? 多任务操作系统分为非抢占式多任务和抢占式多任务。与大多数现代操作系统一样,Linux采用的是抢占式多任务模式。这表示对CPU的占用时间由操作系统决定的,具体为操作系统中的调度器。调度器决定了什么时候停止一个进程以便让其他进程有机会运行,同时挑选出一个其他的进程开始运行。
? 在Linux上调度策略决定了调度器是如何选择一个新进程的时间。调度策略与进程的类型有关,内核现有的调度策略如下:
0: 默认的调度策略,针对的是普通进程。
1:针对实时进程的先进先出调度。适合对时间性要求比较高但每次运行时间比较短的进程。
2:针对的是实时进程的时间片轮转调度。适合每次运行时间比较长得进程。
3:针对批处理进程的调度,适合那些非交互性且对cpu使用密集的进程。
SCHED_ISO:是内核的一个预留字段,目前还没有使用
5:适用于优先级较低的后台进程。
注:每个进程的调度策略保存在进程描述符task_struct中的policy字段
? 内核引入调度类(struct sched_class)说明了调度器应该具有哪些功能。内核中每种调度策略都有该调度类的一个实例。(比如:基于公平调度类为:fair_sched_class,基于实时进程的调度类实例为:rt_sched_class),该实例也是针对每种调度策略的具体实现。调度类封装了不同调度策略的具体实现,屏蔽了各种调度策略的细节实现。
? 调度器核心函数schedule()只需要调用调度类中的接口,完成进程的调度,完全不需要考虑调度策略的具体实现。调度类连接了调度函数和具体的调度策略。
? 中断是指在CPU正常运行期间,由于内外部事件或由程序预先安排的事件引起的CPU暂时停止正在运行的程序,转而为该内部或外部事件或预先安排的事件服务的程序中去,服务完毕后再返回去继续运行被暂时中断的程序。
? 同步中断由CPU本身产生,又称为内部中断。这里同步是指中断请求信号与代码指令之间的同步执行,在一条指令执行完毕后,CPU才能进行中断,不能在执行期间。所以也称为异常(exception)。
? 异步中断是由外部硬件设备产生,又称为外部中断,与同步中断相反,异步中断可在任何时间产生,包括指令执行期间,所以也被称为中断(interrupt)。
? 异常又可分为可屏蔽中断(Maskable interrupt)和非屏蔽中断(Nomaskable interrupt)。而中断可分为故障(fault)、陷阱(trap)、终止(abort)三类。
? 从广义上讲,中断又可分为四类:中断、故障、陷阱、终止。
Linux中断机制由三部分组成:
中断子系统初始化:内核自身初始化过程中对中断处理机制初始化,例如中断的数据结构以及中断请求等。
中断或异常处理:中断处理过程,是指设备产生中断,并通过中断线将中断信号送往中断控制器,如果中断没有被屏蔽则会到达CPU的INTR引脚,CPU立即停止当前工作,根据获得中断向量号从IDT中找出门描述符,并执行相关中断程序。异常处理过程,是指异常是由CPU内部发生所以不会通过中断控制器,CPU直接根据中断向量号从IDT中找出门描述符,并执行相关中断程序。
中断控制器处理主要有5个步骤:1.中断请求 2.中断相应 3.优先级比较 4.提交中断向量 5.中断结束。CPU处理流程主要有6个步骤:1.确定中断或异常的中断向量 2.通过IDTR寄存器找到IDT 3.特权检查 4.特权级发生变化,进行堆栈切换 5.如果是异常将异常代码压入堆栈,如果是中断则关闭可屏蔽中断 6.进入中断或异常服务程序执行。这里不再赘述6个步骤的具体流程。
中断API:为设备驱动提供API,例如注册,释放和激活等。
? 软中断作为下半部机制的代表,是随着SMP(share memory processor)的出现应运而生的,它也是tasklet实现的基础(tasklet实际上只是在软中断的基础上添加了一定的机制)。软中断一般是“可延迟函数”的总称,有时候也包括了tasklet(请读者在遇到的时候根据上下文推断是否包含tasklet)。它的出现就是因为要满足上面所提出的上半部和下半部的区别,使得对时间不敏感的任务延后执行,软中断执行中断处理程序留给它去完成的剩余任务,而且可以在多个CPU上并行执行,使得总的系统效率可以更高。它的特性包括:
1)产生后并不是马上可以执行,必须要等待内核的调度才能执行。软中断不能被自己打断,只能被硬件中断打断(上半部)。
2)可以并发运行在多个CPU上(即使同一类型的也可以)。所以软中断必须设计为可重入的函数(允许多个CPU同时操作),因此也需要使用自旋锁来保护其数据结构。
? 由于软中断必须使用可重入函数,这就导致设计上的复杂度变高,作为设备驱动程序的开发者来说,增加了负担。而如果某种应用并不需要在多个CPU上并行执行,那么软中断其实是没有必要的。因此诞生了弥补以上两个要求的tasklet。它具有以下特性:
1)一种特定类型的tasklet只能运行在一个CPU上,不能并行,只能串行执行。
2)多个不同类型的tasklet可以并行在多个CPU上。
3)软中断是静态分配的,在内核编译好之后,就不能改变。但tasklet就灵活许多,可以在运行时改变(比如添加模块时)。
tasklet是在两种软中断类型的基础上实现的,因此如果不需要软中断的并行特性,tasklet就是最好的选择。也就是说tasklet是软中断的一种特殊用法,即延迟情况下的串行执行。
? 从上面的介绍看以看出,软中断运行在中断上下文中,因此不能阻塞和睡眠,而tasklet使用软中断实现,当然也不能阻塞和睡眠。但如果某延迟处理函数需要睡眠或者阻塞呢?没关系工作队列就可以如您所愿了。
