论文地址:https://arxiv.org/pdf/1810.05102.pdf
代码地址(theano):https://github.com/pgcool/Cross-sentence-Relation-Extraction-iDepNN
Abstract
本文提出了一种新的方法用于跨句子的关系抽取—iDepNN:inter-sentential dependency-based neural networks
iDepNN通过循环和递归神经网络对最短和增强的依赖路径进行建模,以提取句子内部和跨(句间)句子边界的关系。
相比于之前SVM和神经网络的baseline,iDepNN对于处理句际关系的假正例更加的鲁棒性。
该模型在基于新闻专线(MUC6)和医学领域(BioNLP)的四个数据集中取得了state-of-the-art,并且对于句内关系在精确率和召回率方面更平衡。
1 Introduction
Paul Allen has started a company and named [Vern Raburn]e1 its President. The company, to be called [Paul Allen Group]e2 will be based in Bellevue, Washington.
本文的贡献:
3 Methodology
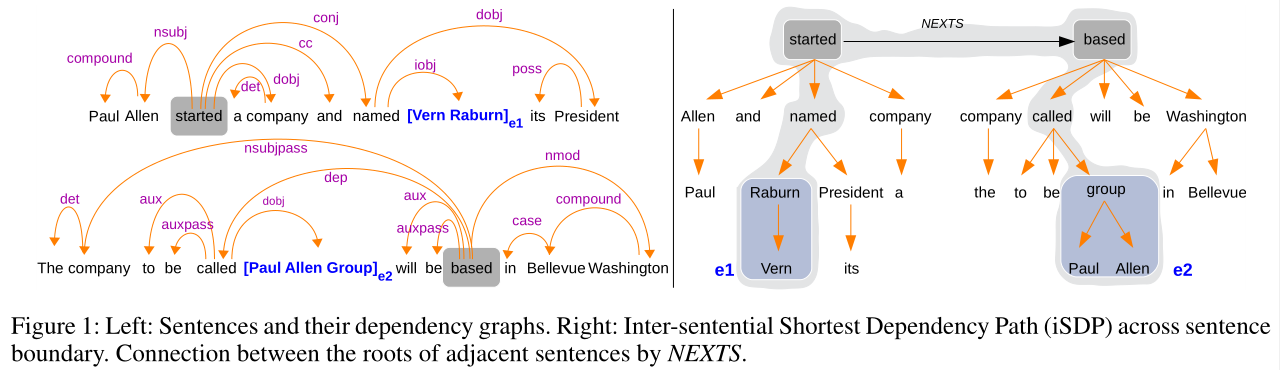
如上图1所示,左图显示的是例句中实体1和实体2对应的依存图。右图中显示的是这两个相邻句子的依存树,并且它们的根节点通过NETXS相连,进而在两个实体间形成了一个iSDP(inter-Sentential Dependency Path),如图中深色的阴影部分所示。
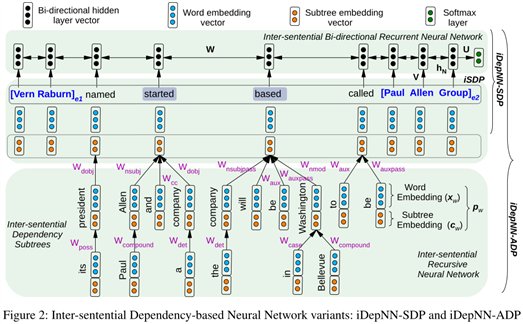
图2展示了biRNN使用iSDP去检测实体1和实体2之间的关系。
为了有效的表示句子最短依存路径中的单词,本文对依存子树进行建模。
??基于的观点为:每个单词w可以看作是单词本身和依存子树上它的孩子节点。
??The notion of representing words using subtree vectors within the dependency neural network (DepNN) is similar to (Liu et al. 2015); however, our proposed structures are based on iSDPs and ADPs that span sentences.
对于子树上的每个单词$w$的表示,它的词嵌入向量$x_w\in R^d$,子树表示为$c_w\in R^{d^{‘}}$,
此处使用200维的预训练Glove词嵌入(Pennington, Socher, and Manning 2014).
