Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
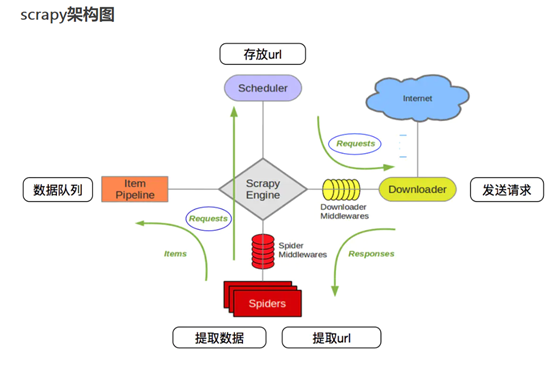
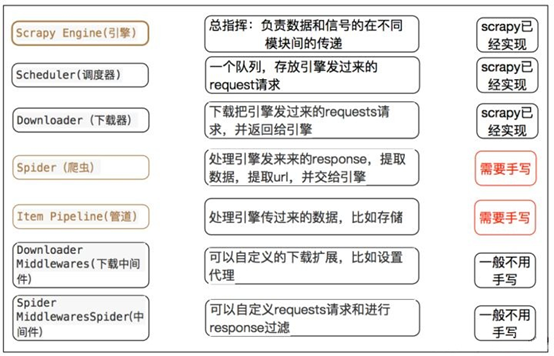
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列、入队、触发事件,当引擎需要时交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理。
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。(必须手动实现)
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。
Downloader Middlewares(下载中间件):是一个可以自定义扩展下载功能的组件,一般需根据实际情况存储到指定位置。
Spider Middlewares(Spider中间件):可以理解为是一个可以自定扩展、操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)。
项目说明
scrapy startproject scrapy_demo #在指定目录创建项目 scrapy_demo
文件说明:
scrapy.cfg:配置文件,不需要更改
scrapy_demo目录
init.py:特定文件,指明二级spider_demo目录为一个python模块
item.py:定义需要的item类【实现中需要用到】
middlewares.py:自定义中间件类,中间件可以在爬虫的请求发起之前或者请求返回之后对数据进行定制化修改,从而开发出适应不同情况的爬虫。
pipeline.py:管道文件,传入item.py中的item类,清理数据,保存或入库
settings.py:设置文件,例如设置用户代理和初始下载延迟
spiders目录
init.py:特定文件,指明二级spider_demo目录为一个python模块
spider_demo:这里是放自定义爬虫的py文件,负责从html中获得数据,传入上一层管道文件中进行数据清理和保存。
scrapy 安装:
pip install scrapy #安装scrapy包
scrapy bench #测试安装是否成功
scrapy startproject project_name #创建项目
scrapy genspider spider_name domains #创建爬虫基础类
scrapy crawl spider_name #启动爬虫程序
scrapy list #列出所有爬虫
scrapy settings [options] #获得配置信息
scrapy shell调试
scrapy shell #启动scrapy shell
fetch(‘url‘) #请求url
response #记录请求url响应内容
response #记录请求url响应源码
view(response) #在浏览器查看响应信息
Scrapy爬虫管理WebUI工具
管理程序:
Scrapyd:是一个运行 Scrapy 爬虫程序的服务。 #pip install scrapyd #安装 scrapyd # 启动服务
ScrapydAPI:是对API的python封装。 #pip install python-scrapyd-api # 安装
ScrapydArt:ScrapydArt在Scrapyd基础上新增了权限验证、筛选过滤、排序、数据统计以及排行榜等功能,并且有了更强大的API。 #pip install scrapydart #安装 scrapydart # 启动
管理调度:
SpiderKeeper:是一个scrapyd的可视化工具。 #pip install spiderkeeper #spiderkeeper # 启动
ScrapydWeb:是Scrapyd 集群管理、Scrapy 日志分析、支持所有 Scrapyd API、web UI 支持 Basic Auth功能。 #pip install scrapydweb #scrapydweb -h # 初始化 #scrapydweb # 启动
Gerapy:是分布式爬虫管理框架,控制爬虫运行、查看爬虫状态、查看爬取结果、项目部署、主机管理、编写爬虫代码。 #pip install gerapy # gerapy init # cd gerapy #gerapy migrate # gerapy runserver
SpiderAdmin:是对Scrapyd 接口进行可视化封装,对Scrapy爬虫项目进行删除 和 查看,对爬虫设置定时任务,支持apscheduler 的3中方式和随机延时,共计4中方式单次运行 date、周期运行 corn、间隔运行 interval、随机运行 random,基于Flask-BasicAuth 做了简单的权限校验。 # pip install spideradmin #spideradmin # 启动服务
示例模板: https://github.com/lovelifeming/AI-Studies-Road/tree/master/scrapy_demo
万水千山总是情, 领个红包行不行!

作者:Jason Zeng 于 2021-02-20
博客:http://www.cnblogs.com/zengming/ https://blog.csdn.net/Z645817
GItHub:https://github.com/lovelifeming
严正声明:
1.由于本博客部分资源来自互联网,版权均归原作者所有。转载的目的是用于学术交流与讨论学习,将不对任何资源负法律责任。
2.若无意中侵犯到您的版权利益,请来信联系我,我会在收到信息后会尽快给予处理!
3.所有资源内容仅供学习交流之用,请勿用作商业用途,谢谢。
4.如有转发请注明出处,来源于http://www.cnblogs.com/zengming/ https://blog.csdn.net/Z645817,谢谢合作。
原文:https://www.cnblogs.com/zengming/p/14356403.html