openpyxl是一个用来读写xlsx文件的Python库,官方文档https://openpyxl.readthedocs.io/en/stable/tutorial.html.
在使用openpyxl前先要掌握三个对象,即:Workbook(工作簿,一个包含多个Sheet的Excel文件)、Worksheet(工作表,一个Workbook有多个Worksheet,用表名识别,如“Sheet1”,“Sheet2”等)、Cell(单元格,存储具体的数据对象)三个对象。
pip install openpyxl
from openpyxl import Workbook wb = Workbook() #创建一个工作簿,默认也至少创建了一个工作表 ws = wb.active #获得正在运行的工作表,默认第0张;如果是已经存在的工作薄,获得的是打开Excel显示的工作表
from openpyxl import load_workbook
wb = load_workbook("文件名称.xlsx") #打开一个已存在的工作薄
wb.save("文件名称.xlsx") #保存工作簿,不写路径保存在当前文件夹
ws1 = wb.create_sheet() #创建一个工作表,默认位置是最后一个,默认名称是Sheet1(如果前面只有一张工作表);返回工作表
ws2 = wb.create_sheet("test",0) #创建一个工作表,表名是test,位置是第一个
ws3 = wb.create_sheet(title="test2",-1) #创建工作表,表名是test2,位置是倒数第二位
ws1 = wb["test"] #选择表名是test的工作表
ws2 = wb.get_sheet_by_name("test") #选择表名是test的工作表
title = ws.title #获取工作表的表名
ws.title = "newtitle" #修改工作表的表名是newtitle
wb.sheetnames #获取所有的工作表名称,返回一个列表
wb.get_sheet_names() #获取所有的工作表名称,返回一个列表
for sheet in wb: #打印所有工作表名称
print(sheet)
ws.sheet_properties.tabColor = "B22222" #设置工作表标签的背景颜色,使用RGB颜色16进制,RGB颜色参考https://tool.oschina.net/commons?type=3
del wb["Sheet2"] #删除title是Sheet的工作表 wb.remove(wb["Sheet2"]) #删除title是Sheet2的工作表
ws = wb.copy_worksheet("wb["Sheet"]) #复制Sheet工作表,默认名称是Sheet Copy
ws.title = "Sheet的副本" #把复制的工作表重命名为Sheet的副本
#获取单个单元格 cell = ws["A1"] #获取A1单元格,返回单元格<Cell ‘Sheet1‘.A1> a = ws["A1"].value #获取A1单元格的值 a = ws.cell(row=1,column=1).value #获取A1单元格的值,也可以直接写ws.cell(1,1)第一个参数是行数,第二个参数是列数

#按行或是列获取
cells = ws["B"] #获取第二列的单元格,返回一个元组;有数据或是格式都会被获取
for cell in cells:
print(cell.value) #打印第二列单元格的值
cells = ws[2] #获取第二行的单元格,返回一个元组
#打印奇数行第二列的单元格的数据
for i in range(1,20,2):
print(ws.cell(i,2).value)
#获取所有单元格 cells = list(ws.values) #ws.values获取所有的单元格数据,返回一个生成器,list生成一个列表;列表里面是元组,每行数据组成一个元组
#再对cells进行切片,可以按行获取单元格
cells1 = list(ws.values)[1:3] #获取第二行和第三行
#按行打印所有的单元格
for row in ws.rows: #ws.rows返回一个生成器,返回工作表的所有行,每一行单元格由一个元组包裹;ws.rows直接写成ws也是一样的效果
for cell in row:
print(cell.value)
#按列打印所有的单元格
for column in ws.columns: #ws.columns返回一个生成器,返回工作表的所有列,每列单元格由一个元组包裹
for cell in column:
print(cell.value)
#获取区域单元格
cells = ws["A1":"C5"] #获取A1到C5区域,返回列表,列表里面是元组,每行单元格组成一个元组
for row in cells:
for cell in row:
print(cell.value) #按行打印
#按行
cells = ws[5:10] #获取第5到10行单元格,返回列表,列表里面是元组,每行单元格组成一个元组
#按列
cells = ws["A:C"] #获取第A列到第C列,返回列表,列表里面是元组,每列单元格组成一个元组
#按行
cells = ws.iter_rows(min_row=2,min_col=2,max_row=4,max_col=4) #按行获取单元格,返回列表,列表里面是元组,每行单元格组成一个元组
#按列
cells = ws.iter_cols(min_row=2,min_col=2,max_row=4,max_col=4) #按列获取单元格,返回列表,列表里面是元组,每列单元格组成一个元组
#Excel的列用字母表示,有时需要转换字母和数字
#数字转字母
a = openpyxl.utils.get_column_letter(23)
print(a)
#字母转数字
b = openpyxl.utils.column_index_from_string("h")
print(b)
#获取工作表的做大行最大列 max_row = ws.max_row #获取工作表的最大行,返回数字 max_column = ws.max_column #获取工作表的最大列,返回数字
#用最大行和最大列来按行获取工作表数据
for row in range(1,max_row+1):
for col in range(1,max_col+1):
print(ws.cell(row,col).value)
#写入单元格 ws["A1"] = 1 #在A1位置写入1 ws["A2"].value = 2 #在A2位置写入2 ws.cell(3,1,value=3) #在第3行第1列(A3)写入3 ws.append([1,2,3,4]) #在最后一行的下一行写入,即在A4写入1,B4写入2...
