论文地址:https://www.aclweb.org/anthology/2020.coling-main.136/
代码地址:未找到
Abstract
为了提高句子间的推理能力,我们提出用一个图增强的双注意网络Graph Enhanced Dual Attention network(GEDA)来刻画句子与潜在关系实例之间的复杂交互。在GEDA中,由句子-关系sentence-to-relation(S2R)注意产生的句子表示在被输入到句子-关系relation-to-sentence(R2S)注意之前,通过一个异构图卷积网络被细化和合成。基于S2R和R2S注意的自然对偶性,我们进一步设计了一个简单而有效的正则化器We further design a simple yet effective regularizer based on the natural duality of the S2R and R2S attention,在训练过程中,它的权值也由关系实例的支持证据supporting evidence of relation instances来监督。在现有的大规模数据集上进行的大量实验表明,该模型具有很好的性能,特别是在句间关系提取方面,同时神经网络的预测也具有很好的解释性和可观察性。
1 Introduction
我们引入了一种双向注意机制,包括句子到关系实例(sentence-to-relation,S2R)的注意和关系实例到句子(relation-to-sentence,R2S)的注意。创新之处在于以下三种设计基于经典的双向注意力:
Graph-enhancing operation:表达特定关系事实的句子可能位于文档的不同部分,例如远距离。如果我们用经典的注意机制生成句子表征,那么多个含噪句子之间的跨句信息合成可能不够准确。由于文档中的句子和实体自然形成了一个语义丰富的图,因此我们通过一个异构图卷积网络对S2R注意生成的句子表示进行细化和综合,然后将其输入R2S注意层,从而生成更精确的潜在关系实例表示。实验结果表明,这种图形增强操作有利于句间推理。
Regularizer of attention duality注意对偶的正则化:从直觉上看,句子对关系实例的关注程度越高,句子对关系实例的支持性证据就越多。反之,关系实例也应更多地关注句子,以获得更准确的表征。这一观察启发我们,在S2R和R2S注意之间存在着二元性。自然的对偶性可以为我们的架构提供一个有用的归纳偏差作为一个简单而有效的正则化。
Attention supervision from supporting evidence:通过以上两种新颖的设计,我们实现了一个具有图形增强双重注意力graph enhanced dual attention的体系结构。通常情况下,注意力权重是通过关系实例的ground truth信号进行隐式训练的。我们进一步利用关系实例的支持证据supporting evidence for relation instance作为R2S注意权重的监督信号,这也为我们的模型提供了更多的可解释性。【这是DocRED数据集第一个利用supporting evidence特性的论文】
2 Proposed Approach
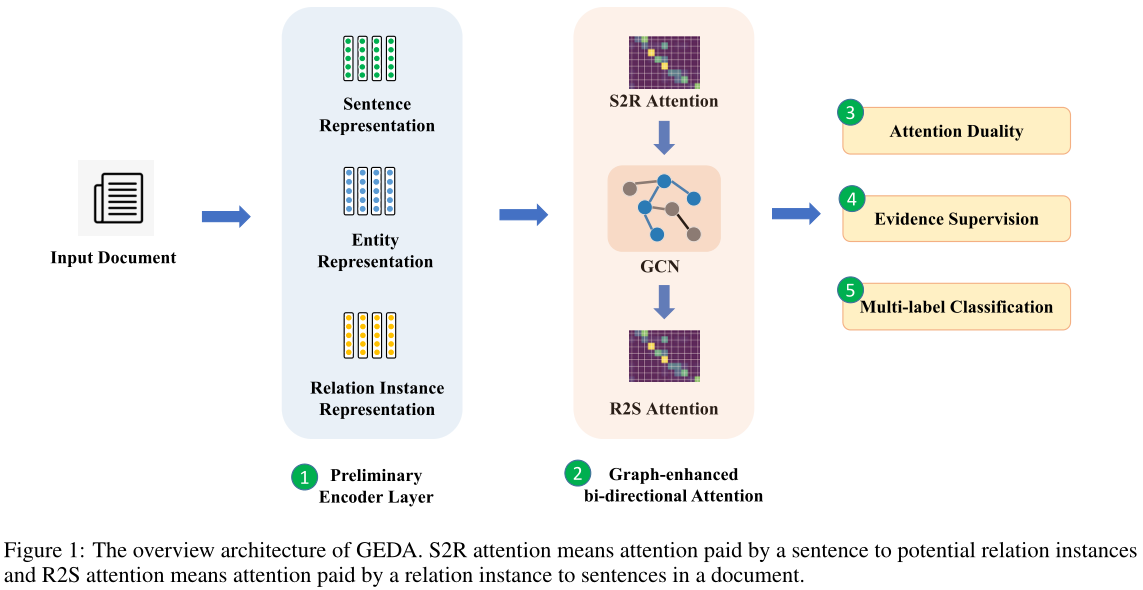
给定一个文档$D$包含$n$个单词,$m$个句子,$k$个不同的实体,将有$k·(k?1)$个潜在关系实例,我们的目标是以并行的方式提取所有潜在关系实例。GEDA主要由5个部分组成:1)编码层,生成句子、实体和关系实例的初步表示;2)图形增强的双向注意层,综合句内和句间信息,生成关系实例的精细表示;3) 作为正则化子的注意对偶约束;4)证据监督$loss$;5)和最终分类层,它将潜在关系实例的表示投影到每种关系类型的概率。
2.1 Encoding Layer
编码层首先将输入文档转换为实值矩阵,其中包含三种嵌入类型:1)单词嵌入;2)实体类型嵌入,表示每个单词的实体类型信息;3)实体顺序嵌入,表示其在文档中首次出现的顺序(Yao et al,2019). 利用一个具有$h$个隐藏单元的BiLSTM层作为编码器提取语义信息,将BiLSTM的输出表示为文档的语义表示$H$,其中$H∈R^{n×2h}$,然后基于$H$生成句子、实体和关系实例的初步表示。【DocRED那篇论文采用的编码方式】
Preliminary representations of sentences句子的初步表述:We use max-pooling to obtain the preliminary representation for each sentence. Here we use $l_i$ to denotes the preliminary representation of i-th sentence and $l_i∈ R^{1×2h}$.【没意外的话,应该是hidden最大维度那一维度来代表整个句子】