??对于单词的子树表示,对它的孩子节点使用递归(recurisive)计算单词的子树表示。使用RecNN去构建子树嵌入$c_w$,通过自底向上(从叶子节点到根节点)的方法进行构建,如图2所示。对于叶子节点而言,它是没有子树的,所以设置为$c_{LEAF}$,图2展示了如何通过iSDP构建基于子树的单词表示。
在自底向上的构建子树的过程中,每一个单词都会与一个依存关系$r$(例如 r=dobj)有关。对于每一个$r$,转移矩阵为$W_r\in R^{d^{‘}*(d+d^{‘})}$,此矩阵事需要学习的,子树嵌入计算如下:
$c_w=f(\sum_{q\in Children}W_{R(w,q)}·P_q+b) and P_q=[x_q,c_q$
其中,R_{(w,q)}是单词$w$和它的孩子节点单词$q$的依存关系,$b\in R^{d^{‘}}$是一个偏置项。这个过程会 持续递归到根节点(例如图中的单词节点“named”)。
??Following Liu et al. (2015),此处结合两个部分:iSDP和dpendency subtrees,形成一个组合结构:inter-sentential Augmented Dependency Path (iDepNN-ADP)。
??如图2所示,每一个单词都附加了它的子树表示$c_w$,附加的子树丰富了iSDP上的每个单词以及关于该单词如何在特定句子中起作用的附加信息,以形成用于对句子内和句子之间的关系进行分类的更精确的结构。
??为了捕获iDepNN-ADP的语义表示,本文首先采用RecNN对iSDP中的每个单词的依存子树进行建模,然后设计了一个biRNN来获得iSDP上的显著语义特征。iDepNN-ADP的整体结构如图2所示,它是通过结合recursive and recurrent NNs构建的。
