作为编辑文件的主流编辑器,vim 一直在linux系统中被奉为神器,诚然,vim 编辑器的强大功能和复杂的命令系统,使得它的入门已颇具门槛,但熟练之后确实是高效工作的一大助手;另外,sed 以及本文即将探讨的 awk 也是文本处理的有效工具;随着越来越多的桌面linux操作系统的涌现,图形化的文本编辑器如 nano,gedit 也成为编辑器家族的重要成员。
awk是基于列的文本处理工具,它的工作方式是按行读取文本并视为一条记录,每条记录以字段为单位分割成若干字段,然后输出各字段的值。
awk认为文件都是由单词和各种空白字符组成的,这里“空白字符”包括空格、Tab,以及连续的空格和Tab等,每个非空白的部分叫做“域”(即字段)。
下文以一个实验文本展示awk的简单使用:
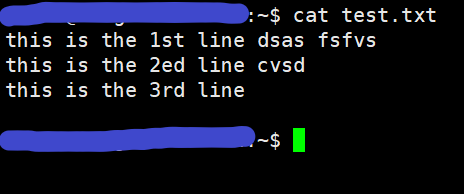

上图中,$1,$4,$6分别是每一行内容的第1,4,6字段。
显然,上述awk默认是以空格作为分界标记,其实可以使用自定义的符号作为分界符。
下图中,在test1.txt文本中,指定使用下划线"_"作为分界符:
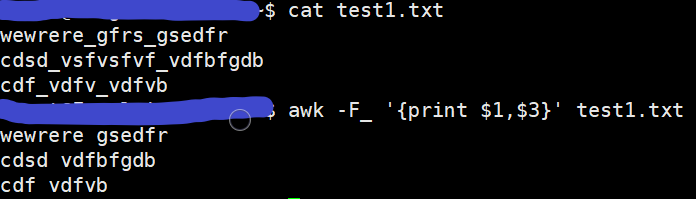
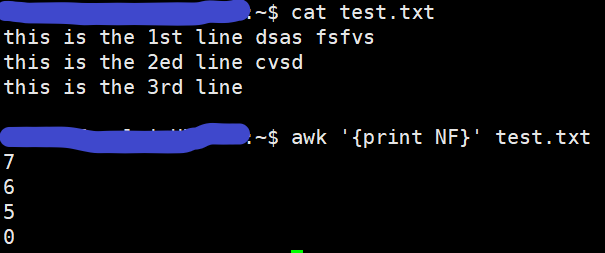
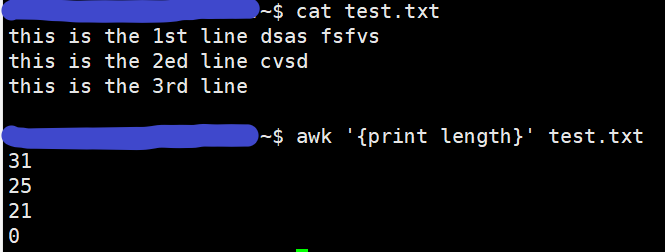
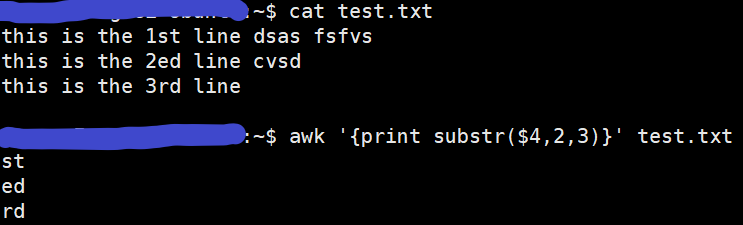
下图中,选定第4个字段,截取该字段中第2至第3个(首位均包含)字符串:
原文:https://www.cnblogs.com/pythonfl/p/14428832.html