? 把推后执行的任务叫做工作(work),描述它的数据结构为work_struct ,这些工作以队列结构组织成工作队列(workqueue),其数据结构为workqueue_struct ,而工作线程就是负责执行工作队列中的工作。系统默认的工作者线程为events。
? 工作队列(work queue)是另外一种将工作推后执行的形式。工作队列可以把工作推后,交由一个内核线程去执行—这个下半部分总是会在进程上下文执行,但由于是内核线程,其不能访问用户空间。最重要特点的就是工作队列允许重新调度甚至是睡眠。
? 通常,在工作队列和软中断/tasklet中作出选择非常容易。可使用以下规则:
- 如果推后执行的任务需要睡眠,那么只能选择工作队列。
- 如果推后执行的任务需要延时指定的时间再触发,那么使用工作队列,因为其可以利用timer延时(内核定时器实现)。
- 如果推后执行的任务需要在一个tick之内处理,则使用软中断或tasklet,因为其可以抢占普通进程和内核线程,同时不可睡眠。
- 如果推后执行的任务对延迟的时间没有任何要求,则使用工作队列,此时通常为无关紧要的任务。
? 实际上,工作队列的本质就是将工作交给内核线程处理,因此其可以用内核线程替换。但是内核线程的创建和销毁对编程者的要求较高,而工作队列实现了内核线程的封装,不易出错,所以我们也推荐使用工作队列。
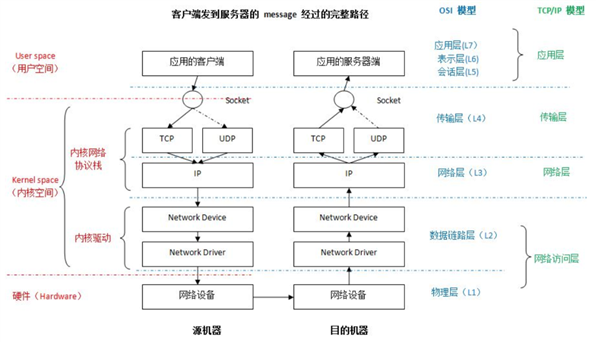
网路数据的交互模型:
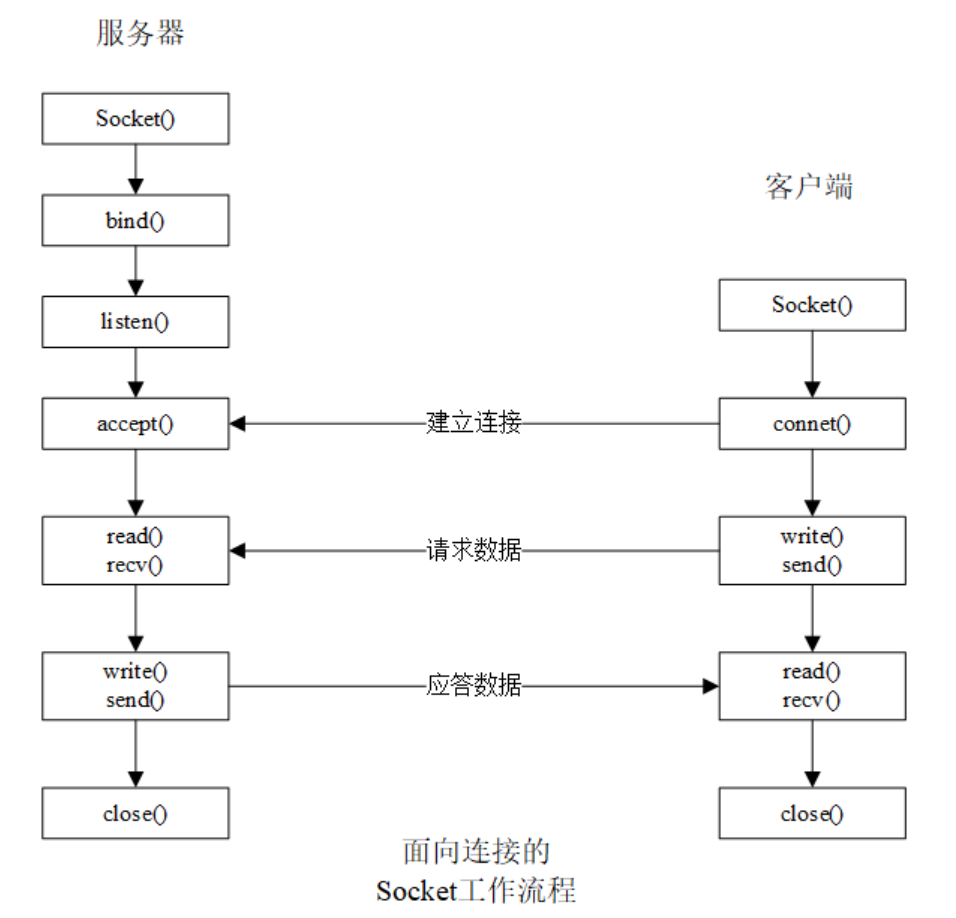
应用层可以使用以下Socket函数来发送数据:
? ssize_t write(int fd, const void *buf, size_t count);
? ssize_t send(int s, const void *buf, size_t len, int flags);
? ssize_t sendto(int s, const void *buf, size_t len, int flags, const struct sockaddr *to, socklen_t tolen);
? ssize_t sendmsg(int s, const struct msghdr *msg, int flags);
? int sendmmsg(int s, struct mmsghdr *msgvec, unsigned int vlen, unsigned int flags);
? 这些发送函数有什么区别呢?当flags为0时,send()和write()功能相同。send(s, buf, len, flags)和sendto(s, buf, len, flags, NULL, 0)功能相同。write()和send()在套接字处于连接状态时可以使用,而sendto()、sendmsg()和sendmmsg()在任何时候都可用。
? 用户层的数据最终都是以消息头来描述的。
struct msghdr {
void *msg_name; /* optional address,目的地址 */
socklen_t msg_namelen; /* size of address,目的地址的长度 */
struct iovec *msg_iov; /* scatter/gather array,分散的数据块数组 */
size_t msg_iovlen; /* #elements in msg_iov,分散的数据块个数 */
void *msg_control; /* ancillary data, 控制数据 */
socklen_t msg_controllen; /* ancillary data buffer len,控制数据的长度 */
int msg_flags; /* flags on received message */
};
/* Structure for scatter/gather I/O. */
struct iovec {
void *iov_base; /* Pointer to data. */
size_t iov_len; /* Length of data. */
};
系统调用
发送函数是由glibc提供的,声明位于include/sys/socket.h中,实现位于sysdeps/mach/hurd/connect.c中,
主要是用来从用户空间进入名为sys_socketcall的系统调用,并传递参数。sys_socketcall()实际上是所有
socket函数进入内核空间的共同入口。
SYSCALL_DEFINE2(socketcall, int, call, unsigned long __user *, args)
{
...
switch(call) {
...
case SYS_SEND:
err = sys_send(a0, (void __user *)a1, a[2], a[3]);
break;
case SYS_SENDTO:
err = sys_sendto(a0, (void __user *)a1 a[2], a[3], (struct sockaddr __user *)a[4], a[5]);
break;
...
case SYS_SENDMSG:
err = sys_sendmsg(a0, (struct msghdr __user *)a1, a[2]);
break;
case SYS_SENDMMSG:
err = sys_sendmmsg(a0, (struct msghdr __user *)a1, a[2], a[3]);
break;
...
