| 变量名称 | 说明 |
|---|---|
| tidb_slow_log_threshold | 设置慢日志的阈值,将执行时间超过阈值的 SQL 语句记录到慢日志中。默认值是 300 ms。 |
| tidb_query_log_max_len | 设置慢日志记录 SQL 语句的最大长度。默认值是 4096 byte。 |
| tidb_redact_log | 设置慢日志记录 SQL 时是否将用户数据脱敏用 ? 代替。默认值是 0 ,即关闭该功能。 |
| tidb_enable_collect_execution_info | 设置是否记录执行计划中各个算子的物理执行信息,默认值是 1。该功能对性能的影响约为 3%。 |
在性能测试中可以关闭自动收集算子的执行信息
set @@tidb_enable_collect_execution_info=0;
-- 查询慢日志记录的SQL最大长度
show variables like ‘tidb_query_log_max_len‘;
select @@tidb_query_log_max_len;
show config where type = ‘tidb‘ and name = ‘log.query-log-max-len‘;
TiDB 将执行时间超过slow-threshold(默认300毫秒)的语句输出到slow-query-file指定的文件中。
mysql> show config where type=‘tidb‘ and name like ‘%slow%‘;
+------+---------------------+-----------------------------+-------------------------+
| Type | Instance | Name | Value |
+------+---------------------+-----------------------------+-------------------------+
| tidb | 192.168.10.181:4000 | log.enable-slow-log | true |
| tidb | 192.168.10.181:4000 | log.record-plan-in-slow-log | 1 |
| tidb | 192.168.10.181:4000 | log.slow-query-file | log/tidb_slow_query.log |
| tidb | 192.168.10.181:4000 | log.slow-threshold | 300 |
+------+---------------------+-----------------------------+-------------------------+
4 rows in set, 1 warning (0.01 sec)
mysql>
TiDB 默认启用慢查询日志,可以修改配置 enable-slow-log 来启用或禁用它。
more /tidb/app/tidb-deploy/log/tidb_slow_query.log
# Time: 2021-01-12T08:51:51.284088475+08:00
# Txn_start_ts: 422160029355868163
# Query_time: 1.59885583
# Parse_time: 0.000342042
# Compile_time: 0.015516221
# Rewrite_time: 0.010854793
# Cop_time: 1.574503392 Process_time: 0.002 Wait_time: 0.003 Backoff_time: 1.51 Request_count: 1 Total_keys: 1
# Index_names: [bind_info:time_index]
# Is_internal: true
# Digest: fc950a72d4169f9e74f5e6a8e8aa06c30838aaaf55fdc67538bf14b69ddfb000
# Stats: bind_info:pseudo
# Num_cop_tasks: 1
# Cop_proc_avg: 0.002 Cop_proc_addr: 192.168.10.181:20160
# Cop_wait_avg: 0.003 Cop_wait_addr: 192.168.10.181:20160