Preliminary representations of entities:对于一个实体,在文档中可能有不同的实体提及。作者对于文档中位于第a到第b个词的实体提及entity mentions $j$,$\hat{t}_j= \frac{1}{b-a+1}\sum^{b}_{loc = a}H_{loc}$,And $e_j$ is the average of all entity mention vectors of j-th entity, where $e_j∈ R^{1×2h}$.
Preliminary representations of relation instances:我们使用双线性函数生成每个实体对$<e_p,e_q>$的初步关系表示,其中$p,q∈[1,k]$和$p\ne q$。对于$k·(k?1)$潜在关系实例,将生成$k·(k?1)$向量。我们把它们叠加在一起作为一个初步的关系实例表示$T$,其中$T∈R^{k·(k?1)×d}$。
2.2 Graph-Enhanced Bi-directional Attention
图形增强的双向注意层旨在对句子与关系实例之间的复杂交互进行建模,通过综合句内和句间信息生成关系实例的精细表示。该组件由S2R层、GCN层和R2S层组成。
2.2.1 S2R Layer
S2R层输出句子的面向关系的表示,其中查询向量query vector是初步的句子表示$l_i$,key向量$v_j$是张量$T$的每一行。句子$i$对关系实例$j$关注的权重表示为$\alpha_{ij}$,计算如下:
$\alpha_{ij}=\frac{exp(w_{ij})}{\sum_{j=1}^{k·(k-1)}exp(w_{ij})}$
where $w_{ij}= l_i· W_1· v_j$, $l_i∈ R^{1×2h}$.We get the weighted combination all the attention vectors calculated over each row in $T$ as relation-oriented representation $pverline{l}_i$ of sentence $i$. where $\overline{l}_i=\sum^{k(k?1)}_{j=1} \alpha_{ij}· v_j$. Via S2R layer, we obtain an attention weight matrix $W_{S2R}∈ R^{m×k·(k?1)}$.
2.2.2 GCN Layer
在GEDA中,我们构建了一个具有两种类型节点的异构GCN:实体节点和句子节点。有三种不同的边缘:1)句子边缘,如果两个句子包含相同的实体,则连接两个句子节点;2)实体边缘,如果两个实体在一个句子中同时出现,则连接两个实体节点;3)实体句子边缘,如果实体位于句子中,则链接实体节点和句子节点。
由于实体表示法$e_i$与句子表示法$l_j$维数不同,用矩阵$W_2∈R^{2h×d}$将$e_i$转化为$e_i∈R^{1×d}$,然后计算GCN的特征矩阵$X=[\overline{e}_1;\overline{e}_2;…,\overline{e}_k;\overline{l}_1;\overline{l}_2;…;\overline{l}_m]$,其中$X∈R^{(k+m)×d}$。至于邻接矩阵$A∈R^{(k+m)×(k+m)}$,我们将对角元素设为1自我循环。如果边存在于两个节点之间,则边的权重设置为1,否则为0。对于一层GCN,我们可以通过以下等式得到新的节点特征矩阵$L∈R^{(m+k)×s}$:
$L=\rho(\hat{A}XW_3),\hat{A}=D^{-\frac{1}{2}}AD^{\frac{1}{2}}$
$\hat{A}$ is the normalized symmetric adjacency matrix.是归一化对称邻接矩阵。$W_3\in R^{d*s}$is a weight matrix.Output of GCN can be interpreted as two parts: 1) the refined entity representations as the first $k$ rows in $L$, denoted as $( \hat{e}_1, \hat{e}2, ..., \hat{e}_k)$; 2) the refined sentence representation ranging from the $(k + 1)$-th row to the $(k + m)$-th row in $L$, denoted as $(\hat{l}_1,\hat{l}_2, ...,\hat{l}_m)$. Then the bilinear function is applied on refined entity representation to obtain refined relation instance representation $\hat{T}$.
