一、文本操作命令
文本操作命令
? cat
? more
? less
? head
? head -2 /etc/profile
? tail
? tail -2 /etc/profile
? tail -f 实时监控日志,日志不断增长时,可以看到最新的当前的日志
如果只想看第 4 行日志,应该怎么办?可以借助管道的概念
[root@localhost ~]# head -4 install.log.syslog2 | tail -1
4d
类似于取交集??
? 管道
? cat b.txt | head -3
打开文本b 输入到管道 管道后的进程读取文本前三行;管道前后相当于开两个子进程
[root@localhost ~]# echo $$
4743
$$ 代表当前进程的PID
[root@minicent6~]# echo $$
1169 现在是在父进程中
[root@minicent6~]# /bin/bash 打开一个bash,开了一个子进程
[root@minicent6~]# echo$$ 所以进程号变了
1375
[root@minicent6~]# /bin/bash 又打开一个bash,用pstree查看进程结构
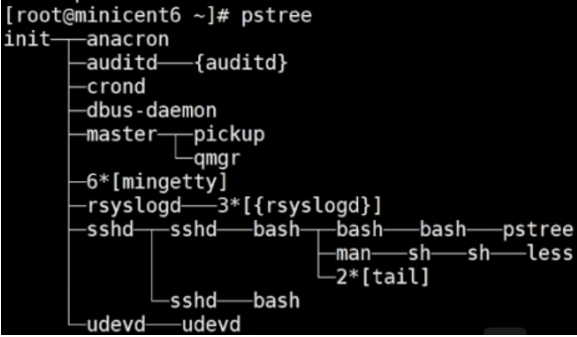
[root@minicent6~]# exit 退出到父进程
exit
[root@minicent6~]# echo $$ 退回到 1375
1375
[root@minicent6~]# exit 退出后,pstree查看进程,只有一个了
exit
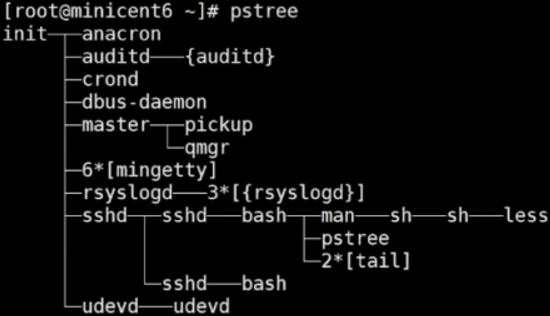
[root@minicent6~]# echo $$ 打印PID和最初的是一样的,退回到最上面的进程
1169
所以管道符会自动打开两个进程,而且都是当前进程的子进程,通过bash打开交互
把 cat b.txt的输出作为 head -3 子进程的输入,同时 cat b.txt进程关闭,head -3进程执行完成后也会关闭子进程,输出结果后,回到当前的父进程
? | tail -1
? xargs
? shell读取用户输入的字符串
? 发现 |,代表有管道
? | 左右被理解为简单命令
? 加工:前一个(左边)简单命令的标准输出
? 指向后一个(右边)简单命令的标准输入
? 注意:后一个简单命令一定能够接受标准输入
一个命令的出现一定是为了解决某个问题
如果在root路径下,但是想看etc目录下的内容 可以
[root@localhost ~]# ls -l /etc
? xargs:
? 命令
? 1,在标准输入中读取到的内容!