#插入行 ws.insert_rows(idx=2,amount=3) #在第2行前插入3行,也可以省略idx和amount #插入列 ws.insert_columns(2,3) #在第2列前插入3列 #删除行 ws.delete_rows(2,3) #删除第2行开始的3行 #删除列 ws.delete_columns(2,3) #删除第2列开始的3列
#移动单元格,rows是正数,向下移动,负数向上移动;cols是正数向右移动,负数向左移动
ws.move_ range("A1:B3",rows=10,cols=10) #把"A1:B3"单元格向下移10行,向右移10行;移动之前的位置变为空,移动之后的位置如果之前有数据,覆盖原数据
#冻结单元格,如果要冻结首行就写"A2",如果要冻结上面2行和左边2列,就写"C3" ws.freeze_panes = "A2" #冻结首行
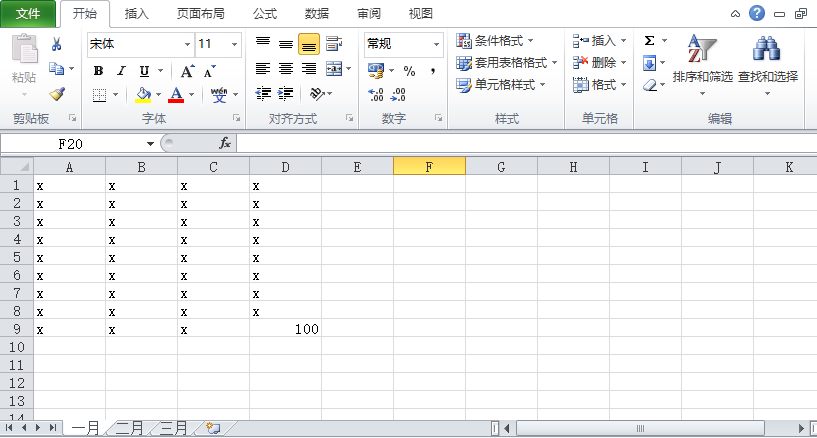
#求一月、二月、三月的D9单元格的和
from openpyxl import load_workbook
wb = load_workbook("实例1.xlsx")
list = []
for sheet in wb.worksheets:
list.append(sheet["D9"].value)
print(list)
sum1 = sum(list)
print(sum1)
#列表推导式
sum2 = sum([sheet["D9"].value for sheet in wb.worksheets])
print(sum2)
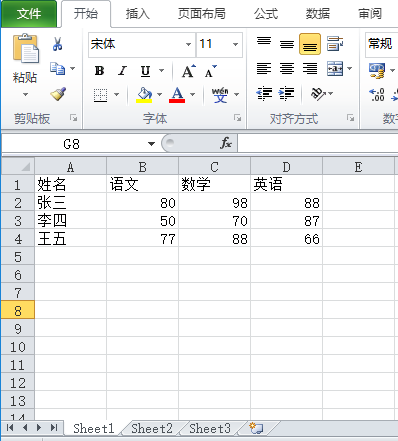
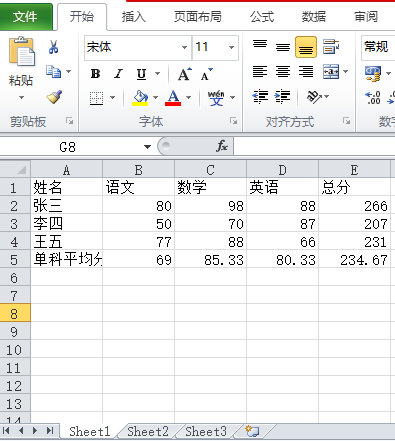
#按行或是按列聚合,加入总分和平均分
from openpyxl import load_workbook
wb = load_workbook("实例2.xlsx")
ws = wb.active
max_row = ws.max_row #获取最大行号
max_col = ws.max_column #获取最大列号
#在列后加入总分
ws.cell(1,column = max_col+1,value="总分") #在最大列后面写入“总分”
for row in ws.iter_rows(min_row=2,min_col=2,max_col=max_col): #选取分数的范围
list = []
row_index = row[0].row #获得行号,返回数字
for col in row:
list.append(col.value)
ws.cell(row_index,max_col+1,value=sum(list)) #在每一行的最后写入总分
#在行后加入单科平均分
ws.cell(max_row+1,1,value="单科平均分")
for col in ws.iter_cols(min_row=2,min_col=2,max_row=max_row):
col_index = col[0].column #获取列号,返回数字
list = [cell.value for cell in col] #列表推导式获取范围内每列的数字
ws.cell(max_row+1,col_index,value=round(sum(list)/len(list),2)) #写入平均分,且保存2位小数;round(a,2)a保存2位小数
wb.save("实例2.xlsx")
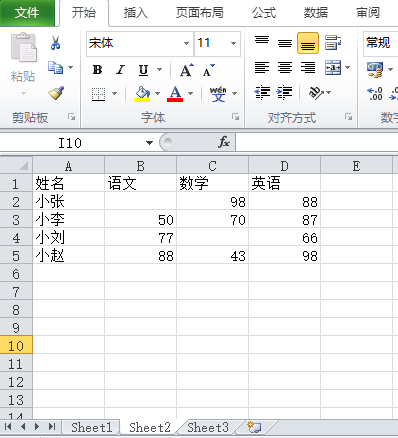
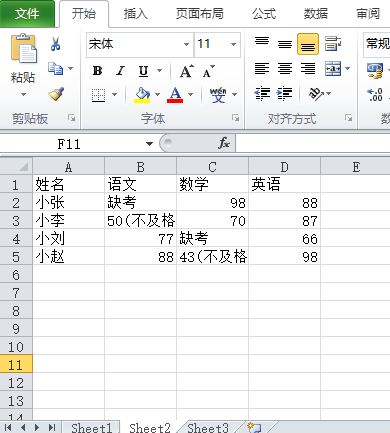
#筛选
from openpyxl import load_workbook
wb = load_workbook("实例2.xlsx")
ws = wb["Sheet2"]
for row in ws.iter_rows(min_row=2,min_col=2):
for cell in row:
print(cell.value)
if cell.value == None: #如果单元格的值是空,写入“缺考”
cell.value = "缺考"
elif cell.value < 60: #如果单元格的值小于60,加上“(不及格)”
cell.value = str(cell.value) + "(不及格)"
wb.save("实例2.xlsx")
#删除低于总分低于250的行
from openpyxl import load_workbook
wb = load_workbook("实例2.xlsx")
ws = wb["Sheet3"]
for row in range(ws.max_row,1,-1): #row表示行号,因为Excel删除一行之后,下面的数据会上移,行号会变,所以要从下往上删除
s = sum([cell.value for cell in ws[row][1:]]) #除去第一列,计算一行数据的和为总分
if s < 250:
ws.delete_rows(row)
wb.save("实例2.xlsx")
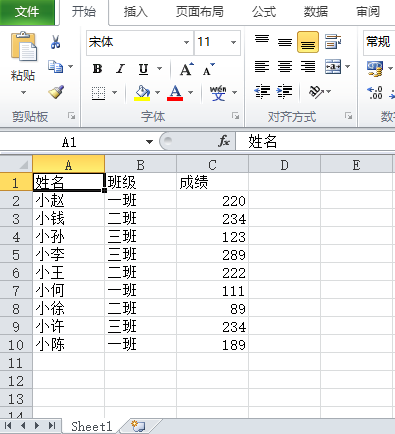
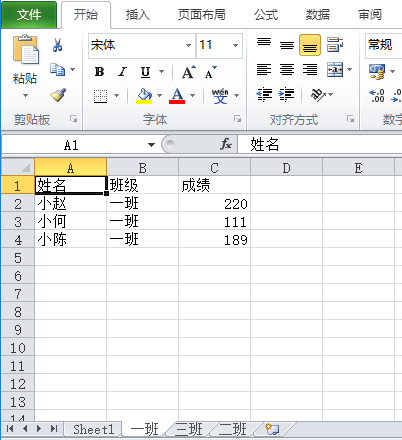
#将表格按班级拆分
from openpyxl import load_workbook
wb = load_workbook("实例3.xlsx") #打开工作薄
ws = wb.active #获取工作表
dict = {} #字典记录工作表数据
for row in ws.iter_rows(min_row=2): #获取第二行开始的所有行数据
row_data = [cell.value for cell in row] #列表推导式获得每行的数据
if row_data[1] in dict.keys(): #如果班级在字典的键里;row_data表示班级,以班级为键;
dict[row_data[1]] += [row_data] #把行数据添加到键的值里面;需要把列表再用一层列表包裹,包裹之后会把列表整个添加;不然+会把列表里的值一个个添加
else:
dict[row_data[1]] = [[cell.value for cell in ws[1]]] #如果班级不在键里,先加上表格第一行的表头
