优雅
这是框架设计师第一个要考虑的问题,框架的用户是应用开发程序员,API是否优雅直接影响用户体验。
速度快:
Scala语言表达能力强,一行代码抵得上Java多行,开发速度快;Scala是静态编译的,所以和JRuby,Groovy比起来速度会快很多。
能融合到Hadoop生态圈
Hadoop现在是大数据事实标准,Spark并不是要取代Hadoop,而是要完善Hadoop生态。JVM语言大部分可能会想到Java,但Java做出来的API太丑,或者想实现一个优雅的API太费劲。
windows安装
Scala官网 找 scala-2.x.x.msi,点点点操作就行。
Linux安装
1.下载Scala地址然后解压Scala到指定目录.
2.解压:tar -zxvf scala-2.11.8.tgz -C /usr/java
3.配置环境变量,将scala加入到PATH中vi /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_111
export PATH=$PATH:$JAVA_HOME/bin:/usr/java/scala-2.11.8/bin
File->New->Projects->Scala->IDEA->Next->项目名,指定scala编译器->Finish
//使用val定义的变量值是不可变的,相当于java里用final修饰的变量
val i=0
//使用var定义的变量是可变得,在Scala中鼓励使用val
var s="hello"
//Scala编译器会自动推断变量的类型,必要的时候可以指定类型
//变量名在前,类型在后
val str: String = "world"
Scala和Java一样,有7种数值类型Byte、Char、Short、Int、Long、Float和Double(无包装类型)和一个Boolean类型
package cn._xjk
object IFDemo1 {
def main(args: Array[String]): Unit = {
val i = 10
if (i < 10) {
println("i小于10")
} else {
println("i大于等于10") // i大于等于10
}
val y = if (i>10) 1 else -1
println(y)// -1
val m = if (i > 10) 100
println(m)// ()
val k = if (i > 10) 1
else if (i < 10) 10 else 100
println(k)// 100
}
}
package cn._xjk
object BlockDemo1 {
def main(args: Array[String]): Unit = {
val x = 0
val result = {
if (x < 0) {
-1
} else if (x>=1) {
1
} else {
"error"
}
}
println(result)
}
}
for (i <- 表达式/数组/集合)
package cn._xjk
object ForDemo1 {
def main(args: Array[String]): Unit = {
// 每次循环将区间中的一个值赋给i
for (i <- 1 to 10) {
println(i)
}
val arr = Array("a", "b", "c")
for (i <- arr)
println(arr)
// 根据索引取值
val arr = Array("hello", "world", "!")
for (i <- 0 until arr.length) {
println(arr(i))
}
// 高级for循环
for (i <- 1 to 3; j<-1 to 3 if i!=j){
print((10 * i + j) + " ")
}
println()
//for推导式:如果for循环的循环体以yield开始,则该循环会构建出一个集合
//每次迭代生成集合中的一个值
val v = for (i <- 1 to 10) yield i*10
println(v)
// 偶数相加
val result = for (i <- 0 to 10 if i %2 == 0) yield i*2
println(result)
}
}

package cn._xjk
object MethodDemo1 {
def main(args: Array[String]): Unit = {
// m1(5) 传参Int,返回Int
// m2(5) 传参Int, 不声明返回自动声明返回值类型
// m3 不传参,不声明返回值类型,方法不加括号也能调用
// m4 方法定义不加括号,调用时候也不加括号
}
def m1(i: Int): Int = {
i * i
}
def m2(i: Int) = {
i * i
}
def m3(): Unit = {
print("hello")
}
def m4:Unit = {
print("m6")
}
}
// 定义函数
scala> val f = (x: Int) => x *x
f: Int => Int = $$Lambda$1025/798695894@696b52bc
// 调用函数
scala> f(5)
res0: Int = 25
// 定义方法
scala> def m(x: Int): Int = x * x
m: (x: Int)Int
// 调用方法
scala> m(5)
res1: Int = 25
val 函数名 (参数类型1, 参数类型2,...) => 返回值类型 = (参数1 类型1,参数2 类型2,...) => 代码逻辑
val f:(Int,Int) => Int =(x:Int,y:Int) => x * y
package cn._xjk
object FuncDemo1 {
def main(args: Array[String]): Unit = {
// 方式1:
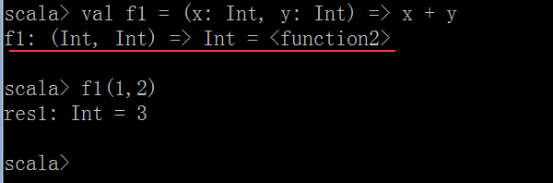
val f1 = (x:Int,y:Int) => x + y
// 方式2:
var f2:(Int, Int) => Int = (x:Int, y:Int) => x + y
// 方式3:
var f3:(Int, Int) => Int = (x, y) => x + y
// 理解函数:
// Function2代表:输入第一个参数类型,输入第二个参数类型, 返回值类型
// 方式4:
val f4: Function2[Int, Int, Int] = (x:Int, y:Int) => x + y
// 方式5:
val f5: Function2[Int, Int, Int] = new Function2[Int, Int, Int] {
override def apply(v1: Int, v2: Int): Int = v1 + v2
}
val a = f5(4,6)
println(a) // 10
}
}
val f = (x:Int) => x * x
val arr = Array(1,2,3,4,5,6,7)
// map相当于: for (i <- arr) yield i * i
// 方式1:
arr.map(f)
// 方式2:
arr.map((x) => x * x)
// 方式3:
arr.map(x => x * x)
arr = Array(1,2,3,4,5,6,7,8,9,10)
arr.filter((x:Int)=> x%2==0).map(x => x * 10).sum
val arr = Array(1,2,3,4,5,6)
arr(1) = 50
println(arr) // (1,50,3,4,5,6)
import scala.collection.mutable._
// 声明一个数组
val arr1 = new ArrayBuffer[Int]
var arr2 = new Array[Int](3)
// 添加单个元素
arr1.append(5)
arr1 += 2
// 删除一个元素
arr1 -= 2
// 添加多个元素
arr1 += Array(1,4,5)
// Array转换成ArrayBuffer
arr.toBuffer
// Array是不可变数组,ArrayBuffer是可变数组。ArrayBuffer可以进行插入操作和删除操作
arr1.insert(1,6)//数组角标1前面插入6
arr1.insert(1,5,10)//数组角标1前面插入5和10
arr1.remove(1,2)//把角标1,2的数组删除
// 逆序遍历
for (i <-(0 until arr.length).reverse) println(arr(i))
// 示例
scala> arr.filter(x => x%2 !=0).map(x => x*100).sorted.reverse
List
val lst = List(1,2,3,4,5)
scala> lst(1) = 20
<console>:16: error: value update is not a member of List[Int]
lst(1) = 20// 这里报错
val lst = new ListBuffer[Int]
lst += 1
lst ++= ListBuffer(1,2,3,4)
lst.map(x => x * 10)
// 同时它还有remove,insert等特性
set
val st = Set(1,2,3)
// 添加元素
st.add(5)
st+=6
// 删除元素
st.remove(5)
st -= 6
val st = scala.collection.immutable.Set(1,2,3,4,5,6)
map
val mmp = Map("a"->1, "b"->2)
//添加元素
mmp.put("c", 11)
mmp+=(("e",10))
// 没有就添加,有就修改
mmp("d", 10)
// 删除元素
mmp -= "d"
// map循环
for ((k,v)<-mp)println(k+"->"+v)
val mp = scala.collection.immutable.Map("a" -> 1, "b" -> 2, "c" -> 3)
// 获取元素
mp.get("a")
mp.getOrElse("d", 0) // 有的话返回d的值,没有的话返回0
// 元组不可变类型,元组可以装各种类型数据
val tp = (1,2.0,"hello")
// 取出索引1的元组中值
tp._1
// 元组内元素互换位置
val tp2 = (10, "a")
tp2.swap
单词统计:"hello tom hello jerry","hello tom hello kitty","hello"
val lines = Array("hello tom hello jerry","hello tom hello kitty","hello")
// 一行写
lines.flatMap(line => line.split(" ")).map(word => (word, 1)).groupBy(t => t._1).map(t => (t._1,t._2.length)).toList.sortBy(t => -t._2)
// 多行写
package cn._xjk
object WordCountDemo1 {
def main(args: Array[String]): Unit = {
val lines = Array("hello tom hello jerry","hello tom hello kitty","hello")
// flatMap 切分压平
val word: Array[String] = lines.flatMap(line => line.split(" "))
// 将单词和和统计次数组合
val wordAndOne: Array[(String, Int)] = word.map(w => (w, 1))
// 分组
val grouped: Map[String, Array[(String, Int)]] = wordAndOne.groupBy(t => t._1)
// 聚合
val wordAndCounts: Map[String, Int] = grouped.map(t => (t._1, t._2.length))
// 排序
val result: List[(String, Int)] = wordAndCounts.toList.sortBy(t => -t._2)
// 打印
println(result.toBuffer)
}
}
原文:https://www.cnblogs.com/xujunkai/p/14387549.html