原文链接:https://blog.csdn.net/on2way/article/details/50395055
上节我们看到自编码网络额隐含层可以用于原始数据的降维(其实也可以升维,不过把隐含层的单元设置的比输入维度还要多),换而言之就是特征学习,那么学习到的这些特征就可以用于分类了,本节主要试验下这些特征用于分类的效果。
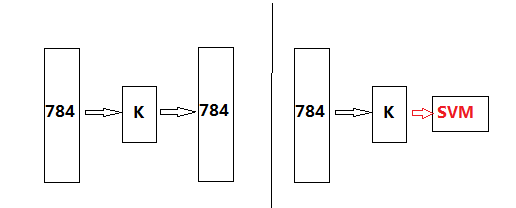
先以最简单的三层自编码网络为例,先训练自编码网络,在得到编码权值矩阵后,在后接SVM分类器,抽象出来就是如下两个步骤:
这里我们不断调整隐含层单元个数K,并观察最终的分类准确率。
Ok第一步是自编码学习,部分代码如下:
%--------------添加当前文件夹-------------
%% addpath .\DeepLearnToolbox-master\.
currentFolder = pwd;
addpath(genpath(currentFolder))
%% 选择样本
load mnist_uint8;
%% 规定自编码权值
choose_num_train = 20000;
train = double(train_x(1:choose_num_train,:))/255;
auto_net = [784 100];
sae = deep_autocoderW(train,auto_net);首先设置好工具箱所有路径,加载数据,选择用于自编码的样本个数,确定网络结构,然后进行自编码学习,关于deep_autocoderW函数如下:
function sae = deep_autocoderW(train_x,auto_net)
%% 规定每一层参数--需要修改的参数
sae = saesetup(auto_net);
for i = 1:(numel(auto_net)-1)
sae.ae{i}.activation_function = ‘sigm‘;
sae.ae{i}.learningRate = 1;
sae.ae{i}.inputZeroMaskedFraction = 0.5;
sae.ae{i}.nonSparsityPenalty = 0.05;
end
%% 训练自编码
opts.numepochs = 1;
opts.batchsize = 100;
sae = saetrain(sae, train_x, opts);在这个函数里,我们要设置一些网络的参数,尤其是稀疏表示的参数设置、激活函数的设置,等等,然互直接调用自编码的训练函数,就可以得到训练好的网络。
训练好了我们只是把自编码网络训练完了,那么我们接下来就是要找到输入经过隐含层的输出是什么?比如这里784维输入经过隐含层会输出K=100维的数据(也就是降维数据,也就是特征提取数据)。很简单就是将784维数据依次乘以编码网络的权值参数即可。接着上面的代码往下提取这100维特征数据:
%% 重新选择分类需要的训练数据与测试数据
num_train = 5000;
train_x = double(train_x(1:num_train,:))/255;
train_y = double(train_y(1:num_train,:));
num_test= 5000;
test_x = double(test_x(1:choose_num_test,:))/255;
test_y = double(test_y(1:choose_num_test,:));
%% 根据自编码网络提取特征
data_train_feature = deep_feature_data(sae,train_x);
data_test_feature = deep_feature_data(sae,test_x);
data_train = data_train_feature{1};
data_test = data_test_feature{1};这里调用了一个函数deep_feature_data,这个函数就是获得降维的数据的,具体如下:
function data_feature = deep_feature_data(sae,data)
%% 使用自编码权值计算每一层的特征
data_feature{1} = data;
for i = 1:(numel(sae.ae))
if i == 1
data_temp = [ones(size(data,1),1),data];%加入常数项到输入中
data_feature{1} = sigm(data_temp * (sae.ae{1}.W{1})‘);%2:end 为权值
else
data_feature_temp = [ones(size(data_feature{i-1},1),1),...