dict[row_data[1]] += [row_data] #再添加行数据
for key,value in sorted(dict.items()): #把字典进行排序
ws = wb.create_sheet(key) #创建工作表,表名是键名
for data in value: #添加数据
ws.append(data)
wb.save("实例3.xlsx")
ws.merge_cells("A1:C5") #合并A1到C5的单元格,如果都有数据,保留A1的数据
ws.merge_cells(start_row=1,end_row=5,start_column=1,end_column=3) #合并A1到C5的单元格
ws.unmerge_cells("A1:C5") #取消合并单元格
打开工作薄用data_only=False(默认),写入公式之后,保存文件;再用data_only=False打开,打印单元格的value是公式;用data_only=True打开,打印value是None。
要获取单元格的value是数字,要手动打开Excel之后保存,再用data_only=True打开,打印单元格的value是数字,不能保存;用data_only=True打开之后保存,就只有数字没有公式了。
from openpyxl import load_workbook
wb = load_workbook("实例2.xlsx")
ws = wb["Sheet4"]
ws["D6"] = "=sum(D2:D5)" #使用excel公式
print(ws["D6"].value) #打印出来的值是公式=sum(D4+D5)
wb.save("实例2.xlsx")
#如果要读取出数据,需要手动打开Excel表保存,openpyxl打开Excel时使用data_only=True,不保存
wb = load_workbook("实例2.xlsx")
print(wb["D6"]) #打印数字
ws.column_dimensions.group("A","C") #按列分组,A到C列为一组
ws.row_dimensions.group(1,3,hidden=True) #按行分组,1到3行为一组,hidden=True表示隐藏分组的行
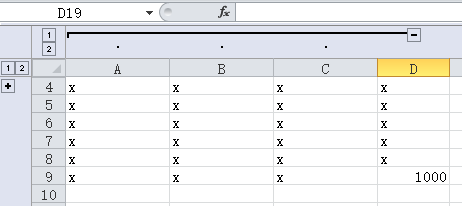
#批注
c = openpyxl.comments.Comment("这是一个注释","张三") #Comment(text, author, height=79, width=144)
ws["K1"].comment = c #给单元格设置批注
Font(name=None, sz=None, b=None, i=None, charset=None, u=None, strike=None, color=None, scheme=None, family=None, size=None, bold=None, italic=None, strikethrough=None, underline=None, vertAlign=None, outline=None, shadow=None, condense=None, extend=None)
#设置字体 f = openpyxl.styles.Font(name=u"微软雅黑",sz=16,bold=True,vertAlign="baseline",color="DC143C") ws["A1"].font = f #只能设置单个单个单元格,如果需要设置区域,要循环设置 #获取字体 f1 = ws["A1‘].font
Alignment(horizontal=None, vertical=None, textRotation=0, wrapText=None, shrinkToFit=None, indent=0, relativeIndent=0, justifyLastLine=None, readingOrder=0, text_rotation=None, wrap_text=None, shrink_to_fit=None, mergeCell=None)
#设置对齐 a = openpyxl.styles.Alignment(horizontal = "center",vertical = "center") ws["c1"].alignment = a
Side(style=None, color=None, border_style=None)
Border(left=None, right=None, top=None, bottom=None, diagonal=None, diagonal_direction=None, vertical=None, horizontal=None, diagonalUp=False, diagonalDown=False, outline=True, start=None, end=None)
#边框 s = openpyxl.styles.Side(style = "medium",color = "FF69B4") #设置边线样式 b = openpyxl.styles.Border(left = s, right = s, top = s, bottom = s) #设置边框 ws["c2"].border = b
PatternFill(patternType=None, fgColor=Color(), bgColor=Color(), fill_type=None, start_color=None, end_color=None)
#填充 f = openpyxl.styles.PatternFill(fill_type = "mediumGray", end_color ="FF69B4") f1 = openpyxl.styles.PatternFill(fill_type = "mediumGray",start_color = "FF69B4") ws["C3"].fill = f ws["C4"].fill = f1

Excel的默认行高是13.5,默认列宽是8.38;即使行高和列宽被设为0,行高最小也是13.5,列宽最小是8.38
#行高,行高的单位是磅,1个单位=0.3612毫米 ws.row_dimensions[3].height = 50 #设置工作表的第三行的高度是50个单位 #列宽,列宽的单位是0.1英寸,一个单位=2.2862毫米 ws.column_dimensions["C"].width = 50 #设置工作表的C列是50个单位