}
}
send()其实是sendto()的一种特殊情况。
SYSCALL_DEFINE4(send, int, fd, void __user *, buff, size_t, len, unsigned, flags)
{
return sys_sendto(fd, buff, len, flags, NULL, 0);
}
sendto()初始化了消息头,接着就调用sock_sendmsg()来处理。
/* Send a datagram to a given address. We move the address into kernel space
* and check the user space data area is readable before invoking the protocol.
*/
SYSCALL_DEFINE6(sendto, int, fd, void __user *, buff, size_t, len, unsigned, flags,
struct sockaddr __user *, addr, int, addr_len)
{
struct socket *sock;
struct sockaddr_storage address;
int err;
struct msghdr msg;
struct iovec iov;
int fput_needed;
if (len > INT_MAX)
len = INT_MAX;
/* 通过文件描述符fd,找到对应的socket实例。
* 以fd为索引从当前进程的文件描述符表files_struct实例中找到对应的file实例,
* 然后从file实例的private_data成员中获取socket实例
*/
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (! sock)
goto out;
/* 初始化消息头 */
iov.iov_base = buff;
iov.iov_len = len;
msg.msg_name = NULL;
msg.msg_iov = &iov;
msg.msg_iovlen = 1; /* 只有一个数据块 */
msg.msg_control = NULL;
msg.msg_controllen = 0;
msg.msg_namelen = 0;
if (addr) {
/* 把套接字地址从用户空间拷贝到内核空间 */
err = move_addr_to_kernel(addr, addr_len, &address);
if (err < 0)
goto out_put;
msg.msg_name = (struct sockaddr *)&address;
msg.msg_namelen = addr_len;
}
/* 如果设置了非阻塞标志 */
if (sock->file->f_flags & O_NONBLOCK)
flags |= MSG_DONTWAIT;
msg.msg_flags = flags;
/* 调用统一的发送入口函数sock_sendmsg() */
err = sock_sendmsg(sock , &msg, len);
out_put:
fput_light(sock->file, fput_needed);
out:
return err;
}
struct msghdr {
void *msg_name; /* ptr to socket address structure */
int msg_namelen; /* size of socket address structure */
struct iovec *msg_iov; /* scatter/gather array,分散的数据块数组 */
__kernel_size_t msg_iovlen; /* #elements in msg_iov,分散的数据块个数 */
void *msg_control; /* ancillary data, 控制数据 */
__kernel_size_t msg_controllen; /* ancillary data buffer len,控制数据的长度 */
unsigned int msg_flags; /* flags on received message */
};
/* Structure for scatter/gather I/O. */
struct iovec {
void *iov_base; /* Pointer to data. */
__kernel_size_t iov_len; /* Length of data. */
};
/* For recvmmsg/ sendmmsg */
struct mmsghdr {
struct msghdr msg_hdr;
unsigned int msg_len;
};
sock_sendmsg()在初始化异步IO控制块后,调用__sock_sendmsg()。
int sock_sendmsg(struct socket *sock, struct msghdr *msg, size_t size)
{
struct kiocb iocb;
init_sync_kiocb(&iocb, NULL);
iocb.private = &siocb;
ret = __sock_sendmsg(&iocb, sock, msg, size);
/* iocb queued, will get completion event */
if (-EIOCBQUEUED == ret)
ret = wait_on_sync_kiocb(&iocb);
return ret;
}
/* AIO控制块 */
struct kiocb {
struct file *ki_filp;
struct kioctx *ki_ctx; /* NULL for sync ops,如果是同步的则为NULL */
kiocb_cancel_fn *ki_cancel;
void *private; /* 指向sock_iocb */
union {
void __user *user;
struct task_struct *tsk; /* 执行io的进程 */
} ki_obj;
__u64 ki_user_data; /* user‘s data for completion */
loff_t ki_pos;
size_t ki_nbytes; /* copy of iocb->aio_nbytes */
struct list_head ki_list; /* the aio core uses this for cancellation */
/* If the aio_resfd field of the userspace iocb is not zero,
* this is the underlying eventfd context to deliver events to.
*/
struct eventfd_ctx *ki_eventfd;
};
__sock_sendmsg()会调用Socket层的发送函数,如果是SOCK_STREAM,
那么接着就调用inet_sendmsg()处理。
static inline int __sock_sendmsg(struct kiocb *iocb, struct socket *sock,
struct msghdr *msg, size_t size)
{
int err = security_socket_sendmsg(sock, msg, size);
return err ?: __sock_sendmsg_nosec(iocb, sock, msg, size);
}
static inline int __sock_sendmsg_nosec(struct kiocb *iocb, struct socket *sock,
struct msghdr *msg, size_t size)
{
struct sock_iocb *si = kiocb_to_siocb(iocb);
si->sock = sock;
si->scm = NULL;
si->msg = msg;
si->size = size;
/* 调用Socket层的操作函数,如果是SOCK_STREAM,则proto_ops为inet_stream_ops,
* 函数指针指向inet_sendmsg()。
*/
return sock->ops->sendmsg(iocb, sock, msg, size);
}
sendmsg()和sendmmsg()在系统调用函数中也是拷贝用户空间的数据到内核消息头,最后调用
Socket层的发送函数inet_sendmsg()进行下一步处理,这里不再赘述。
Socket层
SOCK_STREAM套接口的socket层操作函数集实例为inet_stream_ops,其中发送函数为inet_sendmsg()。
const struct proto_ops inet_stream_ops = {
.family = PF_INET,
.owner = THIS_MODULE,
...
.sendmsg = inet_sendmsg,
...
};
inet_sendmsg()主要调用TCP层的发送函数tcp_sendmsg()来处理。
int inet_sendmsg(struct kiocb *iocb, struct socket *sock, struct msghdr *msg, size_t size)
{
struct sock *sk = sock->sk;
sock_rps_record_flow(sk);
/* We may need to bnd the socket.
