select * from A left join B on A.c = B.c where A.employee_id = 3

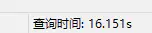
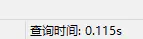
可以看到,确实是使用了索引!我们看看执行分析

思考:表A和表B中都加了索引,然而查询过程却是表A进行了全表扫描,如果非要全表扫描一个的话,为什么全表扫描的不是表B?
那么问题来了:where条件中employee_id 的索引应该怎么加?
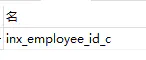
sql分析:

思考:sql执行 from中的on应该是优先于where语句的,为什么这里employee_id反而在c之前?有违常理?
结合上面的Mysql优化可知,
这一句Sql在执行的时候首先是选择了使用表B的索引来进行优化,
将表A单独放出来进行后续的操作,
然后,又发现了where语句中A.employee_id有一个聚合索引,
并且employee_id处于索引头,所以这个聚合索引是可用的,
so自然使用了此索引
为了证明这个观点,我们把聚合索引后面的列c删掉试试:
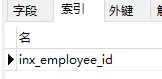
sql分析:

看看最终的查询时间:
如果数据量不是1万 而是100万,100亿,沿用之前的sql,系统还能稳定运行吗?
使用索引优化left join on + where条件查询
原文:https://www.cnblogs.com/47Gamer/p/14367729.html