# Cop_backoff_regionMiss_total_times: 10 Cop_backoff_regionMiss_total_time: 1.51
# Mem_max: 35400
# Prepared: false
# Plan_from_cache: false
# Has_more_results: false
# KV_total: 0.04573883
# PD_total: 0.007358997
# Backoff_total: 1.51
# Write_sql_response_total: 0
# Succ: true
# Plan: tidb_decode_plan(‘XXXXXXXXX‘)
# Plan_digest: bf4e638d559f82b64926f2b78be0c1d7ea7e7b8728a7e755cb60cd402a23d23e
select original_sql, bind_sql, default_db, status, create_time, update_time, charset, collation, source from mysql.bind_info order by update_time;
慢查询日志中所有时间相关字段的单位都是 “秒”
Time:表示日志打印时间。Query_time:表示执行这个语句花费的时间。Parse_time:表示这个语句在语法解析阶段花费的时间。Compile_time:表示这个语句在查询优化阶段花费的时间。Query:表示 SQL 语句。慢日志里面不会打印 Query,但映射到内存表后,对应的字段叫 Query。Digest:表示 SQL 语句的指纹。Txn_start_ts:表示事务的开始时间戳,也是事务的唯一 ID,可以用这个值在 TiDB 日志中查找事务相关的其他日志。Is_internal:表示是否为 TiDB 内部的 SQL 语句。true 表示 TiDB 系统内部执行的 SQL 语句,false 表示用户执行的 SQL 语句。Index_ids:表示语句涉及到的索引的 ID。Succ:表示语句是否执行成功。Backoff_time:表示语句遇到需要重试的错误时在重试前等待的时间,常见的需要重试的错误有以下几种:遇到了 lock、Region 分裂、tikv server is busy。Plan:表示语句的执行计划,用 select tidb_decode_plan(‘xxx...‘) SQL 语句可以解析出具体的执行计划。Prepared:表示这个语句是否是 Prepare 或 Execute 的请求。Plan_from_cache:表示这个语句是否命中了执行计划缓存。Rewrite_time:表示这个语句在查询改写阶段花费的时间。Preproc_subqueries:表示这个语句中被提前执行的子查询个数,如 where id in (select if from t) 这个子查询就可能被提前执行。Preproc_subqueries_time:表示这个语句中被提前执行的子查询耗时。Exec_retry_count:表示这个语句执行的重试次数。一般出现在悲观事务中,上锁失败时重试执行该语句。Exec_retry_time:表示这个语句的重试执行时间。例如某个查询一共执行了三次(前两次失败),则 Exec_retry_time 表示前两次的执行时间之和,Query_time 减去 Exec_retry_time 则为最后一次执行时间。Prewrite_time:表示事务两阶段提交中第一阶段(prewrite 阶段)的耗时。Commit_time:表示事务两阶段提交中第二阶段(commit 阶段)的耗时。Get_commit_ts_time:表示事务两阶段提交中第二阶段(commit 阶段)获取 commit 时间戳的耗时。Local_latch_wait_time:表示事务两阶段提交中第二阶段(commit 阶段)发起前在 TiDB 侧等锁的耗时。Write_keys:表示该事务向 TiKV 的 Write CF 写入 Key 的数量。Write_size:表示事务提交时写 key 或 value 的总大小。Prewrite_region:表示事务两阶段提交中第一阶段(prewrite 阶段)涉及的 TiKV Region 数量。每个 Region 会触发一次远程过程调用。Mem_max:表示执行期间 TiDB 使用的最大内存空间,单位为 byte。和硬盘使用相关的字段:
Disk_max: 表示执行期间 TiDB 使用的最大硬盘空间,单位为 byte。User:表示执行语句的用户名。Conn_ID:表示用户的链接 ID,可以用类似 con:3 的关键字在 TiDB 日志中查找该链接相关的其他日志。DB:表示执行语句时使用的 database。Request_count:表示这个语句发送的 Coprocessor 请求的数量。Total_keys:表示 Coprocessor 扫过的 key 的数量。Process_time:执行 SQL 在 TiKV 的处理时间之和,因为数据会并行的发到 TiKV 执行,这个值可能会超过 Query_time。Wait_time:表示这个语句在 TiKV 的等待时间之和,因为 TiKV 的 Coprocessor 线程数是有限的,当所有的 Coprocessor 线程都在工作的时候,请求会排队;当队列中有某些请求耗时很长的时候,后面的请求的等待时间都会增加。Process_keys:表示 Coprocessor 处理的 key 的数量。相比 total_keys,processed_keys 不包含 MVCC 的旧版本。如果 processed_keys 和 total_keys 相差很大,说明旧版本比较多。Cop_proc_avg:cop-task 的平均执行时间。Cop_proc_p90:cop-task 的 P90 分位执行时间。Cop_proc_max:cop-task 的最大执行时间。Cop_proc_addr:执行时间最长的 cop-task 所在地址。Cop_wait_avg:cop-task 的平均等待时间。Cop_wait_p90:cop-task 的 P90 分位等待时间。Cop_wait_max:cop-task 的最大等待时间。Cop_wait_addr:等待时间最长的 cop-task 所在地址。Cop_backoff_{backoff-type}_total_times:因某种错误造成的 backoff 总次数。Cop_backoff_{backoff-type}_total_time:因某种错误造成的 backoff 总时间。Cop_backoff_{backoff-type}_max_time:因某种错误造成的最大 backoff 时间。Cop_backoff_{backoff-type}_max_addr:因某种错误造成的最大 backoff 时间的 cop-task 地址。Cop_backoff_{backoff-type}_avg_time:因某种错误造成的平均 backoff 时间。Cop_backoff_{backoff-type}_p90_time:因某种错误造成的 P90 分位 backoff 时间。通过查询 INFORMATION_SCHEMA.SLOW_QUERY 表来查询慢查询日志中的内容,表中列名和慢日志中字段名一一对应。每次查询 SLOW_QUERY 表时,TiDB 都会去读取和解析一次当前的慢查询日志。 在TiDB 4.0 中新增了 CLUSTER_SLOW_QUERY 系统表,用来查询所有 TiDB 节点的慢查询信息。
select count(*),
min(time),
max(time)
from information_schema.slow_query;
select count(*),
min(time),
max(time)
from information_schema.slow_query
where time > ‘2021-01-12 00:00:00‘
and time < ‘2021-01-13 00:00:00‘;

SELECT * FROM
(SELECT /*+ AGG_TO_COP(), HASH_AGG() */ count(*),
min(time),
sum(query_time) AS sum_query_time,
sum(Process_time) AS sum_process_time,
sum(Wait_time) AS sum_wait_time,
sum(Commit_time),
sum(Request_count),
sum(process_keys),
sum(Write_keys),
max(Cop_proc_max),
min(query),min(prev_stmt),
digest
FROM information_schema.CLUSTER_SLOW_QUERY
WHERE time >= ‘2021-01-12 09:00:00‘
AND time < ‘2021-01-12 10:00:00‘
AND Is_internal = false