2.2.3 R2S Layer
与S2R层类似,R2S层用于获取面向句子的关系实例表示,区别在于两个方面:1)query向量为$\hat{T}$中的$\hat{v_i}$,表示每个关系实例;2)key向量为每个句子的表示$\hat{l}_j$。最后,R2S层输出所有潜在关系实例的面向句子的表示矩阵$\tilde{T}$,其中$\tilde{v}_i$是对应于第$i$个关系实例的第$i$行。得到了权矩阵$W_{R2S}∈ R^{k·(k?1)×m}$.
2.3 Regularizer of Attention Duality
句子对关系实例的注意与关系实例对句子的相反方向的注意是一致的,这意味着两个权重矩阵WS2R和WR2S之间存在一种自然的对偶性,我们利用这种对偶性设计了一个简单的正则化项来引入这一有用的概念感应偏压。此正则化器的数学表达式如下所示,其中$||·||_2$是L2正则化:
$r_{duality}=\frac{1}{m*k(k-1)}||W_{S2R}-W_{R2S}^T||_2$
2.4 Evidence Supervision
支持证据信息确定哪些句子有助于特定的关系实例。我们可以把这些信息转换成实值向量。例如,给定一个有m个句子的文档,对于第$i$个关系实例,如果前两句是支持证据,那么证据向量是:
$$
z = \overbrace{
[0.5,0.5,0,...,0]
}^\text{m}
$$
If a given relation instance can not be assigned to any relation type, the values in $c_i$ are then all set to 1/m.
请注意,$W_{R2S}$中的第$i$行称为$w_i$,是第$i$个关系实例对所有句子的注意权重。直观地说,$w_i$应该接近证据向量来关注最相关的句子。因此,我们使用Kullback-Leibler散度(Kullback和Leibler,1951)来衡量$c_i$和$w_i$之间的分布差异,作为额外损失。文档中所有潜在关系实例的loss如下所示:
$r_{evd}=\frac{1}{k·(k-1)}\sum_{i=1}^k·(k-1)D_{KL}(c_i|w_i)$
where $D_{KL}(p|q) =\sum_x p(x)log\frac{p(x)}{q(x)}$.
2.5 Classification Layer
由于我们场景中的关系预测是一个多标签问题,因此我们使用$\tilde{v}_i$($tilde{T}中的第$i$行)来预测第$i$个关系实例是否具有关系类型$r$:
$\hat{y}_r=\sigma(W_4\tilde{v}_i+b_4)$
最后,对于给定的文档包含$m$个句子、$k$个不同实体和$t$个预定义的关系类型,损失函数定义为:
$loss=\sum_{i=1}^{k*(k-1)}\sum_{r=1}^{t}y_r^ilog(\hat{y}_r^i)+\alpha r_{duality}+\beta r_{evd}+\lambda||\theta||_2$
where $y_r^i$ is a binary label of the i-th relation instance for the relation type $r$, $θ$ is the parameters that need to be regularized, and $||θ||_2$ is the L2-regularization, $α$, $β$, and $λ$ are the coefficients
3 Experiments
3.1 Dataset and Evaluation Metrics
Dataset:DocRED
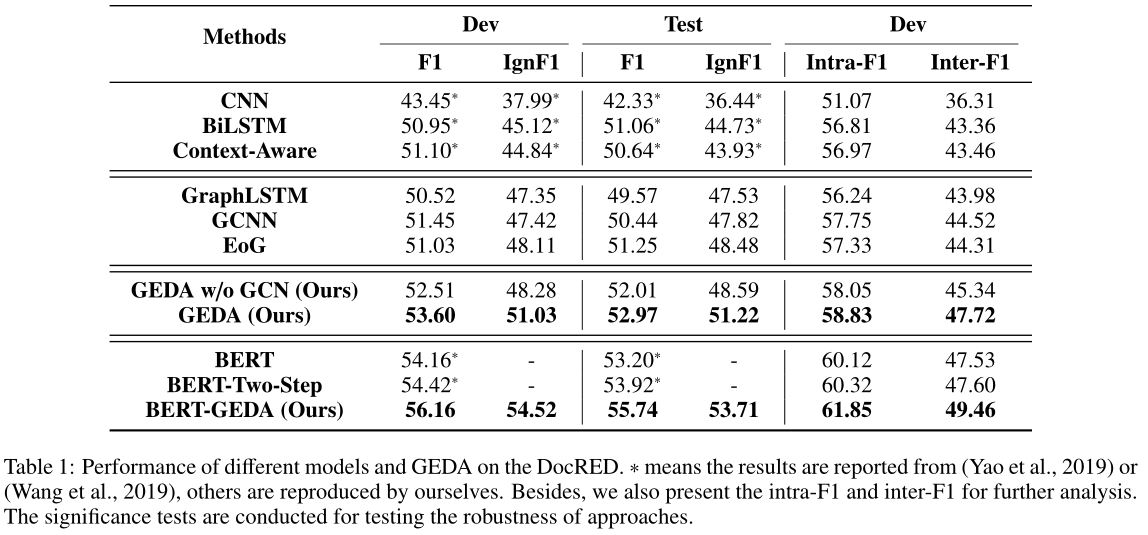
