hadoop 集群具体来说包含两个集群:
HDFS集群
NameNode
DataNode
SecondaryNameNode
YARN集群 ——YARN集群负责海量数据运算时的资源调度
ResourceManager
NodeManager。
mapReduce——分布式运算编程框架,是应用程序开发包
由用户按照编程规范进行程序开发,后打包运行在HDFS集群上,并且受到YARN集群的资源调度管理。
独立模式: 一台机器部署所有,开启一个jvm (开发和测试)
伪分布式模式:一台机器,模拟出来多台虚拟机,多个节点程序(开发和测试)
完全分布式集群:多个节点分别部署到不同的机器上(生产环境)
目录结构的介绍:
bin目录:Hadoop最基本的管理脚本和使用脚本的目录
etc目录:hadoop集群的管理配置文件所在目录
sbin目录:Hadoop管理脚本所在的目录
share目录:Hadoop各个模块编译后的jar包所在的目录,官方自带示例
安装Java zk 不会见安装文档
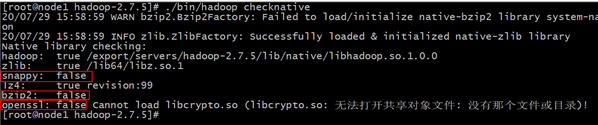

yum -y install openssl-devel

Hadoop的编译步骤可以参考:Hadoop编译文档
Hadoop安装主要就是配置文件的修改,一般在主节点进行修改,完毕后scp下发给其他各个从节点机器。
注意,以下所有操作都在node1主机进行。
注意: 在进行下面的操作, 请先将编译后的hadoop包上传到linux, 并且解压到/export/server
由于要修改的配置文件比较的多, 建议采用notepad++ 连接远程的主机, 在notepad++上直接进行修改保存即可: 如何使用呢
1) 观察在notepad++ 上 有没有一下这个图标

如果没有, 请安装资料中提供的notepad++ 即可

l 2) 点击这个黄色的按钮:

3) 点击 设置按钮--profile
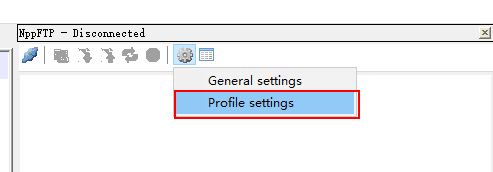
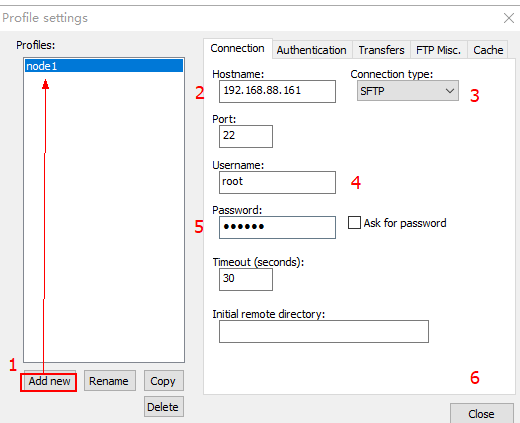
4) 开始设置虚拟机的地址即可: 可以将所有的服务器都配置, 也可以只配置第一个
5) 点的 connect. 选择要连接的主机即可
6) 此时如果弹出一个框框, 直接一顿选择yes 就好了, 完成后, 如果能够看到一下内容, 说明连接成功了
此时就可以愉快的选择对应文件, 进行修改保存操作即可
1、介绍
文件中设置的是Hadoop运行时需要的环境变量。JAVA_HOME是必须设置的,即使我们当前的系统中设置了JAVA_HOME,它也是不认识的,因为Hadoop即使是在本机上执行,它也是把当前的执行环境当成远程服务器。
2、配置
|
cd /export/server/hadoop-2.7.5/etc/hadoop vim hadoop-env.sh |
添加以下内容:
|
export JAVA_HOME=/export/server/jdk1.8.0_241 |
1、介绍
hadoop的核心配置文件,有默认的配置项core-default.xml。
core-default.xml与core-site.xml的功能是一样的,如果在core-site.xml里没有配置的属性,则会自动会获取core-default.xml里的相同属性的值。
1、配置
在该文件中的<configuration>标签中添加以下配置,
<configuration>
在这里添加配置
</configuration>
|
cd /export/server/hadoop-2.7.5/etc/hadoop vim core-site.xml |
配置内容如下:
|
<!-- 用于设置Hadoop的文件系统,由URI指定 --> <property> <name>fs.defaultFS</name> <value>hdfs://node1:8020</value> </property> <!-- 配置Hadoop存储数据目录,默认/tmp/hadoop-${user.name} --> <property> <name>hadoop.tmp.dir</name> <value>/export/server/hadoop-2.7.5/hadoopDatas/tempDatas</value> </property>
<!-- 缓冲区大小,实际工作中根据服务器性能动态调整: 根据自己的虚拟机的内存大小进行配置即可, 不要小于1GB, 最高配置为 4gb --> <property> <name>io.file.buffer.size</name> <value>4096</value> </property>
<!-- 开启hdfs的垃圾桶机制,删除掉的数据可以从垃圾桶中回收,单位分钟 --> <property> <name>fs.trash.interval</name> <value>10080</value> </property> |
1、介绍
HDFS的核心配置文件,主要配置HDFS相关参数,有默认的配置项hdfs-default.xml。
hdfs-default.xml与hdfs-site.xml的功能是一样的,如果在hdfs-site.xml里没有配置的属性,则会自动会获取hdfs-default.xml里的相同属性的值。
2、配置
在该文件中的<configuration>标签中添加以下配置,
<configuration>
在这里添加配置
</configuration>
|
cd /export/server/hadoop-2.7.5/etc/hadoop vim hdfs-site.xml |
配置一下内容
|
<!-- 指定SecondaryNameNode的主机和端口 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>node2:50090</value> </property> <!-- 指定namenode的页面访问地址和端口 --> <property> <name>dfs.namenode.http-address</name> <value>node1:50070</value> </property> <!-- 指定namenode元数据的存放位置 --> <property> <name>dfs.namenode.name.dir</name> <value>file:///export/server/hadoop-2.7.5/hadoopDatas/namenodeDatas</value> </property> <!-- 定义datanode数据存储的节点位置 --> <property> <name>dfs.datanode.data.dir</name> <value>file:///export/server/hadoop-2.7.5/hadoopDatas/datanodeDatas</value> </property> <!-- 定义namenode的edits文件存放路径 --> <property> <name>dfs.namenode.edits.dir</name> <value>file:///export/server/hadoop-2.7.5/hadoopDatas/nn/edits</value> </property>
<!-- 配置检查点目录 --> <property> <name>dfs.namenode.checkpoint.dir</name> <value>file:///export/server/hadoop-2.7.5/hadoopDatas/snn/name</value> </property>
<property> <name>dfs.namenode.checkpoint.edits.dir</name> <value>file:///export/server/hadoop-2.7.5/hadoopDatas/dfs/snn/edits</value> </property> <!-- 文件切片的副本个数--> <property> <name>dfs.replication</name> <value>3</value> </property>
<!-- 设置HDFS的文件权限--> <property> <name>dfs.permissions</name> <value>false</value> </property> <!-- 设置一个文件切片的大小:128M--> <property> <name>dfs.blocksize</name> <value>134217728</value> </property> <!-- 指定DataNode的节点配置文件 --> <property> <name> dfs.hosts </name> <value>/export/server/hadoop-2.7.5/etc/hadoop/slaves</value> </property> |
1、介绍
MapReduce的核心配置文件,Hadoop默认只有个模板文件mapred-site.xml.template,需要使用该文件复制出来一份mapred-site.xml文件
2、配置
|
cd /export/server/hadoop-2.7.5/etc/hadoop cp mapred-site.xml.template mapred-site.xml |
在mapred-site.xml文件中的<configuration>标签中添加以下配置,
<configuration>
在这里添加配置
</configuration>
|
vim mapred-site.xml |
配置一下内容:
|
<!-- 指定分布式计算使用的框架是yarn --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
<!-- 开启MapReduce小任务模式,hadoop2.0实现针对MR小作业的优化机制 --> <property> <name>mapreduce.job.ubertask.enable</name> <value>true</value> </property>
<!-- 设置历史任务的主机和端口 --> <property> <name>mapreduce.jobhistory.address</name> <value>node1:10020</value> </property>
<!-- 设置网页访问历史任务的主机和端口 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>node1:19888</value> </property> |
在该文件中需要指定JAVA_HOME,将原文件的JAVA_HOME配置前边的注释去掉,然后按照以下方式修改:
|
cd /export/server/hadoop-2.7.5/etc/hadoop vim mapred-env.sh |
|
export JAVA_HOME=/export/server/jdk1.8.0_241 |
YARN的核心配置文件,在该文件中的<configuration>标签中添加以下配置,
<configuration>
在这里添加配置
</configuration>
|
cd /export/server/hadoop-2.7.5/etc/hadoop vim yarn-site.xml |
添加以下配置:
|
<!-- 配置yarn主节点的位置 --> <property> <name>yarn.resourcemanager.hostname</name> <value>node1</value> </property>
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
<!-- 开启日志聚合功能 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 设置聚合日志在hdfs上的保存时间 7天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> <!-- 设置yarn集群的内存分配方案 --> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>20480</value> </property> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>2048</value> </property> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>2.1</value> </property> |
1、介绍
slaves文件里面记录的是集群主机名。一般有以下两种作用:
一是:配合一键启动脚本如start-dfs.sh、stop-yarn.sh用来进行集群启动。这时候slaves文件里面的主机标记的就是从节点角色所在的机器。
二是:可以配合hdfs-site.xml里面dfs.hosts属性形成一种白名单机制。
dfs.hosts指定一个文件,其中包含允许连接到NameNode的主机列表。必须指定文件的完整路径名,那么所有在slaves中的主机才可以加入的集群中。如果值为空,则允许所有主机。
2、配置
|
cd /export/server/hadoop-2.7.5/etc/hadoop vim slaves |
删除slaves中的localhost,然后添加以下内容:
|
node1 node2 node3 |
注意,以下所有操作都在node1主机进行。
1、目录创建
创建Hadoop所需目录
|
mkdir -p /export/server/hadoop-2.7.5/hadoopDatas/tempDatas mkdir -p /export/server/hadoop-2.7.5/hadoopDatas/namenodeDatas mkdir -p /export/server/hadoop-2.7.5/hadoopDatas/datanodeDatas mkdir -p /export/server/hadoop-2.7.5/hadoopDatas/nn/edits mkdir -p /export/server/hadoop-2.7.5/hadoopDatas/snn/name mkdir -p /export/server/hadoop-2.7.5/hadoopDatas/dfs/snn/edits |
3、文件分发
将配置好的Hadoop目录分发到node2和node3主机。
|
scp -r /export/server/hadoop-2.7.5/ node2:/export/server/ scp -r /export/server/hadoop-2.7.5/ node3:/export/server/ |
注意,三台机器都需要执行以下命令
|
vim /etc/profile |
添加以下内容:
|
export HADOOP_HOME=/export/server/hadoop-2.7.5 export PATH=:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH |
配置完成之后生效
|
source /etc/profile |
要启动Hadoop集群,需要启动HDFS和YARN两个集群。
注意:首次启动HDFS时,必须对其进行格式化操作。本质上是一些清理和准备工作,因为此时的HDFS在物理上还是不存在的。
在node1上执行格式化指令
|
hadoop namenode -format |
在node1主机上使用以下命令启动HDFS NameNode:
hadoop-daemon.sh start namenode |
在node2主机上使用以下命令启动secondarynamenode:
hadoop-daemon.sh start secondarynamenode |
在node1、node2、node3三台主机上,分别使用以下命令启动HDFS DataNode:
hadoop-daemon.sh start datanode |
在node1主机上使用以下命令启动YARN ResourceManager:
yarn-daemon.sh start resourcemanager |
在node1、node2、node3三台主机上使用以下命令启动YARN nodemanager:
yarn-daemon.sh start nodemanager |
以上脚本位于/export/server/hadoop-2.7.5/sbin目录下。如果想要停止某个节点上某个角色,只需要把命令中的start改为stop即可。
启动HDFS
|
start-dfs.sh |
启动Yarn
|
start-yarn.sh |
启动历史任务服务进程
|
mr-jobhistory-daemon.sh start historyserver |
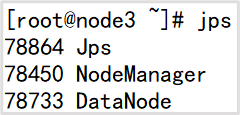
启动之后,使用jps命令查看相关服务是否启动,jps是显示Java相关的进程命令。
node1:

node2:

node3
停止集群:stop-dfs.sh、stop-yarn.sh、mr-jobhistory-daemon.sh stop historyservers
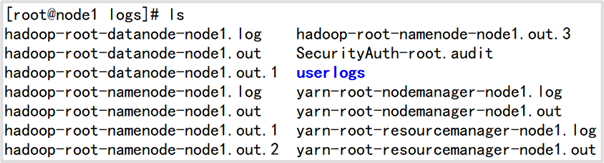
注意:如果在启动之后,有些服务没有启动成功,则需要查看启动日志,Hadoop的启动日志在每台主机的/export/server/hadoop-2.7.5/logs/目录,需要根据哪台主机的哪个服务启动情况去对应的主机上查看相应的日志,以下是node1主机的日志目录.
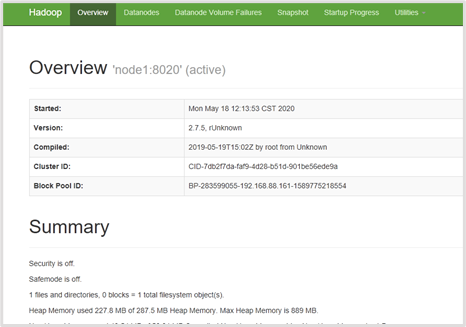
一旦Hadoop集群启动并运行,可以通过web-ui进行集群查看,如下所述:
查看NameNode页面地址:
查看Yarn集群页面地址:
http://192.168.88.161:8088/cluster
查看MapReduce历史任务页面地址:
http://192.168.88.161:19888/jobhistory
请注意,以上的访问地址只能使用IP地址,如果想要使用主机名,则对Windows进行配置。
配置方式:
1、打开Windows的C:\Windows\System32\drivers\etc目录下hosts文件
2、在hosts文件中添加以下域名映射
|
192.168.88.161 node1 192.168.88.162 node2 192.168.88.163 node3 |
配置完之后,可以将以上地址中的IP替换为主机名即可访问,如果还不能访问,则需要重启Windows电脑,比如访问NameNode,可以使用http://node1:50070/ 。
原文:https://www.cnblogs.com/it-wp/p/14383953.html