? 2,自己的参数理解为一个字符串
? 模仿shell,做blank切分,第一个子字符串为命令
? 3,将步骤1的内容做为步骤2的命令的选项参数拼接起来
? 4,执行得到的结果
? echo "/" | xargs ls -l
现在在脚本里,想把目录作为变量输入管道后的命令
[root@localhost ~]# echo "/" | ls -l
总用量 12
-rw-------. 1 root root 1523 1月 25 15:15 anaconda-ks.cfg
……
这种方式失败了,并没有接成输入,显示的还是当前目录root下的内容,这时可以用xargs
[root@localhost ~]# echo "/" | xargs ls -l
总用量 28
lrwxrwxrwx. 1 root root 7 1月 25 15:06 bin -> usr/bin
dr-xr-xr-x. 5 root root 4096 1月 25 15:21 boot
drwxr-xr-x. 20 root root 3300 2月 8 21:45 dev
……
现在显示的就是根目录下的内容,xargs把前面的命令作为一个参数传到后面
? 打开文件
? vim /path/to/somefile
? vim +# :打开文件,并定位于第#行
? vim +:打开文件,定位至最后一行
? vim +/PATTERN : 打开文件,定位至第一次被PATTERN匹配到的行的行首
vi 是 vim的简化版本,一般vim是需要自己去安装的
[root@localhost ~]# yum -i install vim
如果打开的文本很长,现在需要定位到某一行,不想上下滚动
[root@localhost em]# vi +5 profile
光标就会在第5行的位置,shift+冒号进入末行模式,在末行模式输入:set nu,可以打印行数;输入:set nonu,取消打印行数
如果想直接进入最后一行
[root@localhost em]# vi + profile
如果已经 vi profile 进入命令模式了,想要定位在最后一行,可以按 shift+g,进入末行
如果配置文件中的某个字符有误,可以直接查找定位到某个字的位置
/是查找的意思,+可以表示增加的功能 +/after,增加查找after的功能
[root@localhost em]# vi +/after profile
? 关闭文件
? 末行模式:
? :q 退出 没有动过文件
? :wq 保存并退出 动过了,不后悔
? :q! 不保存并退出 动过了,后悔了
? :w 保存
? :w! 强行保存
? :wq --> :x
? ZZ: 保存并退出 不需要冒号,编辑模式
全屏编辑器
模式:
编辑模式:按键具有编辑文本功能:默认打开进入编辑模式
输入模式:按键本身意义
末行模式:接受用户命令输入文本操作命令
在输入模式按ESC退出insert插入模式的界面上,可以按 hjkl上下左右控制光标
? 编辑-->输入:
? i: 在当前光标所在字符的前面,转为输入模式;
? a: 在当前光标所在字符的后面,转为输入模式;
? o: 在当前光标所在行的下方,新建一行,并转为输入模式;
? O:在当前光标所在行的上方,新建一行,并转为输入模式;
? I:在当前光标所在行的行首,转换为输入模式
? A:在当前光标所在行的行尾,转换为输入模式
? 输入-->编辑:
? ESC
? 编辑-->末行:
? :
? 末行-->编辑:
? ESC, ESC (按两次ESC)
末行模式 shift+冒号,末行模式也可以进行查找,比如 :/after,查找词after
末行模式允许我们对文档输入一些命令,并不会改变文档本身的内容
编辑模式
? 移动光标
? 删除&替换单个字符
? 删除命令
? 复制粘贴
? 撤销&重做
? 移动光标
? 字符
? h: 左;j: 下;k: 上;l: 右
? 单词
? w: 移至下一个单词的词首
? e: 跳至当前或下一个单词的词尾
? b: 跳至当前或前一个单词的词首
? 行内
? 0: 绝对行首
? ^: 行首的第一个非空白字符
? $: 绝对行尾
? 行间
? G:文章末尾
? 3G:第3行
数字+g,组合键,要快速按,就像打游戏的组合键一样
? gg:文章开头
? 翻屏
? ctrl:f,b
? 删除&替换单个字符
? x:删除光标位置字符
? 3x:删除光标开始3个字符
注意是下方没有 insert的编辑模式
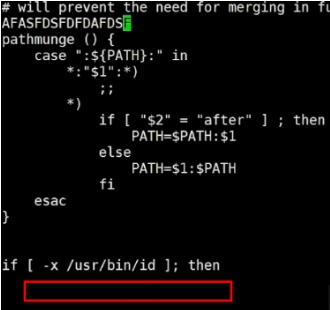
? r:替换光标位置字符
? 删除命令 : d ,2d
? dw,dd
d 删除一行,2d删除两行
dw 删除一个单词,dd和d是一样的效果
? 复制粘贴&剪切
? yw,yy
? p
? P
yw就是复制一个单词,和dw相似,单行一个d或者y就可以,加上行数时一定要dd或者yy
? 撤销&重做
? u 撤销
? ctrl+r 重做 撤销的操作
? . 重复上一步的操作
末行模式
? set:设置
? set nu number
? set nonu nonumber
? set readonly (设置只读)
? /:查找
? /after
? n,N (N向上查找,n向下查找)
? ?向上查找
? !:执行命令
? :!ls -l /
? s查找并替换
? s/str1/str2/gi
? /:临近s命令的第一个字符为边界字符:/,@,#