#插入图片;必须安装Pillow库,不然会报错"You must install Pillow to fetch image objects"
img = openpyxl.drawing.image.Image("E:\\图\\1\\1.jpg") #创建图片对象
img.height = 100 #设置图片的高,单位是px
img.width = 100 #设置图片的宽,单位是px
ws.add_image(img,"A10") #在A10位置插入图片
11.1 柱状图
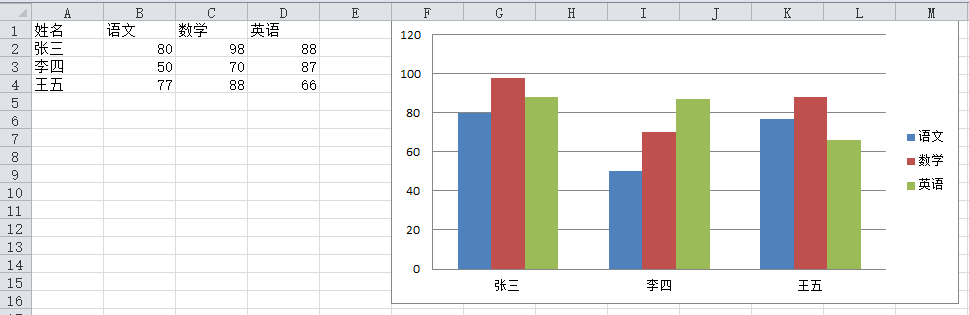
#制作柱状图
from openpyxl import load_workbook
from openpyxl import chart
wb = load_workbook("实例3.xlsx")
ws = wb["Sheet1"]
#创建一个柱状表对象
c = chart.BarChart()
#设定数据范围
data = chart.Reference(ws,min_row = 1, max_row = 4, min_col = 2, max_col = 4)
#设置x轴的项目
x = chart.Reference(ws, min_row = 2, max_row = 4, min_col = 1)
#柱状图添加数据
c.add_data(data,titles_from_data=True)
#柱状图添加X轴
c.set_categories(x)
#在工作表中添加柱状图
ws.add_chart(c,"F1")
wb.save("实例3.xlsx")
11.2 折线图
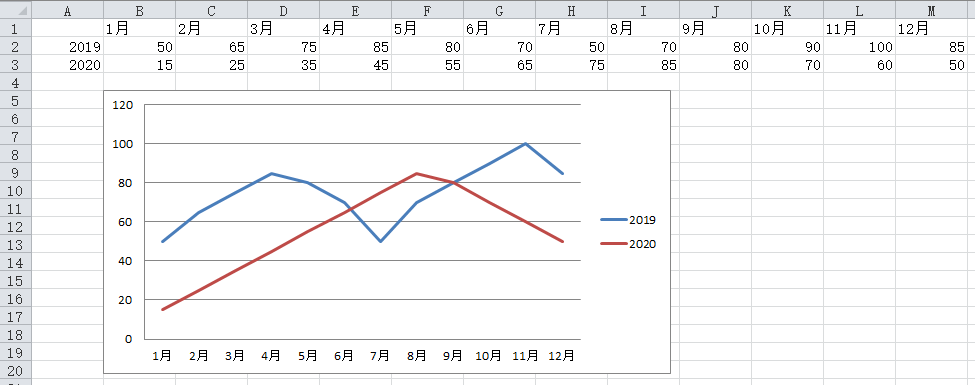
# 制作折线图
from openpyxl import load_workbook
from openpyxl import chart
wb = load_workbook("实例4.xlsx")
ws = wb.active
#创建一个折线图对象
c = chart.LineChart()
#设定数据范围
data = chart.Reference(ws, min_row=2, max_row=3, min_col=1, max_col=13)
#设置x轴项目
x = chart.Reference(ws, min_row=1, min_col=2, max_col=13)
c.add_data(data, from_rows=True, titles_from_data=True) #因为title在行首,from_rows=True
c.set_categories(x)
#在工作表的B5位置添加折线图
ws.add_chart(c,"B5")
wb.save("实例4.xlsx")
11.3 饼状图
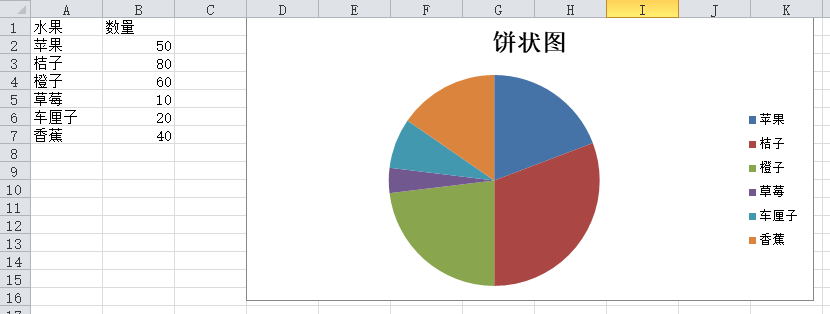
#饼图
from openpyxl import load_workbook
from openpyxl import chart
wb = load_workbook("实例4.xlsx")
ws = wb["Sheet2"]
pie = chart.PieChart()
data = chart.Reference(ws, min_row=2, max_row=7, min_col=2)
x = chart.Reference(ws, min_row=2, max_row=7, min_col=1)
pie.add_data(data)
pie.set_categories(x)
pie.title = "饼状图" #设置饼状图的标题
ws.add_chart(pie,"D1")
wb.save("实例4.xlsx")
pip install openpyxl
想要在文件中插入图片文件,需要安装pillow,安装文件:PIL-fork-1.1.7.win-amd64-py2.7.exe
· font(字体类):字号、字体颜色、下划线等
· fill(填充类):颜色等
· border(边框类):设置单元格边框
· alignment(位置类):对齐方式
· number_format(格式类):数据格式
· protection(保护类):写保护
# -*- coding: utf-8 -*-
from openpyxl import Workbook
wb = Workbook() #创建文件对象
# grab the active worksheet
ws = wb.active #获取第一个sheet
# Data can be assigned directly to cells
ws[‘A1‘] = 42 #写入数字
ws[‘B1‘] = "你好"+"automation test" #写入中文(unicode中文也可)
# Rows can also be appended
ws.append([1, 2, 3]) #写入多个单元格
# Python types will automatically be converted
import datetime
import time
ws[‘A2‘] = datetime.datetime.now() #写入一个当前时间
#写入一个自定义的时间格式
ws[‘A3‘] =time.strftime("%Y年%m月%d日 %H时%M分%S秒",time.localtime())
# Save the file
wb.save("e:\\sample.xlsx")
# -*- coding: utf-8 -*-
from openpyxl import Workbook
wb = Workbook()
ws1 = wb.create_sheet("Mysheet") #创建一个sheet
ws1.title = "New Title" #设定一个sheet的名字
ws2 = wb.create_sheet("Mysheet", 0) #设定sheet的插入位置 默认插在后面
ws2.title = u"你好" #设定一个sheet的名字 必须是Unicode
ws1.sheet_properties.tabColor = "1072BA" #设定sheet的标签的背景颜色
#获取某个sheet对象
print wb.get_sheet_by_name(u"你好" )
