我们先来看一下一个K-means的聚类效果图
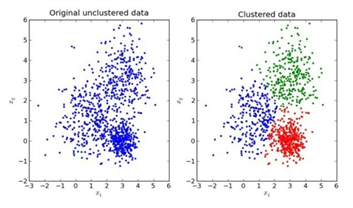
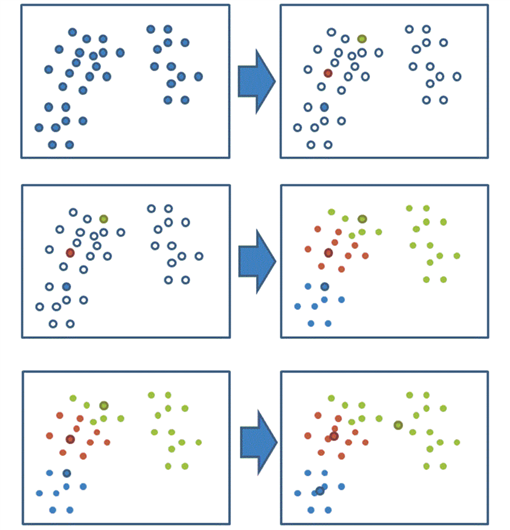
我们以一张图来解释效果
data_new
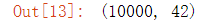
#预估器流程 from sklearn.cluster import KMeans estimator = KMeans(n_clusters=3) estimator.fit(data_new)

y_predict = estimator.predict(data_new) y_predict[:300]

#模型评估 - 轮廓系数 from sklearn.metrics import silhouette_score silhouette_score(data_new, y_predict)
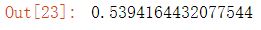
原文:https://www.cnblogs.com/a155-/p/14416743.html