* 如果连接还没有分配本地端口,且允许自动绑定,那么给连接绑定一个本地端口。
* tcp_prot的no_autobaind为true,所以TCP是不允许自动绑定端口的。
*/
if (! inet_sk(sk)->inet_num && ! sk->sk_prot->no_autobind && inet_autobind(s))
return -EAGAIN;
/* 如果传输层使用的是TCP,则sk_prot为tcp_prot,sendmsg指向tcp_sendmsg() */
return sk->sk_prot->sendmsg(iocb, sk, msg, size);
}
/* Automatically bind an unbound socket. */
static int inet_autobind(struct sock *sk)
{
struct inet_sock *inet;
/* We may need to bind the socket. */
lock_sock(sk);
/* 如果还没有分配本地端口 */
if (! inet->inet_num) {
/* SOCK_STREAM套接口的TCP操作函数集为tcp_prot,其中端口绑定函数为
* inet_csk_get_port()。
*/
if (sk->sk_prot->get_port(sk, 0)) {
release_sock(sk);
return -EAGAIN;
}
inet->inet_sport = htons(inet->inet_num);
}
release_sock(sk);
return 0;
}
tcp_sendmsg实际上调用的是int tcp_sendmsg_locked(struct sock *sk, struct msghdr *msg, size_t size)。
int tcp_sendmsg_locked(struct sock *sk, struct msghdr *msg, size_t size)
{
struct tcp_sock *tp = tcp_sk(sk);/*进行了强制类型转换*/
struct sk_buff *skb;
flags = msg->msg_flags;
......
if (copied)
tcp_push(sk, flags & ~MSG_MORE, mss_now,
TCP_NAGLE_PUSH, size_goal);
}
在tcp_sendmsg_locked中,完成的是将所有的数据组织成发送队列,这个发送队列是struct sock结构中的一个域sk_write_queue,这个队列的每一个元素是一个skb,里面存放的就是待发送的数据。然后调用了tcp_push()函数。
struct sock{
...
struct sk_buff_head sk_write_queue;/*指向skb队列的第一个元素*/
...
struct sk_buff *sk_send_head;/*指向队列第一个还没有发送的元素*/
}
在tcp协议的头部有几个标志字段:URG、ACK、RSH、RST、SYN、FIN,tcp_push中会判断这个skb的元素是否需要push,如果需要就将tcp头部字段的push置一,置一的过程如下:
static void tcp_push(struct sock *sk, int flags, int mss_now,
int nonagle, int size_goal)
{
struct tcp_sock *tp = tcp_sk(sk);
struct sk_buff *skb;
skb = tcp_write_queue_tail(sk);
if (!skb)
return;
if (!(flags & MSG_MORE) || forced_push(tp))
tcp_mark_push(tp, skb);
tcp_mark_urg(tp, flags);
if (tcp_should_autocork(sk, skb, size_goal)) {
/* avoid atomic op if TSQ_THROTTLED bit is already set */
if (!test_bit(TSQ_THROTTLED, &sk->sk_tsq_flags)) {
NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPAUTOCORKING);
set_bit(TSQ_THROTTLED, &sk->sk_tsq_flags);
}
/* It is possible TX completion already happened
* before we set TSQ_THROTTLED.
*/
if (refcount_read(&sk->sk_wmem_alloc) > skb->truesize)
return;
}
if (flags & MSG_MORE)
nonagle = TCP_NAGLE_CORK;
__tcp_push_pending_frames(sk, mss_now, nonagle);
}
整个过程会有点绕,首先struct tcp_skb_cb结构体存放的就是tcp的头部,头部的控制位为tcp_flags,通过tcp_mark_push会将skb中的cb,也就是48个字节的数组,类型转换为struct tcp_skb_cb,这样位于skb的cb就成了tcp的头部。
static inline void tcp_mark_push(struct tcp_sock *tp, struct sk_buff *skb)
{
TCP_SKB_CB(skb)->tcp_flags |= TCPHDR_PSH;
tp->pushed_seq = tp->write_seq;
}
...
#define TCP_SKB_CB(__skb) ((struct tcp_skb_cb *)&((__skb)->cb[0]))
...
struct sk_buff {
...
char cb[48] __aligned(8);
...
struct tcp_skb_cb {
__u32 seq; /* Starting sequence number */
__u32 end_seq; /* SEQ + FIN + SYN + datalen */
__u8 tcp_flags; /* tcp头部标志,位于第13个字节tcp[13]) */
......
};
然后,tcp_push调用了__tcp_push_pending_frames(sk, mss_now, nonagle);函数发送数据:
void __tcp_push_pending_frames(struct sock *sk, unsigned int cur_mss,
int nonagle)
{
if (tcp_write_xmit(sk, cur_mss, nonagle, 0,
sk_gfp_mask(sk, GFP_ATOMIC)))
tcp_check_probe_timer(sk);
}
随后又调用了tcp_write_xmit来发送数据:
static bool tcp_write_xmit(struct sock *sk, unsigned int mss_now, int nonagle,
int push_one, gfp_t gfp)
{
struct tcp_sock *tp = tcp_sk(sk);
struct sk_buff *skb;
unsigned int tso_segs, sent_pkts;
int cwnd_quota;
int result;
bool is_cwnd_limited = false, is_rwnd_limited = false;
u32 max_segs;
/*统计已发送的报文总数*/
sent_pkts = 0;
......
/*若发送队列未满,则准备发送报文*/
while ((skb = tcp_send_head(sk))) {
unsigned int limit;
if (unlikely(tp->repair) && tp->repair_queue == TCP_SEND_QUEUE) {
/* "skb_mstamp_ns" is used as a start point for the retransmit timer */
skb->skb_mstamp_ns = tp->tcp_wstamp_ns = tp->tcp_clock_cache;
list_move_tail(&skb->tcp_tsorted_anchor, &tp->tsorted_sent_queue);
tcp_init_tso_segs(skb, mss_now);
goto repair; /* Skip network transmission */
}
if (tcp_pacing_check(sk))
break;
tso_segs = tcp_init_tso_segs(skb, mss_now);
BUG_ON(!tso_segs);
/*检查发送窗口的大小*/
cwnd_quota = tcp_cwnd_test(tp, skb);
if (!cwnd_quota) {
if (push_one == 2)
/* Force out a loss probe pkt. */
cwnd_quota = 1;
else
break;
}
if (unlikely(!tcp_snd_wnd_test(tp, skb, mss_now))) {
is_rwnd_limited = true;
break;
......
limit = mss_now;
if (tso_segs > 1 && !tcp_urg_mode(tp))
limit = tcp_mss_split_point(sk, skb, mss_now,
min_t(unsigned int,
cwnd_quota,
max_segs),
nonagle);
if (skb->len > limit &&
unlikely(tso_fragment(sk, TCP_FRAG_IN_WRITE_QUEUE,
skb, limit, mss_now, gfp)))
break;
if (tcp_small_queue_check(sk, skb, 0))
break;
if (unlikely(tcp_transmit_skb(sk, skb, 1, gfp)))
break;
......
tcp_write_xmit`位于tcpoutput.c中,它实现了tcp的拥塞控制,然后调用了`tcp_transmit_skb(sk, skb, 1, gfp)`传输数据,实际上调用的是`__tcp_transmit_skb
static int __tcp_transmit_skb(struct sock *sk, struct sk_buff *skb,
int clone_it, gfp_t gfp_mask, u32 rcv_nxt)
{
skb_push(skb, tcp_header_size);
skb_reset_transport_header(skb);
......
