来源:https://mp.weixin.qq.com/s/WiRyQEoDfuowT3LNfZ-NSw
这次我们的目的是,在本地的 IDEA 中去 debug flink-clients 代码,然后远程提交给 flink standalone 集群上去执行,看一看 flink 客户端在提交代码之前都干了什么。就像下面这样:
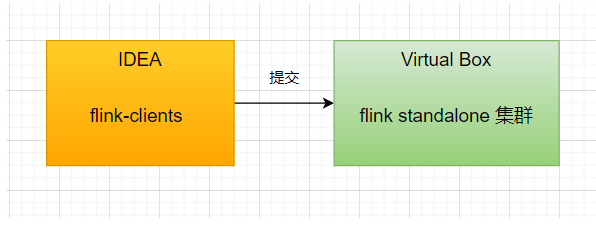
很简单是不是,瞬间自信心爆棚!在开始之前,我想要提两个发人深省的问题,你平时一定没有考虑过:
DataStream<Tuple2<String, Integer>> counts =
text.flatMap(new Tokenizer())
.keyBy(value -> value.f0).sum(1);
这个过程就是你经常刷源码解析博客看到的一个问题,“ StreamGraph 是如何生成的?”
不知道你有没有想过,Flink 框架本身是要依赖很多类库的,但我们自己写的代码也是要依赖很多类库的,万一 Flink 框架依赖的类库,跟我们自己的类库冲突了怎么办?
举个例子,Flink 框架会去依赖一个 2.0 版本的 kafka,你自己的代码中依赖的是 2.1 版本的 kafka,那很有可能就类冲突了啊。这个问题该如何解决?
问题1,可能要下次再解答;问题2,这次就解答!
之前我已经写了一篇文章,关于搭建环境的,这次就不细说了,只想补充两个跟上次不一样的点。
(1)Virtual Box 虚拟机,装好 linux,并且下载了官方发布包(1.12.0),解压到服务器某个目录上
(2)IDEA 环境中,已经导入了 flink 1.12.0 的源码(注意这里是源码,上面是发布包)
File - Project Structure - Project 改成 1.8
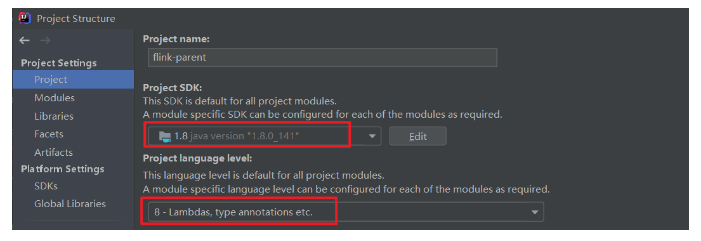