data_feature{i-1}];
data_feature{i} = sigm(data_feature_temp * (sae.ae{i}.W{1})‘);
end
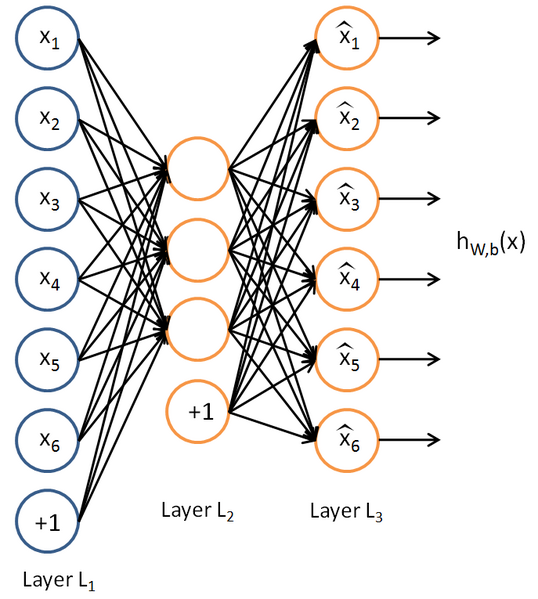
end这里可以看到某一层的输出就是其输入乘以它连接着的权值参数。为什么是data要变成data_temp呢?因为这个工具箱认为的自编码网络每一层还有一个b值,如下所示:
从图上看我们可能认为这个常数1应该更在784维数据后面构成785维输入,而我们是加在784维前面的构成785维输入,这一点的判断是从这个工具箱自带的可视化函数来的:
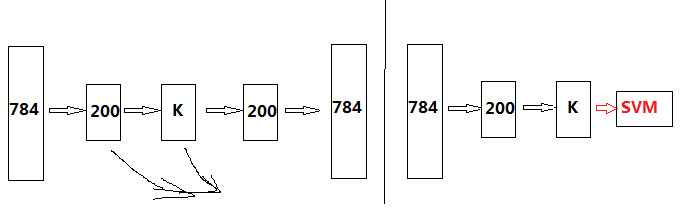
visualize(sae.ae{1}.W{1}(:,2:end)‘)%可视化编码矩阵的权值从这里可以看出,出来的785维权值矩阵中2:end的这784维为输入对应的权值,第一维自然是常数项对应的权值。这个函数后面还有个else,意思是假设这个网络不止三层的时候,每一层我们都计算一下它的特征输出,就好比下面这样,计算经过200的特征,以及经过K后的特征,但是我们可能用的是K后的特征去接SVM分类器,同时还需要注意的是我们需要使用激活函数去处理一下,并且使用的是训练网络的激活函数,比如这里是sigm,所以得到的特征都要sigm一下才是我们最终用于输入到SVM的特征。
当然在这个三层中我们最终送入到SVM的就只有一个,经过K=100后的特征,也就是
data_train = data_train_feature{1};
data_test = data_test_feature{1};至此我们可以开始第二步了,用这些特征去训练SVM分类器。在这里再说一点,可能有人注意到,前面训练自编码的时候用了20000个训练样本,在训练SVM时又选了5000个样本训练,5000个样本测试,这里要说的是,训练自编码的20000个样本是用来训练自编码网络的,而在网络确定后,又用5000个样本训练的是SVM,这两个训练是不一样的,独立分开的。更多的时候,在深度学习领域里面你会看到,其实前20000个样本叫做网络的预训练,而后5000个样本可用于网络的微调参数,使得网络更准确。
ok紧接着上面的代码,加入SVM分类器,这里使用的libSVM工具箱,关于该工具箱的使用,点击这个博客 可以看到
训练svm以及测试的代码如下:
%% svm 训练
[~,train_y] = max(train_y‘);
model = svmtrain(train_y‘,data_train,‘-t 0‘);
%% svm 测试
[~,test_y] = max(test_y‘);
predict1 = svmpredict(ones(numel(test_y),1),data_test,model);
accurary = numel(find(predict1 == test_y‘))/numel(test_y)
某一次的运行结果如下:
accurary =
0.9242可以看到5000个训练样本下5000个测试样本的结果,而网络呢是在20000个样本下自编码得到的网络,这个网络我们也没有进行在优化了,其实是可以在优化的,比如我们可以微调网络参数等等。
为了观察不同的K下试验的效果如何,这里我们设置不同的K值,其他不变进行重复的实验如下:
%--------------添加当前文件夹-------------
%% addpath .\DeepLearnToolbox-master\.