GROUP BY digest) AS t1
WHERE t1.digest NOT IN
(SELECT /*+ AGG_TO_COP(), HASH_AGG() */ digest
FROM information_schema.CLUSTER_SLOW_QUERY
WHERE time >= ‘2021-01-12 09:00:00‘
AND time < ‘2021-01-12 10:00:00‘
GROUP BY digest)
ORDER BY t1.sum_query_time DESC limit 10\G
-- is_internal=false 表示排除 TiDB 内部的慢查询,只看用户的慢查询
select query_time, query
from information_schema.slow_query
where is_internal = false -- 排除 TiDB 内部的慢查询 SQL
order by query_time desc
limit 2;
统计信息为 pseudo : 表示可能因为没有统计信息,或者统计信息过旧,不会用统计信息来进行估算。
select query, query_time, stats
from information_schema.slow_query
where is_internal = false
and stats like ‘%pseudo%‘;
--
select instance, query, query_time, stats
from information_schema.cluster_slow_query
where is_internal = false
and stats like ‘%pseudo%‘;
select count(distinct plan_digest) as count,
digest,
min(query)
from information_schema.cluster_slow_query
group by digest
having count > 1
limit 3\G
select instance, count(*) from information_schema.cluster_slow_query
where time >= "2021-01-12 00:00:00"
and time < now()
group by instance;
pt-query-digest 工具分析慢日志建议使用 pt-query-digest 3.0.13 及以上版本。
admin show slow 命令通过 admin show slow SQL 命令定位慢查询,默认只返回用户 SQL 中的慢查询记录。
-- 显示最近的 N 条慢查询记录
admin show slow recent N;
-- 如:显示最近的 10 条慢查询记录
admin show slow recent 10;
-- top N 则显示最近一段时间(大约几天)内,最慢的查询记录
admin show slow top [internal | all] N;
-- 指定 internal 选项,则返回查询系统内部 SQL 的慢查询记录
-- 指定 all 选项,返回系统内部和用户 SQL 汇总以后的慢查询记录
admin show slow top 3;
admin show slow top internal 3;
admin show slow top all 5;
注意:
由于内存限制,保留的慢查询记录的条数是有限的。当命令查询的 N 大于记录条数时,返回的结果记录条数会小于 N。
TiDB 处理查询过程的关键阶段如下图:
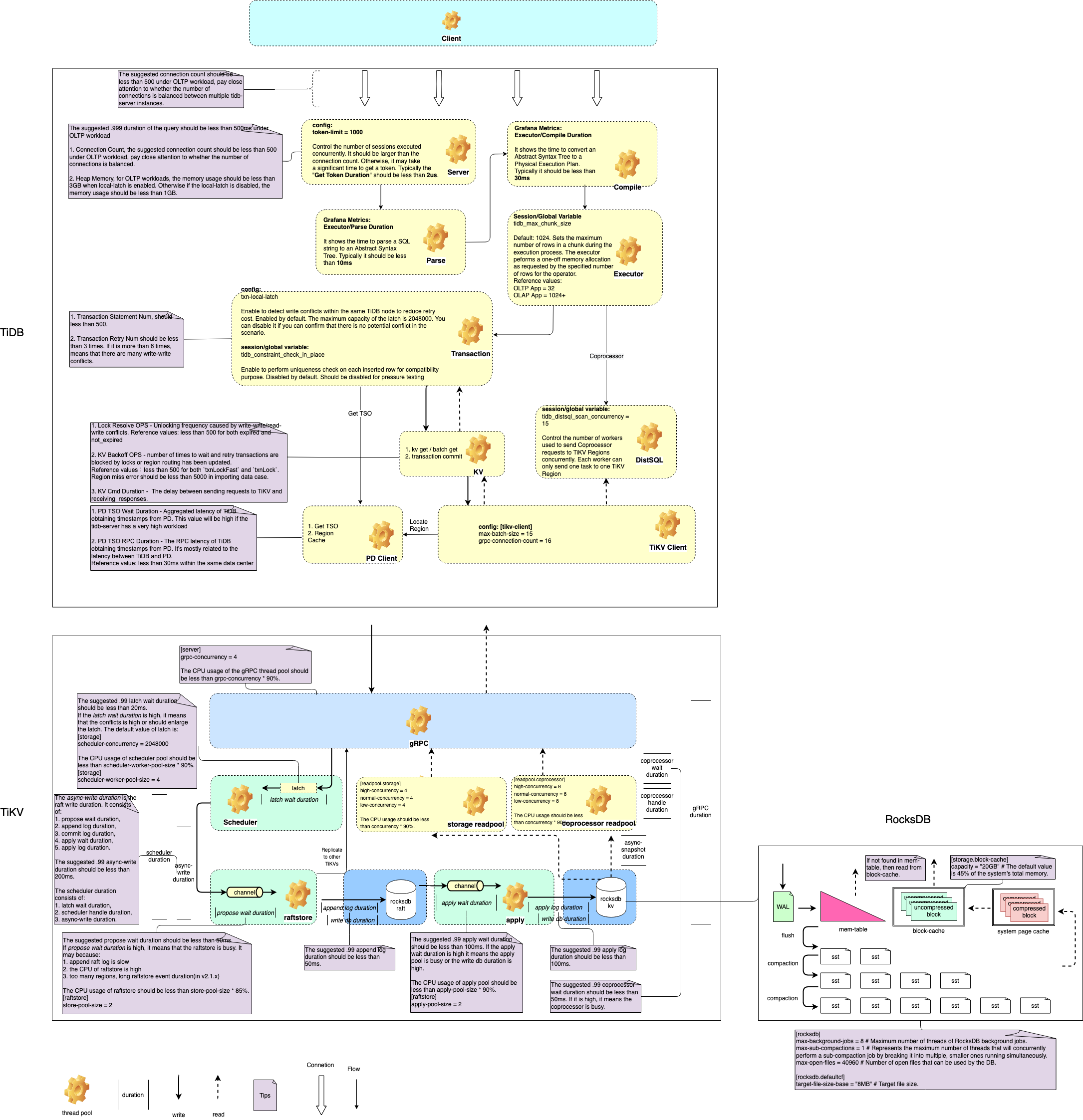
http://PD-IP:2379/dashboard/#/slow_query)
TiDB 会将执行时间超过 tidb_expensive_query_time_threshold 限制(默认值为 60s),或使用内存超过 mem-quota-query 限制(默认值为 1 GB)的语句输出到 tidb-server 日志文件(默认文件为 “tidb.log”)中。用于在语句执行结束前定位消耗系统资源多的查询语句(以下简称为 expensive query),帮助分析和解决语句执行的性能问题。
注意:expensive query 日志和慢查询日志的区别是,慢查询日志是在语句执行完后才打印,而 expensive query 日志可以将正在执行的语句的相关信息打印出来。当一条语句在执行过程中达到资源使用阈值时(执行时间/使用内存量),TiDB 会即时将这条语句的相关信息写入日志。