/* 构建TCP头部和校验和 */
th = (struct tcphdr *)skb->data;
th->source = inet->inet_sport;
th->dest = inet->inet_dport;
th->seq = htonl(tcb->seq);
th->ack_seq = htonl(rcv_nxt);
tcp_options_write((__be32 *)(th + 1), tp, &opts);
skb_shinfo(skb)->gso_type = sk->sk_gso_type;
if (likely(!(tcb->tcp_flags & TCPHDR_SYN))) {
th->window = htons(tcp_select_window(sk));
tcp_ecn_send(sk, skb, th, tcp_header_size);
} else {
/* RFC1323: The window in SYN & SYN/ACK segments
* is never scaled.
*/
th->window = htons(min(tp->rcv_wnd, 65535U));
}
......
icsk->icsk_af_ops->send_check(sk, skb);
if (likely(tcb->tcp_flags & TCPHDR_ACK))
tcp_event_ack_sent(sk, tcp_skb_pcount(skb), rcv_nxt);
if (skb->len != tcp_header_size) {
tcp_event_data_sent(tp, sk);
tp->data_segs_out += tcp_skb_pcount(skb);
tp->bytes_sent += skb->len - tcp_header_size;
}
if (after(tcb->end_seq, tp->snd_nxt) || tcb->seq == tcb->end_seq)
TCP_ADD_STATS(sock_net(sk), TCP_MIB_OUTSEGS,
tcp_skb_pcount(skb));
tp->segs_out += tcp_skb_pcount(skb);
/* OK, its time to fill skb_shinfo(skb)->gso_{segs|size} */
skb_shinfo(skb)->gso_segs = tcp_skb_pcount(skb);
skb_shinfo(skb)->gso_size = tcp_skb_mss(skb);
/* Leave earliest departure time in skb->tstamp (skb->skb_mstamp_ns) */
/* Cleanup our debris for IP stacks */
memset(skb->cb, 0, max(sizeof(struct inet_skb_parm),
sizeof(struct inet6_skb_parm)));
err = icsk->icsk_af_ops->queue_xmit(sk, skb, &inet->cork.fl);
......
}
tcp_transmit_skb是tcp发送数据位于传输层的最后一步,这里首先对TCP数据段的头部进行了处理,然后调用了网络层提供的发送接口icsk->icsk_af_ops->queue_xmit(sk, skb, &inet->cork.fl);实现了数据的发送,自此,数据离开了传输层,传输层的任务也就结束了。
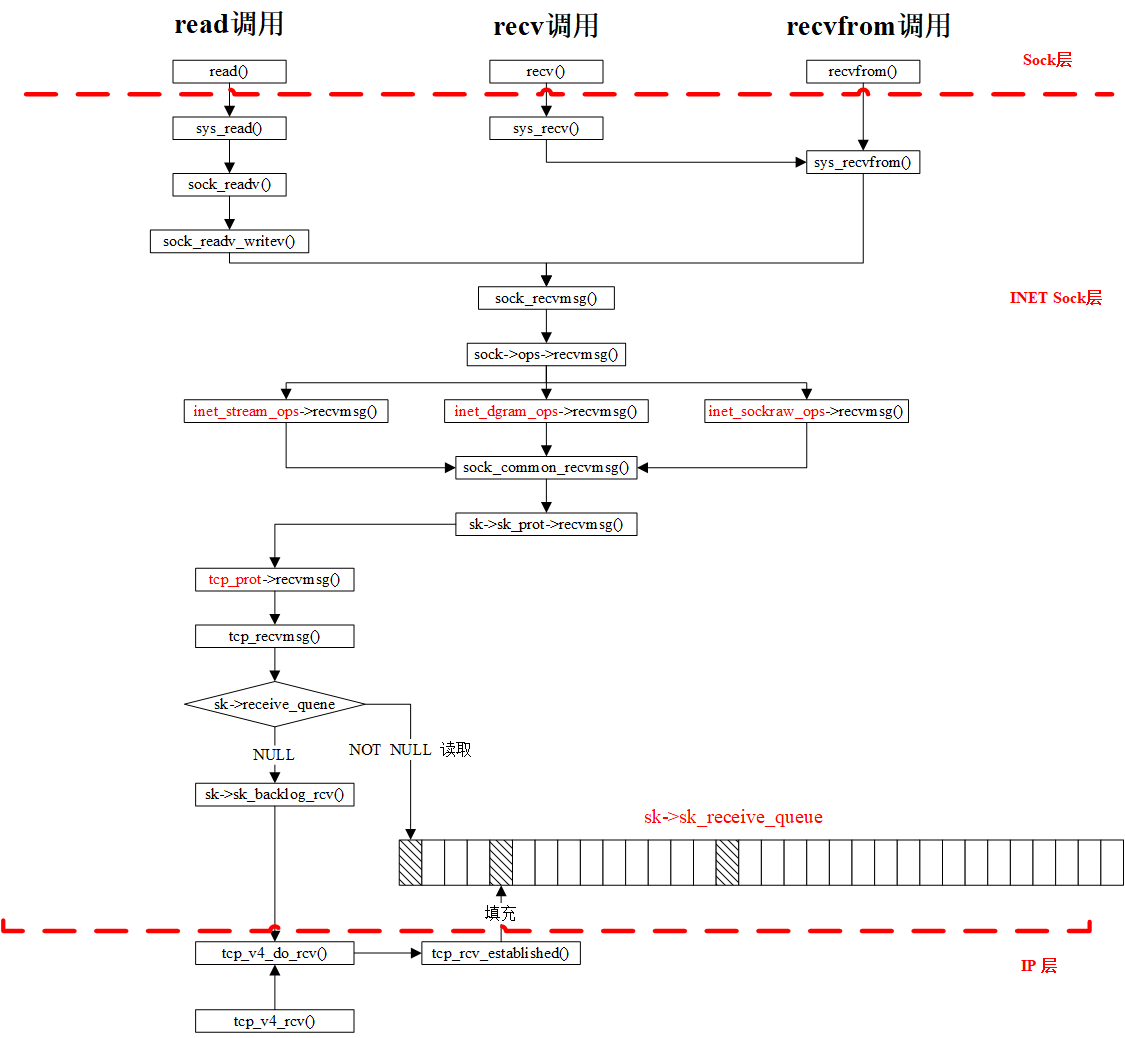
对于recv函数,与send类似,自然也是recvfrom的特殊情况,调用的也就是__sys_recvfrom,整个函数的调用路径与send非常类似:
int __sys_recvfrom(int fd, void __user *ubuf, size_t size, unsigned int flags,
struct sockaddr __user *addr, int __user *addr_len)
{
......