根据之前的工作(Yao et al.,2019),我们使用F1和IgnF1作为评估指标,其中IgnF1是在移除训练集中出现的实体对之后计算的。此外,为了评估句间推理能力,我们根据同一句中是否存在实体对将开发集分成两部分。报告两个拆分上的F1,分别命名为intra-F1和inter-F1。
3.2 Result
3.6 Effects of Core Components
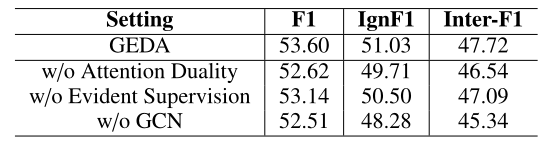
表2中的结果显示,三个组成部分都产生了显著的增强,验证了基于经典双向注意机制的三个新设计的有效性。同时,所有GEDA变体在IngF1和inter-F1上的性能下降比F1上更为显著。这一观察结果表明,这三个组成部分不仅提高了内部句子推理,而且为GEDA提供了更好的泛化能力,可以更准确地预测潜在关系实例。
3.7 Analysis of Attention Weights
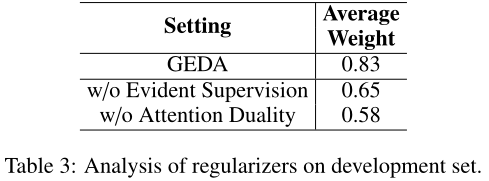
我们进一步研究了这两种正则化因子对注意权重的影响。对于每个关系实例,我们计算相关句子(支持证据)的R2S注意权重之和,然后得到它们在所有关系实例上的平均值。如表3所示,GEDA(我们的)的平均权重值大于其他两个场景的值。结果表明,这两个正则化子都能帮助GEDA更加关注相关句子。
3.8 Case Study and Visualization

为了促进对神经预测的理解,我们使用DocRED的一份包含8个句子的文件进行案例研究,如图2(a)所示。实体对{United States,Colorado}有3个相关的句子。由于缺乏对多个句子的推理能力,BiLSTM错误地标注实例,而GEDA可以进行句间推理,从而预测实体对的正确关系。同时,我们对GEDA产生的R2S注意权重进行了可视化处理。如图2(b)所示,“证据”行显示了文档中句子的基本事实注意权重。B-weight是由双向注意生成的,B-C-weight是由具有对偶约束的双向注意生成的,B-C-S-weight是通过进一步添加支持证据生成的注意权重。如图2(b)所示,通过结合对偶约束和监督注意,正确的句子被赋予更多的权重。可视化结果不仅验证了正则化算法的有效性,而且揭示了本文提出的GEDA算法的可解释性。
5 Conclusion
我们介绍了用于文档级关系抽取的神经结构GEDA。GEDA背后的直觉是更好地描述句子和关系实例之间的相互作用,从而改进整个文档的句间推理。GEDA的新颖性主要体现在基于图的句子表示精化和基于注意对偶和支持证据的两种简单而有效的正则化方法The novelty of GEDA mainly lies in the graph-based refinement of sentence representation and two simple yet effective regularizers based on attention duality and supporting evidence respectively。实验验证了图形增强的双重注意机制的优越性,特别是在句间关系提取方面。在未来,我们将研究更复杂的推理技术,针对更具体的句子间关系提取场景,例如,涉及常识推理。
参考:
今天NLP了吗:https://blog.csdn.net/li_jiaoyang/article/details/112093405
论文笔记:https://ivenwang.com/2021/01/07/geda/
【论文阅读】Graph Enhanced Dual Attention Network for Document-Level Relation Extraction[COLING2020]
原文:https://www.cnblogs.com/Harukaze/p/14389491.html