[WARN] [expensivequery.go:167] [expensive_query] [cost_time=60.008338935s] [wait_time=0s] [request_count=1] [total_keys=70] [process_keys=65] [num_cop_tasks=1] [process_avg_time=0s] [process_p90_time=0s] [process_max_time=0s] [process_max_addr=10.0.1.9:20160] [wait_avg_time=0.002s] [wait_p90_time=0.002s] [wait_max_time=0.002s] [wait_max_addr=10.0.1.9:20160] [stats=t:pseudo] [conn_id=60026] [user=root] [database=test] [table_ids="[122]"] [txn_start_ts=414420273735139329] [mem_max="1035 Bytes (1.0107421875 KB)"] [sql="insert into t select sleep(1) from t"]
基本字段:
cost_time:日志打印时语句已经花费的执行时间。stats:语句涉及到的表或索引使用的统计信息版本。值为 pesudo 时表示无可用统计信息,需要对表或索引进行 analyze。table_ids:语句涉及到的表的 ID。txn_start_ts:事务的开始时间戳,也是事务的唯一 ID,可以用这个值在 TiDB 日志中查找事务相关的其他日志。sql:SQL 语句。和内存使用相关的字段:
mem_max:日志打印时语句已经使用的内存空间。该项使用两种单位标识内存使用量,分别为 Bytes 以及易于阅读的自适应单位(比如 MB、GB 等)。和 SQL 执行的用户相关的字段:
user:执行语句的用户名。conn_id:用户的连接 ID,可以用类似 con:60026 的关键字在 TiDB 日志中查找该连接相关的其他日志。database:执行语句时使用的 database。和 TiKV Coprocessor Task 相关的字段:
wait_time:该语句在 TiKV 的等待时间之和,因为 TiKV 的 Coprocessor 线程数是有限的,当所有的 Coprocessor 线程都在工作的时候,请求会排队;当队列中有某些请求耗时很长的时候,后面的请求的等待时间都会增加。request_count:该语句发送的 Coprocessor 请求的数量。total_keys:Coprocessor 扫过的 key 的数量。processed_keys:Coprocessor 处理的 key 的数量。与 total_keys 相比,processed_keys 不包含 MVCC 的旧版本。如果 processed_keys 和 total_keys 相差很大,说明旧版本比较多。num_cop_tasks:该语句发送的 Coprocessor 请求的数量。process_avg_time:Coprocessor 执行 task 的平均执行时间。process_p90_time:Coprocessor 执行 task 的 P90 分位执行时间。process_max_time:Coprocessor 执行 task 的最长执行时间。process_max_addr:task 执行时间最长的 Coprocessor 所在地址。wait_avg_time:Coprocessor 上 task 的等待时间。wait_p90_time:Coprocessor 上 task 的 P90 分位等待时间。wait_max_time:Coprocessor 上 task 的最长等待时间。wait_max_addr:task 等待时间最长的 Coprocessor 所在地址。从TiDB 4.0开始,在 information_schema 中提供了用于监控和统计 SQL 的系统表,帮助分析定位SQL的性能问题。
statements_summary : 把 SQL 按 SQL digest 和 plan digest 分组,统计每一组的 SQL 信息。