print wb["New Title" ]
#获取全部sheet 的名字,遍历sheet名字
print wb.sheetnames
for sheet_name in wb.sheetnames:
print sheet_name
print "*"*50
for sheet in wb:
print sheet.title
#复制一个sheet
wb["New Title" ]["A1"]="zeke"
source = wb["New Title" ]
target = wb.copy_worksheet(source)
# w3 = wb.copy_worksheet(wb[‘new title‘])
# ws3.title = ‘new2‘
# wb.copy_worksheet(wb[‘new title‘]).title = ‘hello‘
# Save the file
wb.save("e:\\sample.xlsx")
# -*- coding: utf-8 -*-
from openpyxl import Workbook
wb = Workbook()
ws1 = wb.create_sheet("Mysheet") #创建一个sheet
ws1["A1"]=123.11
ws1["B2"]="你好"
d = ws1.cell(row=4, column=2, value=10)
print ws1["A1"].value
print ws1["B2"].value
print d.value
# Save the file
wb.save("e:\\sample.xlsx")
无论ws.rows还是ws.iter_rows都是一个对象
除上述两个对象外 单行,单列都是一个元祖,多行多列是二维元祖
# -*- coding: utf-8 -*-
from openpyxl import Workbook
wb = Workbook()
ws1 = wb.create_sheet("Mysheet") #创建一个sheet
ws1["A1"]=1
ws1["A2"]=2
ws1["A3"]=3
ws1["B1"]=4
ws1["B2"]=5
ws1["B3"]=6
ws1["C1"]=7
ws1["C2"]=8
ws1["C3"]=9
#操作单列
print ws1["A"]
for cell in ws1["A"]:
print cell.value
#操作多列,获取每一个值
print ws1["A:C"]
for column in ws1["A:C"]:
for cell in column:
print cell.value
#操作多行
row_range = ws1[1:3]
print row_range
for row in row_range:
for cell in row:
print cell.value
print "*"*50
for row in ws1.iter_rows(min_row=1, min_col=1, max_col=3, max_row=3):
for cell in row:
print cell.value
#获取所有行
print ws1.rows
for row in ws1.rows:
print row
print "*"*50
#获取所有列
print ws1.columns
for col in ws1.columns:
print col
wb.save("e:\\sample.xlsx")
使用百分数
# -*- coding: utf-8 -*-
from openpyxl import Workbook
from openpyxl import load_workbook
wb = load_workbook(‘e:\\sample.xlsx‘)
wb.guess_types = True
ws=wb.active
ws["D1"]="12%"
print ws["D1"].value
# Save the file
wb.save("e:\\sample.xlsx")
#结果会打印小数
# -*- coding: utf-8 -*-
from openpyxl import Workbook
from openpyxl import load_workbook
wb = load_workbook(‘e:\\sample.xlsx‘)
wb.guess_types = False
ws=wb.active
ws["D1"]="12%"
print ws["D1"].value
wb.save("e:\\sample.xlsx")
#结果会打印百分数
#coding=utf-8
from openpyxl import Workbook
from openpyxl import load_workbook
wb = load_workbook(‘e:\\sample.xlsx‘)
ws=wb.active
rows=[]
for row in ws.iter_rows():
rows.append(row)
print rows #所有行
print rows[0] #获取第一行
print rows[0][0] #获取第一行第一列的单元格对象
print rows[0][0].value #获取第一行第一列的单元格对象的值
print rows[len(rows)-1] #获取最后行 print rows[-1]
print rows[len(rows)-1][len(rows[0])-1] #获取第后一行和最后一列的单元格对象
print rows[len(rows)-1][len(rows[0])-1].value #获取第后一行和最后一列的单元格对象的值
#coding=utf-8
from openpyxl import Workbook
from openpyxl import load_workbook
wb = load_workbook(‘e:\\sample.xlsx‘)
ws=wb.active
cols=[]
cols = []
for col in ws.iter_cols():
cols.append(col)
print cols #所有列
print cols[0] #获取第一列
print cols[0][0] #获取第一列的第一行的单元格对象
print cols[0][0].value #获取第一列的第一行的值
print "*"*30
print cols[len(cols)-1] #获取最后一列