clc
clear
currentFolder = pwd;
addpath(genpath(currentFolder))
K = [10,20,30,40,50,60,70,80,90,100,110,120,130,140,150];
for i = 1:15
%% 选择样本
load mnist_uint8;
%% 规定自编码权值
choose_num_train = 20000;
train = double(train_x(1:choose_num_train,:))/255;
auto_net = [784 K(i)];
sae = deep_autocoderW(train,auto_net);
%%
num_train = 5000;
train_x = double(train_x(1:num_train,:))/255;
train_y = double(train_y(1:num_train,:));
num_test= 5000;
test_x = double(test_x(1:num_test,:))/255;
test_y = double(test_y(1:num_test,:));
%%
data_train_feature = deep_feature_data(sae,train_x);
data_test_feature = deep_feature_data(sae,test_x);
data_train = data_train_feature{1};
data_test = data_test_feature{1};
%% svm 训练
[~,train_y] = max(train_y‘);
model = svmtrain(train_y‘,data_train,‘-t 0‘);
%% svm 测试
[~,test_y] = max(test_y‘);
predict1 = svmpredict(ones(numel(test_y),1),data_test,model);
accurary(i) = numel(find(predict1 == test_y‘))/numel(test_y)
end
plot([0,K],[0,accurary]);
hold on;
plot([0,K],[0,accurary],‘*‘);
str = [];
for i = 1:numel(auto_net)-1
str = [str,‘-‘,num2str(auto_net(i))];
end
xlabel([num2str(numel(auto_net)-1),‘层,分别为‘,str,‘-X 层隐含层自编码-特征‘]);
ylabel([‘准确率‘]);
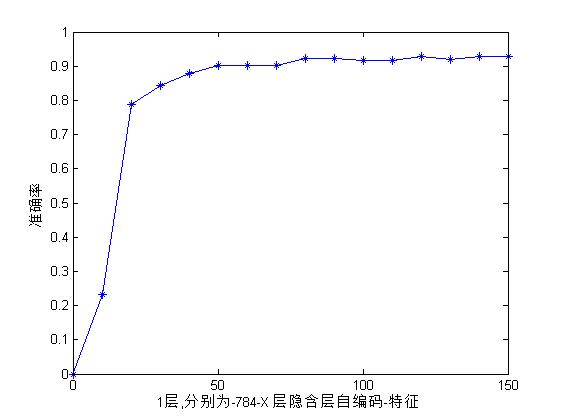
axis([0 150 0 1]);得到的结果如下:
可以看到在K值达到50以后基本上快上升不动了。可见将784维的手写体降到50多维以后基本上达到饱和了吧。
为了形成对比,下面我们使用PCA来实现降维的过程,和我们的自编码降维提取的特征形成对比,同样以降维K取不同的值进行实验,主代码如下:
%--------------添加当前文件夹-------------
%% addpath .\DeepLearnToolbox-master\.