statements_summary 里的数据定期被清空,只展现最近一段时间内的聚合结果。清空周期由系统变量 tidb_stmt_summary_refresh_interval 设置。statements_summary_history : 与 statements_summary 完全相同的表结构,用于保存历史时间段的数据。cluster_statements_summary : 显示各台 TiDB server 的 statements_summary 数据cluster_statements_summary_history : 显示各台 TiDB server 的 statements_summary_history 数据上面2个集群系统表使用用字段 INSTANCE 表示 TiDB server 的地址。
注意:重启TiDB后,上面的4张系统表的数据会清空。因为它们是内存表,不会持久化数据。
STMT_TYPE:SQL 语句的类型SCHEMA_NAME:执行这类 SQL 的当前 schemaDIGEST:这类 SQL 的 digestDIGEST_TEXT:规一化后的 SQLQUERY_SAMPLE_TEXT:这类 SQL 的原 SQL 语句,多条语句只取其中一条TABLE_NAMES:SQL 中涉及的所有表,多张表用 , 分隔INDEX_NAMES:SQL 中使用的索引名,多个索引用 , 分隔SAMPLE_USER:执行这类 SQL 的用户名,多个用户名只取其中一个PLAN_DIGEST:执行计划的 digestPLAN:原执行计划,多条语句只取其中一条的执行计划PLAN_CACHE_HITS:这类 SQL 语句命中 plan cache 的总次数PLAN_IN_CACHE:这类 SQL 语句的上次执行是否命中了 plan cacheSUMMARY_BEGIN_TIME:当前统计的时间段的开始时间SUMMARY_END_TIME:当前统计的时间段的结束时间FIRST_SEEN:这类 SQL 的首次出现时间LAST_SEEN:这类 SQL 的最后一次出现时间EXEC_COUNT:这类 SQL 的总执行次数SUM_ERRORS:执行过程中遇到的 error 的总数SUM_WARNINGS:执行过程中遇到的 warning 的总数SUM_LATENCY:这类 SQL 的总延时MAX_LATENCY:这类 SQL 的最大延时MIN_LATENCY:这类 SQL 的最小延时AVG_LATENCY:这类 SQL 的平均延时AVG_PARSE_LATENCY:解析器的平均延时MAX_PARSE_LATENCY:解析器的最大延时AVG_COMPILE_LATENCY:优化器的平均延时MAX_COMPILE_LATENCY:优化器的最大延时AVG_MEM:使用的平均内存,单位 byteMAX_MEM:使用的最大内存,单位 byteAVG_DISK:使用的平均硬盘空间,单位 byteMAX_DISK:使用的最大硬盘空间,单位 byteSUM_COP_TASK_NUM:发送 Coprocessor 请求的总数MAX_COP_PROCESS_TIME:cop-task 的最大处理时间MAX_COP_PROCESS_ADDRESS:执行时间最长的 cop-task 所在地址MAX_COP_WAIT_TIME:cop-task 的最大等待时间MAX_COP_WAIT_ADDRESS:等待时间最长的 cop-task 所在地址AVG_PROCESS_TIME:SQL 在 TiKV 的平均处理时间MAX_PROCESS_TIME:SQL 在 TiKV 的最大处理时间AVG_WAIT_TIME:SQL 在 TiKV 的平均等待时间MAX_WAIT_TIME:SQL 在 TiKV 的最大等待时间AVG_BACKOFF_TIME:SQL 遇到需要重试的错误时在重试前的平均等待时间MAX_BACKOFF_TIME:SQL 遇到需要重试的错误时在重试前的最大等待时间AVG_TOTAL_KEYS:Coprocessor 扫过的 key 的平均数量MAX_TOTAL_KEYS:Coprocessor 扫过的 key 的最大数量AVG_PROCESSED_KEYS:Coprocessor 处理的 key 的平均数量。相比 avg_total_keys,avg_processed_keys 不包含 MVCC 的旧版本。