? g:一行内全部替换
? i:忽略大小写
? 范围
? n:行号
? .:当前光标行
? +n:偏移n行
? $:末尾行,$-3
? %:全文文本处理文本处理的几种方法
二、文本处理:cut、sort和wc
文本处理的几种方法
? cut
? sort
? wc
? awk
? cut:显示切割的行数据
? f:选择显示的列
? s:不显示没有分隔符的行
? d:自定义分隔符
[root@localhost ~]# cat grep.txt
aazz12121212aazz
aazz 12121212
aaz 12121212
1212 aazz 1212
aa3zz
aa4zz
aaEzz
aamzz
$aazz
aa1234zz
aaopqzz
现在只想显示第一列,应该怎么做?可以用空格分割
[root@localhost ~]# cut -d ‘ ‘ -f1 grep.txt
aazz12121212aazz
aazz
aaz
1212
aa3zz
aa4zz
aaEzz
aamzz
$aazz
aa1234zz
aaopqzz
如果显示第一至第三列
[root@localhost ~]# cut -d ‘ ‘ -f1-3 grep.txt
如果显示第一 和第三列
[root@localhost ~]# cut -d ‘ ‘ -f1,3 grep.txt
aazz12121212aazz
aazz
aaz
1212 1212
aa3zz
aa4zz
aaEzz
aamzz
$aazz
aa1234zz
aaopqzz
但是,只有一列的也在里面,这样的数据叫做“脏数据”,可以用 -s 排掉,就可以找到有三列的数据
[root@localhost ~]# cut -s -d ‘ ‘ -f1,3 grep.txt
aazz
aaz
1212 1212
? sort:排序文件的行
? n:按数值排序
? r:倒序
? t:自定义分隔符
? k:选择排序列
? u:合并相同行
? f:忽略大小写
[root@localhost ~]# cat sort.txt
banana 12
apple 1
orange 8
如果这是一个产品价目表,按产品价格对其进行排序,k2 表示按第 2 列排序
[root@localhost ~]# sort -t ‘ ‘ -k2 -nr sort.txt
banana 12
orange 8
apple 1
如果把n去掉,默认按字典排序
[root@localhost ~]# sort -t ‘ ‘ -k2 -r sort.txt
orange 8
banana 12
apple 1
wc word count 单词计数 -l 按行计数
[root@localhost ~]# cat sort.txt
banana 12
apple 1
orange 8
[root@localhost ~]# wc -l sort.txt
3 sort.txt
如果在写脚本文件,想把计算的行数作为一个变量,想去掉 sort.txt
[root@localhost ~]# cat sort.txt | wc -l
3
这样就只显示 3 了,利用管道,先读出文本,把文本传给wc,这样就不会因为命令把名字显示出来了
三、文本处理:awk
awk
? awk是一个强大的文本分析工具。
? 相对于grep的查找,awk在其对数据分析并生成报告时,显得尤为强大。
? 简单来说awk就是把文件逐行的读入,(空格,制表符)为默认分隔符将每行切片,切开的部分再进行各种分析处理。
如何在程序里使用定义变量?如果不加引号,执行到空格后,会认为是下一个命令
所以需要把整个的命令用反引号引入
[root@localhost ~]# lines=`cat sort.txt | wc -l`
[root@localhost ~]# echo $lines
3
[root@localhost ~]# cat sort.txt | grep banana
banana 12
[root@localhost ~]# cat /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
……
显示所有用户,bin等用户不是登录用户;
root(用户):x:0:0:root(所在组):/root(登录进来的家目录):/bin/bash(/bin/bash指用户一登录进来能够执行的程序 )
? awk -F ‘{pattern + action}‘ {filenames}
? 支持自定义分隔符
? 支持正则表达式匹配
? 支持自定义变量,数组 a[1] a[tom] map(key)
? 支持内置变量
? ARGC 命令行参数个数
? ARGV 命令行参数排列
? ENVIRON 支持队列中系统环境变量的使用
? FILENAME awk 浏览的文件名
? FNR 浏览文件的记录数
? FS 设置输入域分隔符,等价于命令行 -F 选项
? NF 浏览记录的域的个数
? NR 已读的记录数
? OFS 输出域分隔符
? ORS 输出记录分隔符
? RS 控制记录分隔符
? 支持函数
? print、split、substr、sub、gsub
? 支持流程控制语句,类C语言
? if、while、do/while、for、break、continue
? 只是显示/etc/passwd的账户:CUT
? awk -F‘:‘ ‘{print $1}‘ passwd
