博!!!!天天开心天天开心天天开心!!!?‘, ‘sentiment‘: ‘1‘}}
显示词频
指定时间段内的哪个词出现的频率最高,key是词,doc_count是出现次数,本处由高到底排列
x = obj.Hot_words_time("2020-01-01 00:00:00", "2020-01-14 00:00:00")
print(x[‘date_ranges‘][‘buckets‘][0][‘content‘][‘buckets‘])
[{‘key‘: ‘微博‘, ‘doc_count‘: 1186}, {‘key‘: ‘视频‘, ‘doc_count‘: 772}, {‘key‘: ‘1月‘, ‘doc_count‘: 761}, {‘key‘: ‘2020年‘, ‘doc_count‘: 588}, {‘key‘: ‘真的‘, ‘doc_count‘: 573}, {‘key‘: ‘致敬‘, ‘doc_count‘: 569}, {‘key‘: ‘治愈‘, ‘doc_count‘: 557}, {‘key‘: ‘武汉‘, ‘doc_count‘: 551}, {‘key‘: ‘中国‘, ‘doc_count‘: 511}, {‘key‘: ‘2020‘, ‘doc_count‘: 495}, {‘key‘: ‘医院‘, ‘doc_count‘: 419}, {‘key‘: ‘的人‘, ‘doc_count‘: 414}, {‘key‘: ‘生活‘, ‘doc_count‘: 410}, {‘key‘: ‘时‘, ‘doc_count‘: 403}, {‘key‘: ‘希望‘, ‘doc_count‘: 387}, {‘key‘: ‘隔离‘, ‘doc_count‘: 380}, {‘key‘: ‘患者‘, ‘doc_count‘: 378}, {‘key‘: ‘说‘, ‘doc_count‘: 377}, {‘key‘: ‘中‘, ‘doc_count‘: 372}, {‘key‘: ‘太‘, ‘doc_count‘: 370}, {‘key‘: ‘咳嗽‘, ‘doc_count‘: 348}, {‘key‘: ‘健康‘, ‘doc_count‘: 344}, {‘key‘: ‘治疗‘, ‘doc_count‘: 344}, {‘key‘: ‘感染‘, ‘doc_count‘: 339}, {‘key‘: ‘酒精‘, ‘doc_count‘: 339}, {‘key‘: ‘肺炎‘, ‘doc_count‘: 338}, {‘key‘: ‘消毒‘, ‘doc_count‘: 335}, {‘key‘: ‘发‘, ‘doc_count‘: 330}, {‘key‘: ‘肖‘, ‘doc_count‘: 330}, {‘key‘: ‘战‘, ‘doc_count‘: 326}, {‘key‘: ‘券‘, ‘doc_count‘: 324}, {‘key‘: ‘都是‘, ‘doc_count‘: 317}, {‘key‘: ‘时间‘, ‘doc_count‘: 310}, {‘key‘: ‘拍‘, ‘doc_count‘: 304}, {‘key‘: ‘前‘, ‘doc_count‘: 300}, {‘key‘: ‘医生‘, ‘doc_count‘: 298}, {‘key‘: ‘基层‘, ‘doc_count‘: 296}, {‘key‘: ‘转发‘, ‘doc_count‘: 295}, {‘key‘: ‘工作‘, ‘doc_count‘: 294}, {‘key‘: ‘疫苗‘, ‘doc_count‘: 294}, {‘key‘: ‘赞‘, ‘doc_count‘: 292}, {‘key‘: ‘心‘, ‘doc_count‘: 290}, {‘key‘: ‘捐赠‘, ‘doc_count‘: 290}, {‘key‘: ‘病毒‘, ‘doc_count‘: 288}, {‘key‘: ‘2019年‘, ‘doc_count‘: 285}, {‘key‘: ‘超‘, ‘doc_count‘: 285}, {‘key‘: ‘里‘, ‘doc_count‘: 284}, {‘key‘: ‘感觉‘, ‘doc_count‘: 274}, {‘key‘: ‘防控‘, ‘doc_count‘: 274}, {‘key‘: ‘人的‘, ‘doc_count‘: 272}]
指定时间段内的情感指数平均值
y = obj.Get_data_time("2020-01-01 00:00:00", "2020-01-28 00:00:00", "杨洋")
ssum = 0
for i in y:
if i[‘_source‘][‘sentiment‘] not in [‘1‘, ‘-1‘, ‘0‘]:
continue
ssum += int(i[‘_source‘][‘sentiment‘])
print(ssum / len(y))
import datetime
import time
import matplotlib.pyplot as plt
import locale
plt.rcParams[‘font.sans-serif‘]=[‘SimHei‘] # 用来正常显示中文标签
plt.rcParams[‘axes.unicode_minus‘]=False # 用来正常显示负号