print cols[len(cols)-1][len(cols[0])-1] #获取最后一列的最后一行的单元格对象
print cols[len(cols)-1][len(cols[0])-1].value #获取最后一列的最后一行的单元格对象的值
# -*- coding: utf-8 -*-
from openpyxl import Workbook
from openpyxl import load_workbook
wb = load_workbook(‘e:\\sample.xlsx‘)
wb.guess_types = True #猜测格式类型
ws=wb.active
ws["D1"]="12%"
print ws["D1"].value
# Save the file
wb.save("e:\\sample.xlsx")
#注意如果原文件有一些图片或者图标,则保存的时候可能会导致图片丢失
# -*- coding: utf-8 -*-
from openpyxl import Workbook
from openpyxl import load_workbook
import datetime
wb = load_workbook(‘e:\\sample.xlsx‘)
ws=wb.active
wb.guess_types = True
ws["A1"]=datetime.datetime(2010, 7, 21)
print ws["A1"].number_format
ws["A2"]="12%"
print ws["A2"].number_format
ws["A3"]= 1.1
print ws["A4"].number_format
ws["A4"]= "中国"
print ws["A5"].number_format
# Save the file
wb.save("e:\\sample.xlsx")
执行结果:
yyyy-mm-dd h:mm:ss
0%
General
General
#如果是常规,显示general,如果是数字,显示‘0.00_ ‘,如果是百分数显示0%
数字需要在Excel中设置数字类型,直接写入的数字是常规类型
# -*- coding: utf-8 -*-
from openpyxl import Workbook
from openpyxl import load_workbook
wb = load_workbook(‘e:\\sample.xlsx‘)
ws1=wb.active
ws1["A1"]=1
ws1["A2"]=2
ws1["A3"]=3
ws1["A4"] = "=SUM(1, 1)"
ws1["A5"] = "=SUM(A1:A3)"
print ws1["A4"].value #打印的是公式内容,不是公式计算后的值,程序无法取到计算后的值
print ws1["A5"].value #打印的是公式内容,不是公式计算后的值,程序无法取到计算后的值
# Save the file
wb.save("e:\\sample.xlsx")
# -*- coding: utf-8 -*-
from openpyxl import Workbook
from openpyxl import load_workbook
wb = load_workbook(‘e:\\sample.xlsx‘)
ws1=wb.active
ws.merge_cells(‘A2:D2‘)
ws.unmerge_cells(‘A2:D2‘) #合并后的单元格,脚本单独执行拆分操作会报错,需要重新执行合并操作再拆分
# or equivalently
ws.merge_cells(start_row=2,start_column=1,end_row=2,end_column=4)
ws.unmerge_cells(start_row=2,start_column=1,end_row=2,end_column=4)
# Save the file
wb.save("e:\\sample.xlsx")
需要先安装Pilow,安全文件是:PIL-fork-1.1.7.win-amd64-py2.7.exe
# -*- coding: utf-8 -*-
from openpyxl import load_workbook
from openpyxl.drawing.image import Image
wb = load_workbook(‘e:\\sample.xlsx‘)
ws1=wb.active
img = Image(‘e:\\1.png‘)
ws1.add_image(img, ‘A1‘)
# Save the file
wb.save("e:\\sample.xlsx")
# -*- coding: utf-8 -*-
from openpyxl import load_workbook
from openpyxl.drawing.image import Image
wb = load_workbook(‘e:\\sample.xlsx‘)
ws1=wb.active
ws1.column_dimensions.group(‘A‘, ‘D‘, hidden=True) #隐藏a到d列范围内的列
#ws1.row_dimensions 无group方法
# Save the file
wb.save("e:\\sample.xlsx")
# -*- coding: utf-8 -*-
from openpyxl import load_workbook
from openpyxl import Workbook
from openpyxl.chart import BarChart, Reference, Series
wb = load_workbook(‘e:\\sample.xlsx‘)
ws1=wb.active
wb = Workbook()
ws = wb.active
for i in range(10):
ws.append([i])
values = Reference(ws, min_col=1, min_row=1, max_col=1, max_row=10)
chart = BarChart()
chart.add_data(values)
ws.add_chart(chart, "E15")
# Save the file
wb.save("e:\\sample.xlsx")