err = import_single_range(READ, ubuf, size, &iov, &msg.msg_iter);
if (unlikely(err))
return err;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
.....
msg.msg_control = NULL;
msg.msg_controllen = 0;
/* Save some cycles and don‘t copy the address if not needed */
msg.msg_name = addr ? (struct sockaddr *)&address : NULL;
/* We assume all kernel code knows the size of sockaddr_storage */
msg.msg_namelen = 0;
msg.msg_iocb = NULL;
msg.msg_flags = 0;
if (sock->file->f_flags & O_NONBLOCK)
flags |= MSG_DONTWAIT;
err = sock_recvmsg(sock, &msg, flags);
if (err >= 0 && addr != NULL) {
err2 = move_addr_to_user(&address,
msg.msg_namelen, addr, addr_len);
.....
}
__sys_recvfrom调用了sock_recvmsg来接收数据,整个函数实际调用的是sock->ops->recvmsg(sock, msg, msg_data_left(msg), flags);,同样,根据tcp_prot结构的初始化,调用的其实是tcp_rcvmsg
.接受函数比发送函数要复杂得多,因为数据接收不仅仅只是接收,tcp的三次握手也是在接收函数实现的,所以收到数据后要判断当前的状态,是否正在建立连接等,根据发来的信息考虑状态是否要改变,在这里,我们仅仅考虑在连接建立后数据的接收。
int tcp_recvmsg(struct sock *sk, struct msghdr *msg, size_t len, int nonblock,
int flags, int *addr_len)
{
......
if (sk_can_busy_loop(sk) && skb_queue_empty(&sk->sk_receive_queue) &&
(sk->sk_state == TCP_ESTABLISHED))
sk_busy_loop(sk, nonblock);
lock_sock(sk);
.....
if (unlikely(tp->repair)) {
err = -EPERM;
if (!(flags & MSG_PEEK))
goto out;
if (tp->repair_queue == TCP_SEND_QUEUE)
goto recv_sndq;
err = -EINVAL;
if (tp->repair_queue == TCP_NO_QUEUE)
goto out;
......
last = skb_peek_tail(&sk->sk_receive_queue);
skb_queue_walk(&sk->sk_receive_queue, skb) {
last = skb;
......
if (!(flags & MSG_TRUNC)) {
err = skb_copy_datagram_msg(skb, offset, msg, used);
if (err) {
/* Exception. Bailout! */
if (!copied)
copied = -EFAULT;
break;
}
}
*seq += used;
copied += used;
len -= used;
tcp_rcv_space_adjust(sk);
这里共维护了三个队列:prequeue、backlog、receive_queue,分别为预处理队列,后备队列和接收队列,在连接建立后,若没有数据到来,接收队列为空,进程会在sk_busy_loop函数内循环等待,知道接收队列不为空,并调用函数数skb_copy_datagram_msg将接收到的数据拷贝到用户态,实际调用的是__skb_datagram_iter,这里同样用了struct msghdr *msg来实现。
int __skb_datagram_iter(const struct sk_buff *skb, int offset,
struct iov_iter *to, int len, bool fault_short,
size_t (*cb)(const void *, size_t, void *, struct iov_iter *),
void *data)
{
int start = skb_headlen(skb);
int i, copy = start - offset, start_off = offset, n;
struct sk_buff *frag_iter;
/* 拷贝tcp头部 */
if (copy > 0) {
if (copy > len)
copy = len;
n = cb(skb->data + offset, copy, data, to);
offset += n;
if (n != copy)
goto short_copy;
if ((len -= copy) == 0)
return 0;
}
/* 拷贝数据部分 */
for (i = 0; i < skb_shinfo(skb)->nr_frags; i++) {
int end;
const skb_frag_t *frag = &skb_shinfo(skb)->frags[i];
WARN_ON(start > offset + len);
end = start + skb_frag_size(frag);
if ((copy = end - offset) > 0) {
struct page *page = skb_frag_page(frag);
u8 *vaddr = kmap(page);
if (copy > len)
copy = len;
n = cb(vaddr + frag->page_offset +
offset - start, copy, data, to);
kunmap(page);
offset += n;
if (n != copy)
goto short_copy;
if (!(len -= copy))
return 0;
}
start = end;
}
拷贝完成后,函数返回,整个接收的过程也就完成了。
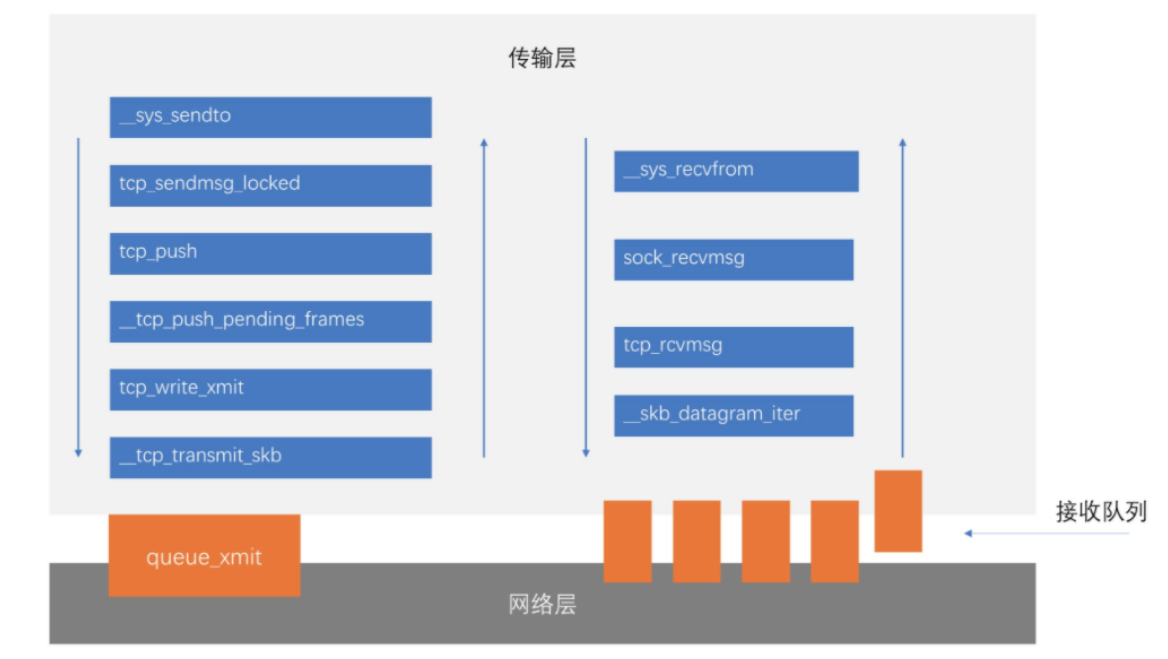
接下来用gdb调试验证上面的分析,
首先看send的调用关系,分别将断点打在__sys_sendto、tcp_sendmsg_locked、tcp_push、__tcp_push_pending_frames、tcp_write_xmit、__tcp_transmit_skb。观察函数的调用顺序,与我们的分析是否一致。
(gdb) file vmlinux
Reading symbols from vmlinux...done.