# 可以用中文格式化
locale.setlocale(locale.LC_CTYPE, ‘chinese‘)
def Get_time_every(begin_date_str, end_date_str):
date_list = []
begin_date = datetime.datetime.strptime(begin_date_str, "%Y-%m-%d %H:%M:%S")
end_date = datetime.datetime.strptime(end_date_str, "%Y-%m-%d %H:%M:%S")
while begin_date <= end_date:
date_str = begin_date.strftime("%Y-%m-%d %H:%M:%S")
date_list.append(date_str)
begin_date += datetime.timedelta(days=1) 每隔一天计算一次情感均值
return date_list
x = Get_time_every("2020-01-01 00:00:00", "2020-02-28 00:00:00")
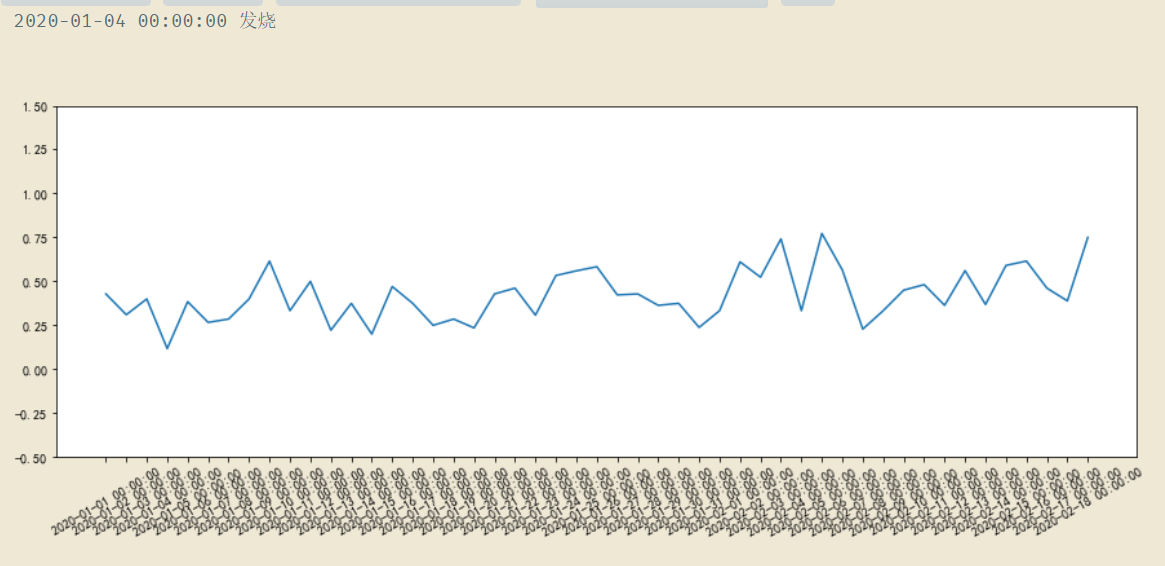
def draw_sentiment(date_list, word): #画图
date_every_sentiment = []
date_list_new = []
for i in range(len(date_list) - 1):
data_sentiment = obj.Get_data_time(date_list[i], date_list[i + 1], word)
if len(data_sentiment) == 0:
continue
else:
date_list_new.append(date_list[i])
ssum = 0
for j in data_sentiment:
if j[‘_source‘][‘sentiment‘] not in [‘1‘, ‘0‘, ‘-1‘]:
continue
ssum += int(j[‘_source‘][‘sentiment‘])
if (ssum / len(data_sentiment)) < 0.2:
print(date_list[i] , word)
date_every_sentiment.append(ssum / len(data_sentiment))
plt.figure(figsize=(15,5))
plt.plot(date_list_new, date_every_sentiment)
plt.ylim(-0.5, 1.5)
plt.xticks(rotation=30)
plt.show()
return [date_list_new, date_every_sentiment]
[date_list, date_every_sentiment] = draw_sentiment(x, "发烧")
全部代码整合如下(在上面的基础上有所增加)
import csv
from elasticsearch import Elasticsearch
from elasticsearch.helpers import bulk
class ElasticObj:
def __init__(self, index_name, index_type, ip="127.0.0.1"): # 初始化
self.index_name = index_name
self.index_type = index_type
self.es = Elasticsearch([ip], timeout=60)
def create_index(self, index_name="ott", index_type="_doc"):
# 创建映射
_index_mappings = {
"mappings": {
"properties": {
"title": {
"type": "text",
},
"time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
"url": {
"type": "text"
},
"content": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart",
"fielddata": True,
},
"sentiment": {
"type": "text",
}
}
}
}
if self.es.indices.exists(index=self.index_name) is not True:
res = self.es.indices.create(index=self.index_name, body=_index_mappings)
print(res)
def Get_data(self, csvfile):
f = open(csvfile, ‘r‘, encoding=‘utf-8‘)
csvreader = csv.reader(f)
l = list(csvreader)
return l
def Index_Data_FromCSV(self, csvfile): # 从csv读取数据存到es中(bulk)