[root@localhost etc]# awk -F‘:‘ ‘{print $1}‘ passwd
root
bin
daemon
adm
……
只显示了第一列用户名,awk 可以理解为一段程序,是一个 命令,-F是定义分隔符,以冒号定义分隔符;‘{print $1}‘可以理解为一个程序,方法名大括号中包含程序内容,没有方法名,可以理解为匿名方法;print是它的语法; $1表示 第 1 列
? 只是显示/etc/passwd的账户和账户对应的shell,而账户与shell之间以逗号分割,而且在所有行开始前添加列名name,shell,在最后一行添加"blue,/bin/nosh"(cut,sed)
? awk -F‘:‘ ‘BEGIN{print "name,shell"} {print $1 "," $7} END{print"blue,/bin/nosh"}‘ passwd
对应的shell是指最末尾那一行
[root@localhost etc]# awk -F‘:‘ ‘BEGIN{print "name,shell"} {print $1 "," $7} END{print"blue,/bin/nosh"}‘ passwd
name,shell
root,/bin/bash
bin,/sbin/nologin
daemon,/sbin/nologin
adm,/sbin/nologin
lp,/sbin/nologin
……
tcpdump,/sbin/nologin
malakh,/bin/bash
blue,/bin/nosh
相当于制作了一个表头,表头第1列是name,第2列是执行的shell,最后表尾,blue,/bin/nosh
{print $1 "," $7} 读取每一行的时候,以逗号分隔每一行的值,表头是awk内置的一个函数
BEGIN{print "name,shell"} 只在第一行操作
? 搜索/etc/passwd有root关键字的所有行
? awk ‘/root/ { print $0}‘ passwd
比如查找所有 root 的关键行,并显示出来
[root@localhost etc]# awk ‘/root/ { print $0}‘ passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
? 统计/etc/passwd文件中,每行的行号,每行的列数,对应的完整行内容
? 统计报表:合计每人1月工资,0:manager,1:worker
? Tom 0 2012-12-11 car 3000
? John 1 2013-01-13 bike 1000
? Vivi 1 2013-01-18 car 2800
? Tom 0 2013-01-20 car 2500
? John 1 2013-01-28 bike 3500
? E
? awk ‘{gsub("0","manager",$2);gsub("1","worker",$2);;split($3,month,"-");if(month[2]=="01"){name[$1]+=$5}} ND{for( i in name){print i "\t"name[i]}}‘ awk.txt
现在想统计一月份的,角色是经理的打出m,角色是工人的打出w
[root@localhost ~]# awk ‘{split($3,date,"-");if(date[2]=="01"){name[$1]+=$5};if($2==0){role[$1]="M"}else{role[$1]="W"}} END{for(i in name){print i"\t"name[i]"\t"role[i]}}‘ awk.txt
Tom 2500 M
Vivi 2800 W
John 4500 W
‘{split($3,date,"-")}‘ 日期是第三列,所有$3,拆开split函数,保存到date变量中,切割符是-切割,所以切割成三列,date现在就是一个数组
类似于C的语法 ‘{split($3,date,"-");if(date[2]=="01"){name[$1]+=$5}}’ name[$1]+=$5 定义的数组变量,键是第一列Tom人的名字,值是薪水,第5列 ,+=是因为里面有一些重复数据,把重复数据加到一起了
END{for(i in name){print i"\t"name[i]"\t"role[i]}}‘ awk.txt 最后制作报表,循环打印,\t 制表符
? awk ‘{
? split($3,date,"-");
? if(date[2]=="01"){
? name[$1]+=$5
? }
? }
? END{
? for(i in name){
? print i "\t" name[i]}
? }‘ awk.txt
? awk ‘{split($3,date,"-
");if(date[2]=="01"){name[$1]+=$5;if($2=="0"){role[$1]="M"}else{role[$1]=
"W"}}} END{for(i in name){print i "\t" name[i]"\t" role[i]}}‘ awk.txt
20210211-1 Linux基础与应用(中)
原文:https://www.cnblogs.com/azxsdcv/p/14398245.html