??本文对于iDepNN-SDP和iDepNN-ADP这两个结构采用biRNN方法,并且将最后的隐藏向量$h_N$(如图2中的iSDP的单词序列)放入到一个softmax层,softmax层的输出是对于关系标签R的概率分布$y$,$y=softmax(U·h_N+b_y)$,其中$U\in R^{R*H}$是连接H维隐藏向量和R维的输出层的权重矩阵,$b_y\in R^{R}$是偏置项,$h_N$是biRNN的最后隐藏向量。
为了计算了iSDP中每个单词w的语义表示$h_w$,此处采用Connectionist biRNN (Vu et al.2016a),通过在每个时间步t添加它们的隐藏层$(h_{f_t}和h_{b_t})$来组合前向和后向传递,并且还将加权连接添加到先前组合的隐藏层$h_{t-1}$以将所有中间隐藏层包括到最终决策中。
$h_{f_t}=f(V·i_t+W·h_{f_{t-1}})$
$h_{b_t}=f(V·i_{N-t+1}+W·h_{b_{t+1}})$
$h_t=f(h_{f_t}+h_{b_t}+W·h_{t-1})$
其中,$V\in R^{H*|i|}$,N是iSDP中单词的总数,$i_t$是$t$时刻的输入向量,定义如下:
$iDepNN-SDP:i_t=[x_t,L_t]$
$iDepNN-ADP:i_t=[p_t,L_t]$
其中,$L_t$是$t$时刻每个单词的词典级别的特征(如词性标注,位置指示器,实体类型)。为了减小参数的量,这三个公式中的W是共享的。优化目标是最小化事实标签和预测标签之间的交叉熵。
特征主要关注整个句子的词、依存路径或者单个实体,这些特征为:
4 Evaluation and Analysis
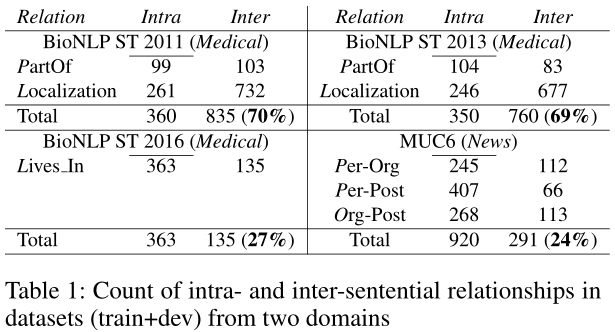
主要是基于医学和新闻领域构建的四个数据集:
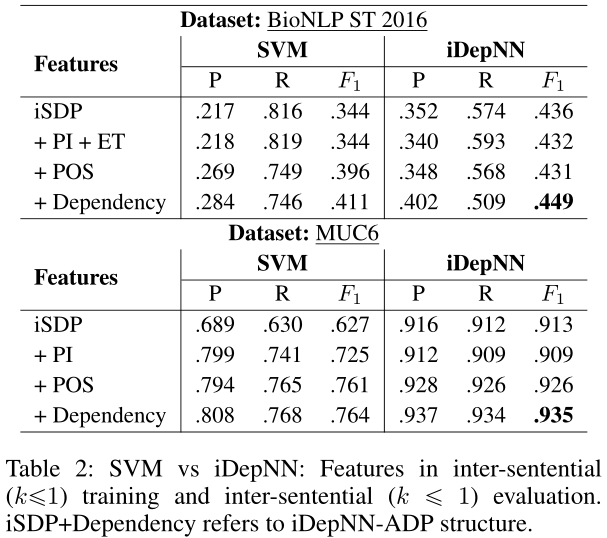
Contribution of different components