warning: File "/home/netlab/netlab/linux-5.2.7/scripts/gdb/vmlinux-gdb.py" auto-loading has been declined by your `auto-load safe-path‘ set to "$debugdir:$datadir/auto-load".
To enable execution of this file add
add-auto-load-safe-path /home/netlab/netlab/linux-5.2.7/scripts/gdb/vmlinux-gdb.py
line to your configuration file "/home/netlab/.gdbinit".
To completely disable this security protection add
set auto-load safe-path /
line to your configuration file "/home/netlab/.gdbinit".
For more information about this security protection see the
"Auto-loading safe path" section in the GDB manual. E.g., run from the shell:
info "(gdb)Auto-loading safe path"
(gdb) target remote: 1234
Remote debugging using : 1234
0x0000000000000000 in fixed_percpu_data ()
(gdb) c
Continuing.
^C
Program received signal SIGINT, Interrupt.
default_idle () at arch/x86/kernel/process.c:581
581 trace_cpu_idle_rcuidle(PWR_EVENT_EXIT, smp_processor_id());
(gdb) b __sys_sendto
Breakpoint 1 at 0xffffffff817ef560: file net/socket.c, line 1929.
(gdb) b tcp_sendmsg_locked
Breakpoint 2 at 0xffffffff81895000: file net/ipv4/tcp.c, line 1158.
(gdb) b tcp_push
Breakpoint 3 at 0xffffffff818907c0: file ./include/linux/skbuff.h, line 1766.
(gdb) b __tcp_push_pending_frames
Breakpoint 4 at 0xffffffff818a44a0: file net/ipv4/tcp_output.c, line 2584.
(gdb) b tcp_wrtie_xmit
Function "tcp_wrtie_xmit" not defined.
Make breakpoint pending on future shared library load? (y or [n]) n
(gdb) b tcp_write_xmit
Breakpoint 5 at 0xffffffff818a32d0: file net/ipv4/tcp_output.c, line 2330.
(gdb) b __tcp_transmit_skb
Breakpoint 6 at 0xffffffff818a2830: file net/ipv4/tcp_output.c, line 1015.
(gdb)
执行client命令,观察程序暂停的位置:
Breakpoint 6, __tcp_transmit_skb (sk=0xffff888006478880,
skb=0xffff888006871400, clone_it=1, gfp_mask=3264, rcv_nxt=0)
at net/ipv4/tcp_output.c:1015
1015 {
(gdb)
并非我们预想的那样,程序停在了__tcp_transmit_skb,但仔细分析,这应该是三次握手的过程,继续调试
Breakpoint 6, __tcp_transmit_skb (sk=0xffff888006478880,
skb=0xffff888006871400, clone_it=1, gfp_mask=3264, rcv_nxt=0)
at net/ipv4/tcp_output.c:1015
1015 {
(gdb) c
Continuing.
Breakpoint 6, __tcp_transmit_skb (sk=0xffff888006478880,
skb=0xffff88800757a100, clone_it=0, gfp_mask=0, rcv_nxt=1155786088)
at net/ipv4/tcp_output.c:1015
1015 {
(gdb) c
Continuing.
又有两次停在了这里,恰恰验证了猜想,因为这个程序的服务端和客户端都在同一台主机上,共用了同一个TCP协议栈,在TCP三次握手时,客户端发送两次,服务端发送一次,恰好三次。下面我们用客户端向服务器端发送,分析程序的调用过程:
Breakpoint 1, __sys_sendto (fd=5, buff=0x7ffc33c54bc0, len=2, flags=0,
addr=0x0 <fixed_percpu_data>, addr_len=0) at net/socket.c:1929
1929 {
(gdb) c
Continuing.
Breakpoint 2, tcp_sendmsg_locked (sk=0xffff888006479100,
msg=0xffffc900001f7e28, size=2) at net/ipv4/tcp.c:1158
1158 {
(gdb) c
Continuing.
Breakpoint 3, tcp_push (sk=0xffff888006479100, flags=0, mss_now=32752,
nonagle=0, size_goal=32752) at net/ipv4/tcp.c:699
699 skb = tcp_write_queue_tail(sk);
(gdb) c
Continuing.
Breakpoint 4, __tcp_push_pending_frames (sk=0xffff888006479100, cur_mss=32752,
nonagle=0) at net/ipv4/tcp_output.c:2584
2584 if (unlikely(sk->sk_state == TCP_CLOSE))
(gdb) c
Continuing.
Breakpoint 5, tcp_write_xmit (sk=0xffff888006479100, mss_now=32752, nonagle=0,
push_one=0, gfp=2592) at net/ipv4/tcp_output.c:2330
2330 {
(gdb) c
Continuing.
Breakpoint 6, __tcp_transmit_skb (sk=0xffff888006479100,
skb=0xffff888006871400, clone_it=1, gfp_mask=2592, rcv_nxt=405537035)
at net/ipv4/tcp_output.c:1015
1015 {
(gdb) c
Continuing.