currentFolder = pwd;
addpath(genpath(currentFolder))
%% 选择样本
K = [10,20,30,40,50,60,70,80,90,100,110,120,130,140,150];
for i = 1:15
load mnist_uint8;
choose_num_train = 5000;
train_x = double(train_x(1:choose_num_train,:))/255;
train_y = double(train_y(1:choose_num_train,:));
choose_num_test= 5000;
test_x = double(test_x(1:choose_num_test,:))/255;
test_y = double(test_y(1:choose_num_test,:));
%% 对训练集于测试集求取PCA,都转化到PCA数据
k = K(i); %降维数
[train_pca,train_mean,V] = PCA(train_x,k);
num_test = size(test_x,1);
img_mean_all = repmat(train_mean,num_test,1);%复制m行平均值至整个矩阵
test_x = double(test_x) - img_mean_all;
test_pca = test_x*V;
%% svm 训练
[~,train_y] = max(train_y‘);
model = svmtrain(train_y‘,train_pca,‘-t 0‘);
%% svm 测试
[~,test_y] = max(test_y‘);
predict1 = svmpredict(ones(numel(test_y),1),test_pca,model);
accurary(i) = numel(find(predict1 == test_y‘))/numel(test_y)
end
plot([0,K],[0,accurary])
hold on;
plot([0,K],[0,accurary],‘*‘)
xlabel([‘PCA降维数‘]);
ylabel([‘准确率‘])
axis([0 150 0 1]);其中关于PCA函数可以在我以前人脸识别的博客中找到,这里再贴一下吧:
%--------------函数说明-------------
%-----简单主成分分析算法
%-----输入:样本集合矩阵:img
% 降维的维数 :k
%-----输出:img_new,img_mean,V
%-----------------------------------
function [img_new,img_mean,V] = PCA(img,k)
%用法: [img_new,img_mean,V] = PCA(train_face,k);
%reshape函数:改变句矩阵的大小,矩阵的总元素个数不能变
img = double(img);
[m,n] = size(img); %取大小
img_mean = mean(img); %求每列平均值
img_mean_all = repmat(img_mean,m,1);%复制m行平均值至整个矩阵
Z = img - img_mean_all;
T=Z*Z‘; %协方差矩阵(非原始所求矩阵的协方差)
[V,D] = eigs(T,k);%计算T中最大的前k个特征值与特征向量
V=Z‘*V; %协方差矩阵的特征向量
for i=1:k %特征向量单位化
l=norm(V(:,i));
V(:,i)=V(:,i)/l;
end
img_new = Z*V; %低维度下的各个脸的数据想详细了解PCA的可以翻我前面的博客。
好了我们来看看在训练集合测试集也都是5000的情况下一个实验结果:
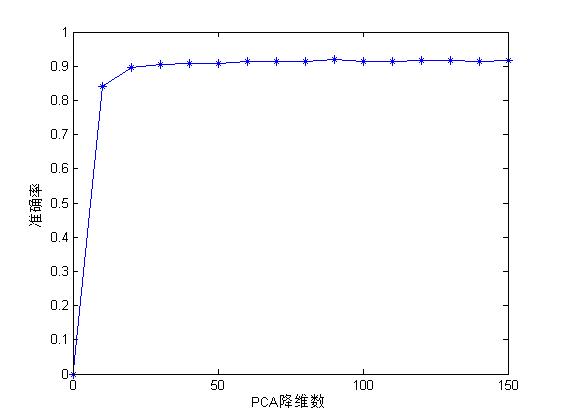
accurary =
Columns 1 through 8
0.8408 0.8954 0.9062 0.9088 0.9076 0.9134 0.9130 0.9142
Columns 9 through 15
0.9188 0.9150 0.9148 0.9172 0.9162 0.9142 0.9162把结果画出来是这样的:
从数据上看最大准确率为0.9188,而在前面的自编码提取特征并用SVM实验中,最大准确率可以达到0.9288,整整0.01的差别,也就是多0.01*5000=50个样本分类正确。
好了,到了这里我们已经可以看出通过机器自己找特征与人工找特征(其实PCA还不能算纯人工找特征)的差别了吧,可见自编码的特征寻找能力是要强于PCA的,我们知道PCA这种降维方式其实也很强了,至今在多数地方依然首要用到。那么,这还是没有怎么优化的自编码找特征,当我们在优化优化,将会得到更好的结果。并且这还只是三层网络的自编码,那么真正的深度学习可是很多层的,当很多层来了以后,其结果又会改善多少呢?下回继续介绍。
深度学习系列(七):自编码网络与PCA特征学习的分类对比实验
原文:https://www.cnblogs.com/panu-learning/p/14388446.html