Note: iSDP+Dependency refers to iDepNN-ADP structure:
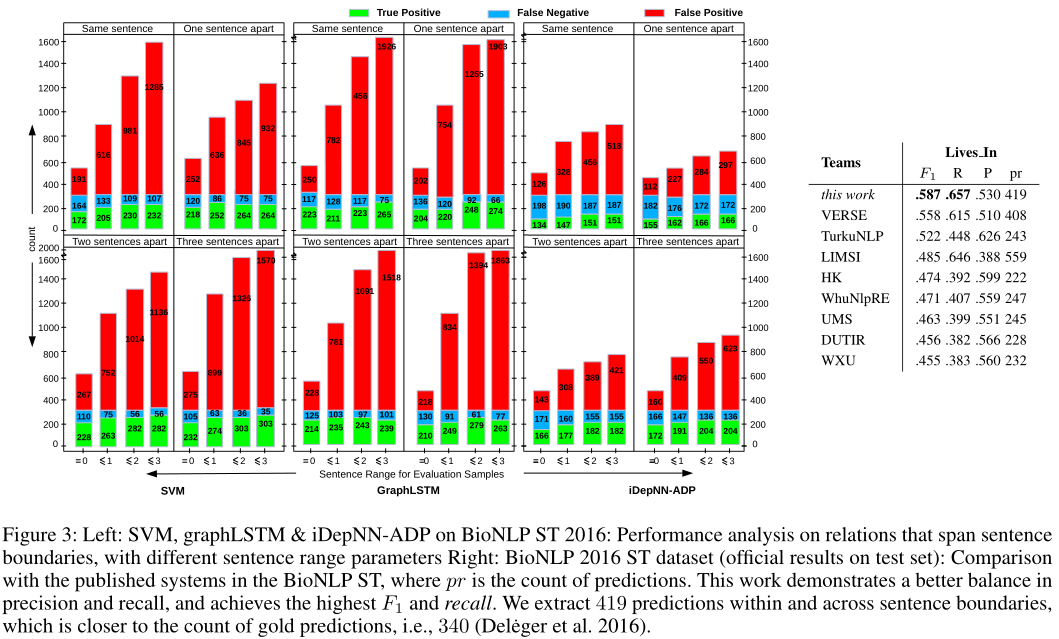
State-of-the-Art Comparisons BioNLP ST 2016 dataset:
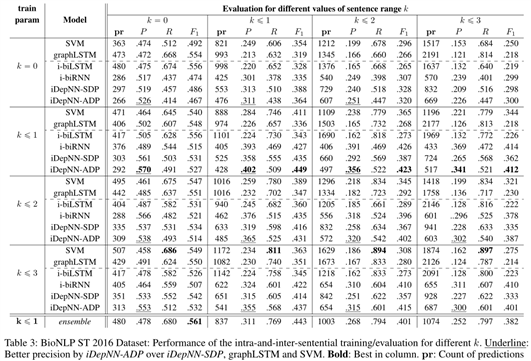
Confident Extractions:
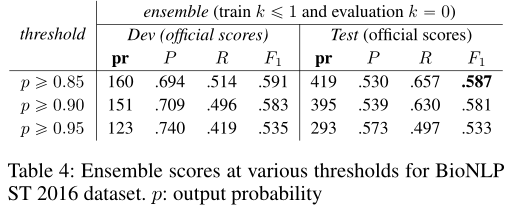
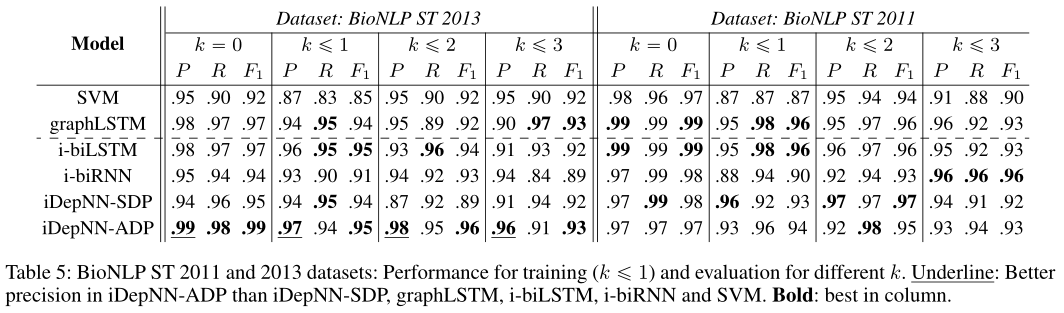
BioNLPST 2011 and 2013 datasets:
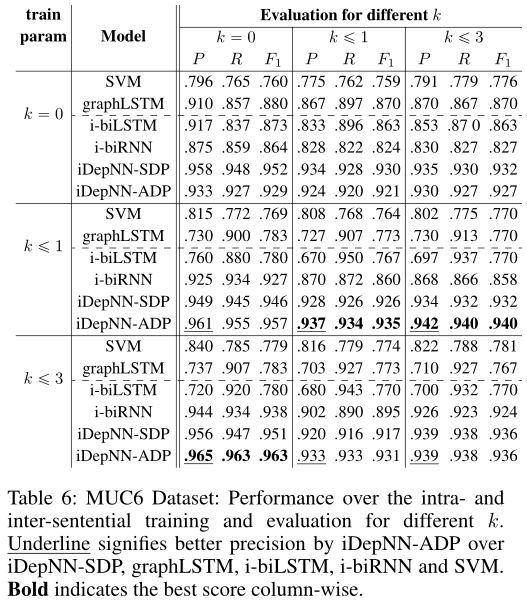
MUC6 dataset
Error Analysis
Conclusion
我们已经提出通过在一个新的神经网络中建立句子间最短和增强依赖路径的模型来对句子边界内和跨句子边界的实体之间的关系进行分类,基于句间依赖的神经网络(iDepNN)利用递归和递归两种神经网络recurrent and recursive neural networks对句内和句间关系中的结构进行建模。在新闻通讯和医学领域的四个数据集上的实验结果表明,iDepNN对false positives具有很强的鲁棒性,在查准率和查全率方面表现出更好的平衡,在提取句子边界内和跨句子边界的关系方面达到了最先进的性能。我们也比11个参加2016年BioNLP共享任务的团队表现更好。
【论文阅读】Neural Relation Extraction Within and Across Sentence Boundaries[AAAI2019]
原文:https://www.cnblogs.com/Harukaze/p/14363372.html