Breakpoint 6, __tcp_transmit_skb (sk=0xffff888006478880,
skb=0xffff88800757a100, clone_it=0, gfp_mask=0, rcv_nxt=1155786090)
at net/ipv4/tcp_output.c:1015
1015 {
(gdb) c
可以看到,与我们分析的顺序是一致的,但是最后__tcp_transmit_skb调用了两次,经过仔细分析,终于找到原因——这是接收方接收到数据后发送ACK使用的。
验证完send,来验证一下recv
将断点分别设在:
__sys_recvfrom、sock_recvmsg、tcp_rcvmsg、__skb_datagram_iter处,以同样的方式观察:
Breakpoint 1, __sys_recvfrom (fd=5, ubuf=0x7ffd9428d960, size=1024, flags=0,
addr=0x0 <fixed_percpu_data>, addr_len=0x0 <fixed_percpu_data>)
at net/socket.c:1990
1990 {
(gdb) c
Continuing.
Breakpoint 2, sock_recvmsg (sock=0xffff888006df1900, msg=0xffffc900001f7e28,
flags=0) at net/socket.c:891
891 {
(gdb) c
Continuing.
Breakpoint 3, tcp_recvmsg (sk=0xffff888006479100, msg=0xffffc900001f7e28,
len=1024, nonblock=0, flags=0, addr_len=0xffffc900001f7df4)
at net/ipv4/tcp.c:1933
1933 {
(gdb) c
在未发送之前,程序也会暂停在断点处,根据之前的分析,这也是三次握手的过程,但是为什么没有__skb_datagram_iter呢?,因为三次握手时,并没有发送数据过来,所以并没有数据被拷贝到用户空间。
同样,尝试发送数据观察调用过程。
Breakpoint 1, __sys_recvfrom (fd=5, ubuf=0x7ffd9428d960, size=1024, flags=0,
addr=0x0 <fixed_percpu_data>, addr_len=0x0 <fixed_percpu_data>)
at net/socket.c:1990
1990 {
(gdb) c
Continuing.
Breakpoint 2, sock_recvmsg (sock=0xffff888006df1900, msg=0xffffc900001f7e28,
flags=0) at net/socket.c:891
891 {
(gdb) c
Continuing.
Breakpoint 3, tcp_recvmsg (sk=0xffff888006479100, msg=0xffffc900001f7e28,
len=1024, nonblock=0, flags=0, addr_len=0xffffc900001f7df4)
at net/ipv4/tcp.c:1933
1933 {
(gdb) c
Continuing.
Breakpoint 4, __skb_datagram_iter (skb=0xffff8880068714e0, offset=0,
to=0xffffc900001efe38, len=2, fault_short=false,
cb=0xffffffff817ff860 <simple_copy_to_iter>, data=0x0 <fixed_percpu_data>)
at net/core/datagram.c:414
414 {
验证完毕。
发送端send
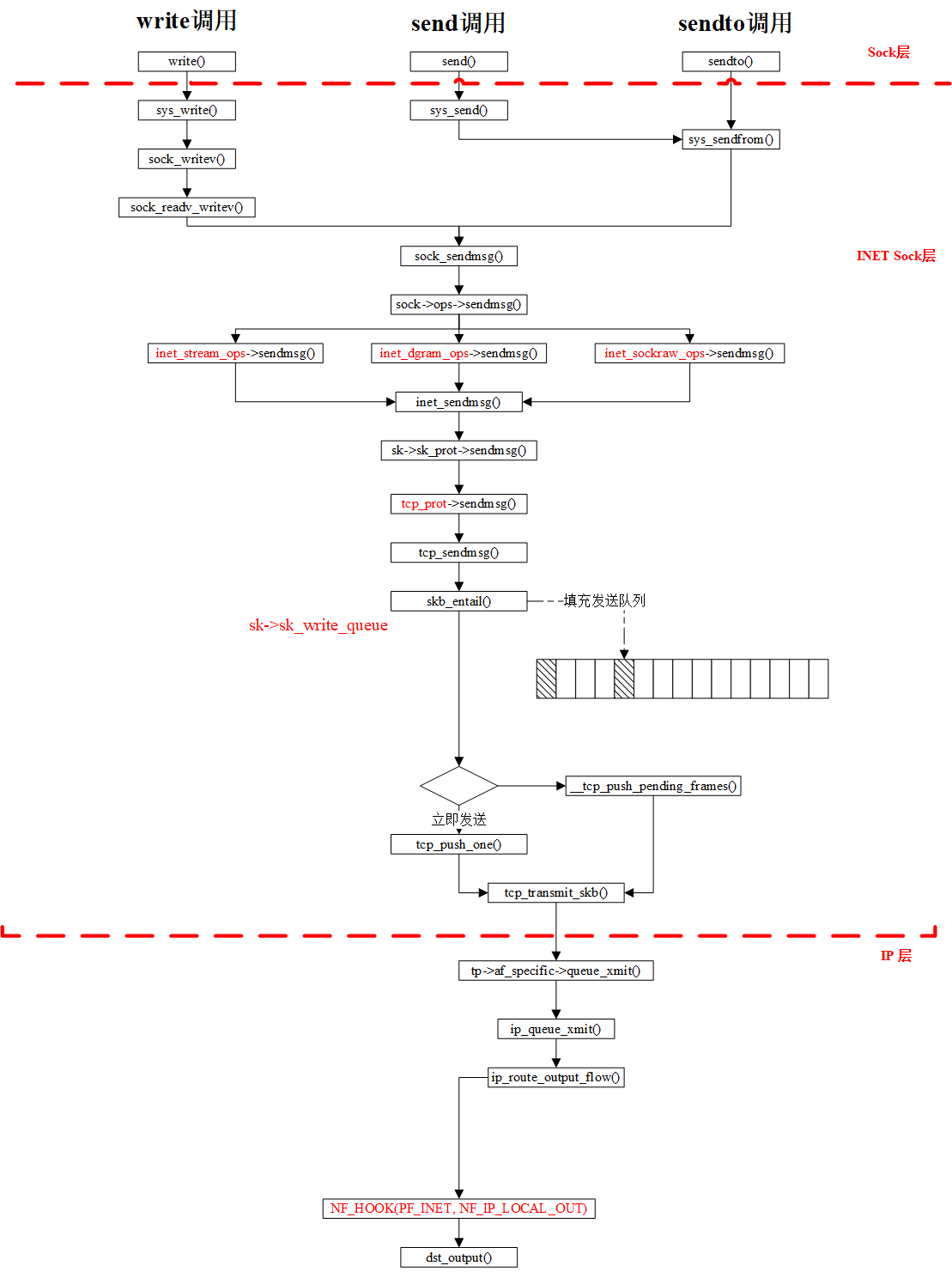
接收端recv:
原文:https://www.cnblogs.com/robin797/p/14350160.html