之前一直觉得matlab有mlx,python有ipynb(Jupyter Notebook),R就没有原生态的工具?直到发现了Rmd
后来觉得matlab有mat,R有Rdata,Python难道没有自己的数据保存格式?
其实,pickle可以在一定程度上完成这一功能。(学习自https://blog.csdn.net/chunmi6974/article/details/78392230/)
官网:https://docs.python.org/3/library/pickle.html
pickle可以将内存中的Python对象转换成为文本流,然后写入txt中。
pickle模块只能在python中使用,python中几乎所有的数据类型(列表,字典,集合,类等)都可以用pickle来序列化,
pickle序列化后的数据,可读性差,人一般无法识别。
由于其可读性较差,所以为了强调数据类型,也可以用一种自定义的文件后缀,如pydata。
其中要注意的是,在使用load(file)加载类对象时,要让python能够找到类的定义,否则会报错。
import pandas as pd test_dict = {‘id‘:[1,2,3], ‘name‘:[‘Alice‘,‘Bob‘,‘Cindy‘], ‘math‘:[90,89,99], ‘english‘:[89,94,80]} test_df = pd.DataFrame(test_dict) import pickle f=open(‘test.pydata‘,‘wb‘) pickle.dump(test_df,f) f.close() del test_df f=open(‘test.pydata‘,‘rb‘) test_df=pickle.load(f) f.close() test_df
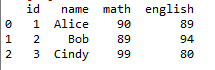
原文:https://www.cnblogs.com/dingdangsunny/p/14338032.html