l = self.Get_data(csvfile)
ACTIONS = []
index = 0
for line in l:
index = index + 1
if index % 5000 == 0: # 分批次处理
success, _ = bulk(self.es, ACTIONS, index=self.index_name)
ACTIONS = []
print(‘Performed %d actions‘ % success)
if index > 1:
action = {
"_index": self.index_name,
"_type": "_doc",
"_id": index,
"_source": {
"title": line[0],
"time": line[1],
"url": line[2],
"content": line[3],
"sentiment": line[4]
}
}
ACTIONS.append(action)
if (len(ACTIONS) > 0):
bulk(self.es, ACTIONS, index=self.index_name)
def Get_Data_By_Body(self, stype, where, word): # 搜索
doc = {
"query": {
stype: {
where: word,
}
}
}
_searched = self.es.search(index=self.index_name, doc_type=self.index_type, body=doc, params={"size": 1000})
return _searched[‘hits‘][‘hits‘]
def Delete_of_all(self): # 清空
body = {
"query": {
"match_all": {}
}
}
res = self.es.search(index=self.index_name, body=body)
self.es.delete_by_query(index=self.index_name, body=body)
print("清空完成")
def Delete_Index(self, my_index):
self.es.indices.delete(index=my_index, ignore=[400, 404])
def Get_data_time(self, date1, date2, word): # 每天的关键词的情感趋势
doc = {
"query": {
"bool": {
"must": [{
"range": {
"time": {
"from": date1,
"to": date2
}
}
},
{
"match": {
"content": word,
}
}]
}
}
}
_searched = self.es.search(index=self.index_name, doc_type=self.index_type, body=doc, params={"size": 1000})
return _searched[‘hits‘][‘hits‘]
def Get_data_time_sentiment(self, date1, date2, word, sen): # 每天的关键词的情感趋势
doc = {
"query": {
"bool": {
"must": [{
"range": {
"time": {
"from": date1,
"to": date2
}
}
},
{
"match": {
"content": word,
}
},
{
"match": {
"sentiment": sen,
}
},
]
}
}
}
_searched = self.es.search(index=self.index_name, doc_type=self.index_type, body=doc, params={"size": 1000})
return _searched[‘hits‘][‘hits‘]
def Hot_words_time(self, date1, date2): # 根据日期挑选热词
doc = {
"aggs": {
"date_ranges": {
"range": {
"field": "time",
"ranges": [
{
"from": date1,
"to": date2
},
]},
"aggs": {
"content": {
"terms": {
"field": "content",
"size": 50,
"order": [{"_count": "desc"}]
}
}
}
}
}
}
_searched = self.es.search(index=self.index_name, doc_type=self.index_type, body=doc)
return _searched[‘aggregations‘][‘date_ranges‘][‘buckets‘][0][‘content‘][‘buckets‘]
基于python的elasticsearch的应用实战(一)
原文:https://www.cnblogs.com/junyuebai/p/14335968.html