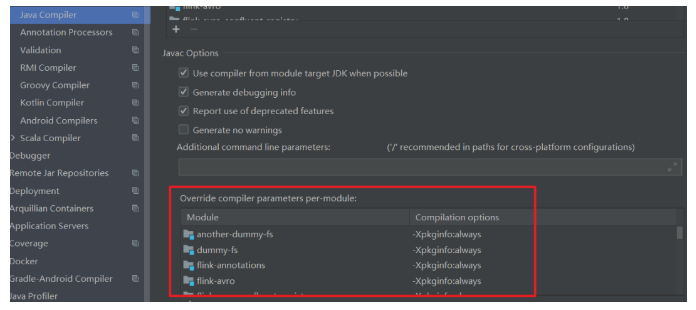
File - Settings - Build,Execution,Deployment - Compiler - Java Compiler 这里全部改成 8
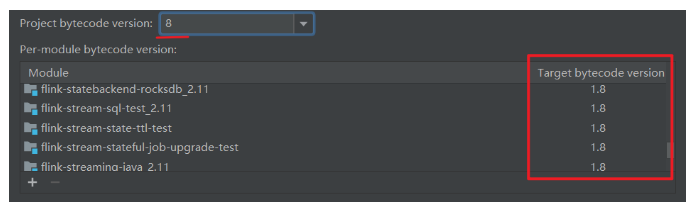
然后把下面这些全部删掉
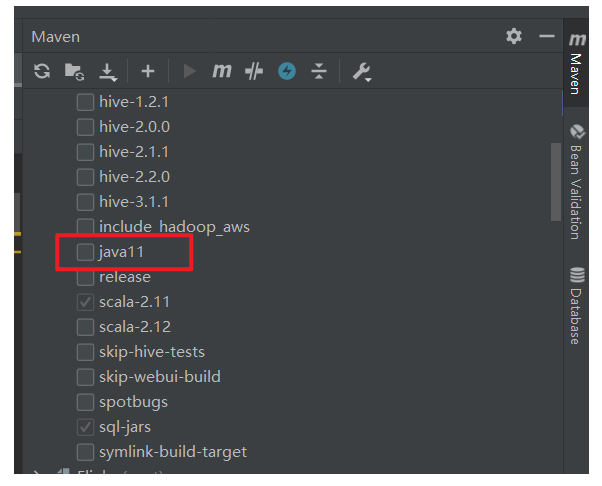
把 Maven 标签,这里的 java11 勾掉
然后重新 reload 工程
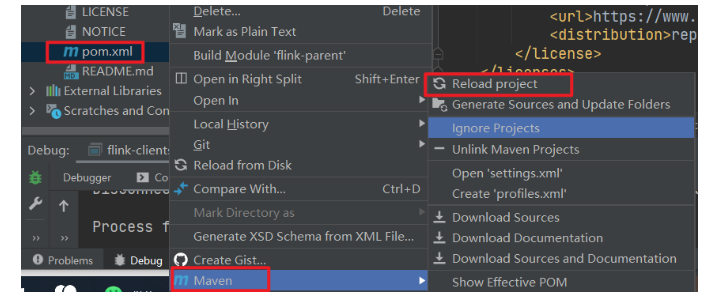
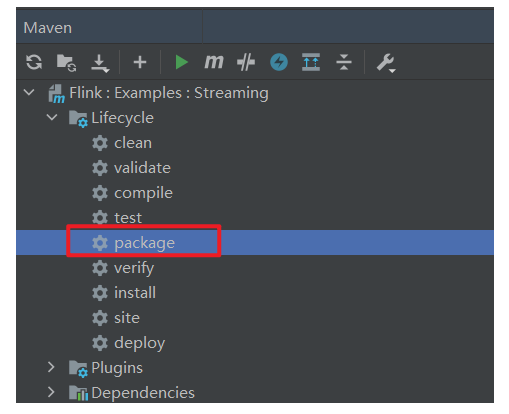
(3)重新 reload 之后,把这个工程 package 一下
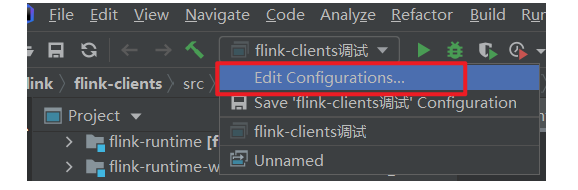
(4)IDEA 中新建一个运行配置
参数如下:
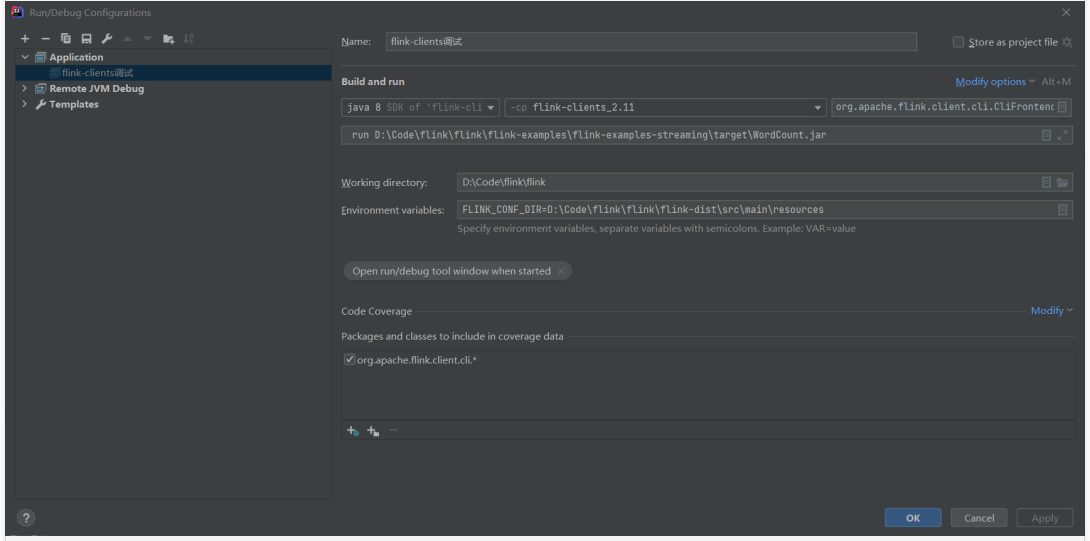
几个比较长的字符如下(根目录换成你自己的) org.apache.flink.client.cli.CliFrontend run D:\Code\flink\flink\flink-examples\flink-examples-streaming\target\WordCount.jar FLINK_CONF_DIR=D:\Code\flink\flink\flink-dist\src\main\resources
(5)这个 JobManager 修改成你虚拟机的地址
(6)直接 debug 运行

(7)可以顺利执行。
Flink 源码(二): Flink Client 实现原理与源码解析(一)
原文:https://www.cnblogs.com/qiu-hua/p/14383545.html