# -*- coding: utf-8 -*-
from openpyxl import load_workbook
from openpyxl import Workbook
from openpyxl.chart import (PieChart , ProjectedPieChart, Reference)
from openpyxl.chart.series import DataPoint
data = [
[‘Pie‘, ‘Sold‘],
[‘Apple‘, 50],
[‘Cherry‘, 30],
[‘Pumpkin‘, 10],
[‘Chocolate‘, 40],
]
wb = Workbook()
ws = wb.active
for row in data:
ws.append(row)
pie = PieChart()
labels = Reference(ws, min_col=1, min_row=2, max_row=5)
data = Reference(ws, min_col=2, min_row=1, max_row=5)
pie.add_data(data, titles_from_data=True)
pie.set_categories(labels)
pie.title = "Pies sold by category"
# Cut the first slice out of the pie
slice = DataPoint(idx=0, explosion=20)
pie.series[0].data_points = [slice]
ws.add_chart(pie, "D1")
ws = wb.create_sheet(title="Projection")
data = [
[‘Page‘, ‘Views‘],
[‘Search‘, 95],
[‘Products‘, 4],
[‘Offers‘, 0.5],
[‘Sales‘, 0.5],
]
for row in data:
ws.append(row)
projected_pie = ProjectedPieChart()
projected_pie.type = "pie"
projected_pie.splitType = "val" # split by value
labels = Reference(ws, min_col=1, min_row=2, max_row=5)
data = Reference(ws, min_col=2, min_row=1, max_row=5)
projected_pie.add_data(data, titles_from_data=True)
projected_pie.set_categories(labels)
ws.add_chart(projected_pie, "A10")
from copy import deepcopy
projected_bar = deepcopy(projected_pie)
projected_bar.type = "bar"
projected_bar.splitType = ‘pos‘ # split by position
ws.add_chart(projected_bar, "A27")
# Save the file
wb.save("e:\\sample.xlsx")
# -*- coding: utf-8 -*-
from openpyxl import load_workbook
from openpyxl import Workbook
from openpyxl.worksheet.table import Table, TableStyleInfo
wb = Workbook()
ws = wb.active
data = [
[‘Apples‘, 10000, 5000, 8000, 6000],
[‘Pears‘, 2000, 3000, 4000, 5000],
[‘Bananas‘, 6000, 6000, 6500, 6000],
[‘Oranges‘, 500, 300, 200, 700],
]
# add column headings. NB. these must be strings
ws.append(["Fruit", "2011", "2012", "2013", "2014"])
for row in data:
ws.append(row)
tab = Table(displayName="Table1", ref="A1:E5")
# Add a default style with striped rows and banded columns
style = TableStyleInfo(name="TableStyleMedium9", showFirstColumn=True,
showLastColumn=True, showRowStripes=True, showColumnStripes=True)
#第一列是否和样式第一行颜色一行,第二列是否···
#是否隔行换色,是否隔列换色
tab.tableStyleInfo = style
ws.add_table(tab)
# Save the file
wb.save("e:\\sample.xlsx")
# -*- coding: utf-8 -*-
from openpyxl import Workbook
from openpyxl.styles import colors
from openpyxl.styles import Font
wb = Workbook()
ws = wb.active
a1 = ws[‘A1‘]
d4 = ws[‘D4‘]
ft = Font(color=colors.RED) # color="FFBB00",颜色编码也可以设定颜色
a1.font = ft
d4.font = ft
# If you want to change the color of a Font, you need to reassign it::
#italic 倾斜字体
a1.font = Font(color=colors.RED, italic=True) # the change only affects A1
a1.value = "abc"
# Save the file
wb.save("e:\\sample.xlsx")
# -*- coding: utf-8 -*-
from openpyxl import Workbook