如果 avg_total_keys 和 avg_processed_keys 相差很大,说明旧版本比较多MAX_PROCESSED_KEYS:Coprocessor 处理的 key 的最大数量AVG_PREWRITE_TIME:prewrite 阶段消耗的平均时间MAX_PREWRITE_TIME prewrite 阶段消耗的最大时间AVG_COMMIT_TIME:commit 阶段消耗的平均时间MAX_COMMIT_TIME:commit 阶段消耗的最大时间AVG_GET_COMMIT_TS_TIME:获取 commit_ts 的平均时间MAX_GET_COMMIT_TS_TIME:获取 commit_ts 的最大时间AVG_COMMIT_BACKOFF_TIME:commit 时遇到需要重试的错误时在重试前的平均等待时间MAX_COMMIT_BACKOFF_TIME:commit 时遇到需要重试的错误时在重试前的最大等待时间AVG_RESOLVE_LOCK_TIME:解决事务的锁冲突的平均时间MAX_RESOLVE_LOCK_TIME:解决事务的锁冲突的最大时间AVG_LOCAL_LATCH_WAIT_TIME:本地事务等待的平均时间MAX_LOCAL_LATCH_WAIT_TIME:本地事务等待的最大时间AVG_WRITE_KEYS:写入 key 的平均数量MAX_WRITE_KEYS:写入 key 的最大数量AVG_WRITE_SIZE:写入的平均数据量,单位 byteMAX_WRITE_SIZE:写入的最大数据量,单位 byteAVG_PREWRITE_REGIONS:prewrite 涉及的平均 Region 数量MAX_PREWRITE_REGIONS:prewrite 涉及的最大 Region 数量AVG_TXN_RETRY:事务平均重试次数MAX_TXN_RETRY:事务最大重试次数SUM_BACKOFF_TIMES:这类 SQL 遇到需要重试的错误后的总重试次数BACKOFF_TYPES:遇到需要重试的错误时的所有错误类型及每种类型重试的次数,格式为 类型:次数。如有多种错误则用 , 分隔,例如 txnLock:2,pdRPC:1AVG_AFFECTED_ROWS:平均影响行数PREV_SAMPLE_TEXT:当 SQL 是 COMMIT 时,该字段为 COMMIT 的前一条语句;否则该字段为空字符串。当 SQL 是 COMMIT 时,按 digest 和 prev_sample_text 一起分组,即不同 prev_sample_text 的 COMMIT 也会分到不同的行tidb_enable_stmt_summary:是否打开 statement summary 功能。1 代表打开,0 代表关闭,默认打开。statement summary 关闭后,系统表里的数据会被清空,下次打开后重新统计。经测试,打开后对性能几乎没有影响。tidb_stmt_summary_refresh_interval:statements_summary 的清空周期,单位是秒 (s),默认值是 1800。tidb_stmt_summary_history_size:statements_summary_history 保存每种 SQL 的历史的数量,默认值是 24。tidb_stmt_summary_max_stmt_count:statement summary tables 保存的 SQL 种类数量,默认 200 条。当 SQL 种类超过该值时,会移除最近没有使用的 SQL。tidb_stmt_summary_max_sql_length:字段 DIGEST_TEXT 和 QUERY_SAMPLE_TEXT 的最大显示长度,默认值是 4096。tidb_stmt_summary_internal_query:是否统计 TiDB 的内部 SQL。1 代表统计,0 代表不统计,默认不统计。注意:
tidb_stmt_summary_history_size、tidb_stmt_summary_max_stmt_count、tidb_stmt_summary_max_sql_length 这些配置都影响内存占用,建议根据实际情况调整,不宜设置得过大。
TiDB 提供了 global 和 session 两种作用域。
-- 每 30 分钟清空一次。因为 24 * 30 分钟 = 12 小时,所以 statements_summary_history 保存最近 12 小时的历史数据。
set global tidb_enable_stmt_summary = true;
set global tidb_stmt_summary_refresh_interval = 1800; -- 30 分钟
set global tidb_stmt_summary_history_size = 24;
原文:https://www.cnblogs.com/binliubiao/p/14393233.html