from openpyxl.styles import colors
from openpyxl.styles import Font
wb = Workbook()
ws = wb.active
a1 = ws[‘A1‘]
d4 = ws[‘D4‘]
a1.value = "abc"
from openpyxl.styles import Font
from copy import copy
ft1 = Font(name=u‘宋体‘, size=14)
ft2 = copy(ft1) #复制字体对象
ft2.name = "Tahoma"
print ft1.name
print ft2.name
print ft2.size # copied from the
a1.font = ft1
# Save the file
wb.save("e:\\sample.xlsx")
# -*- coding: utf-8 -*-
from openpyxl import Workbook
from openpyxl.styles import Font
wb = Workbook()
ws = wb.active
col = ws.column_dimensions[‘A‘]
col.font = Font(bold=True) #将A列设定为粗体
row = ws.row_dimensions[1]
row.font = Font(underline="single") #将第一行设定为下划线格式
# Save the file
wb.save("e:\\sample.xlsx")
# -*- coding: utf-8 -*-
from openpyxl import Workbook
from openpyxl.styles import Font
from openpyxl.styles import NamedStyle, Font, Border, Side,PatternFill
wb = Workbook()
ws = wb.active
highlight = NamedStyle(name="highlight")
highlight.font = Font(bold=True, size=20,color= "ff0100")
highlight.fill = PatternFill("solid", fgColor="DDDDDD")#背景填充
bd = Side(style=‘thick‘, color="000000")
highlight.border = Border(left=bd, top=bd, right=bd, bottom=bd)
print dir(ws["A1"])
ws["A1"].style =highlight
# Save the file
wb.save("e:\\sample.xlsx")
# -*- coding: utf-8 -*-
from openpyxl import Workbook
from openpyxl.styles import Font
from openpyxl.styles import NamedStyle, Font, Border, Side,PatternFill
from openpyxl.styles import PatternFill, Border, Side, Alignment, Protection, Font
wb = Workbook()
ws = wb.active
ft = Font(name=u‘微软雅黑‘,
size=11,
bold=False,
italic=False,
vertAlign=None,
underline=‘none‘,
strike=False,
color=‘FF000000‘)
fill = PatternFill(fill_type="solid",
start_color=‘FFEEFFFF‘,
end_color=‘FF001100‘)
#边框可以选择的值为:‘hair‘, ‘medium‘, ‘dashDot‘, ‘dotted‘, ‘mediumDashDot‘, ‘dashed‘, ‘mediumDashed‘, ‘mediumDashDotDot‘, ‘dashDotDot‘, ‘slantDashDot‘, ‘double‘, ‘thick‘, ‘thin‘]
#diagonal 表示对角线
bd = Border(left=Side(border_style="thin",
color=‘FF001000‘),
right=Side(border_style="thin",
color=‘FF110000‘),
top=Side(border_style="thin",
color=‘FF110000‘),
bottom=Side(border_style="thin",
color=‘FF110000‘),
diagonal=Side(border_style=None,
color=‘FF000000‘),
diagonal_direction=0,
outline=Side(border_style=None,
color=‘FF000000‘),
vertical=Side(border_style=None,
color=‘FF000000‘),
horizontal=Side(border_style=None,
color=‘FF110000‘)
)
alignment=Alignment(horizontal=‘general‘,
vertical=‘bottom‘,
text_rotation=0,
wrap_text=False,
shrink_to_fit=False,
indent=0)
number_format = ‘General‘
protection = Protection(locked=True,
hidden=False)
ws["B5"].font = ft
ws["B5"].fill =fill
ws["B5"].border = bd
ws["B5"].alignment = alignment
ws["B5"].number_format = number_format
ws["B5"].value ="zeke"
# Save the file
wb.save("e:\\sample.xlsx")
原文:https://www.cnblogs.com/ttrrpp/p/14426876.html