推荐模型演化:
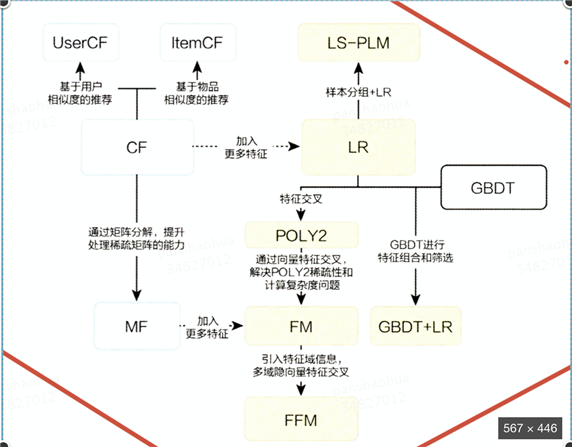
协同过滤:
UserCF:基于用户相似度
ItemCF:基于物品相似度
相似度计算:Cosine Similarity、皮尔逊相关系数(引入用户平均分,减少了用户评分偏置影响)、还可以引入物品平均分,减少物品评分偏置对结果的影响
UserCF具备强的社交特性,ItemCF适用于兴趣变化比较稳定的应用
矩阵分解:
用户和物品的隐向量是通过分解协同过滤生成的共现矩阵得到的
分解方法:
特征值分解:只能用于方阵
SVD: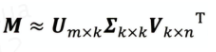
gradient decent
用regularization防止过拟合:模型权重的q次方,q=1为L1 regularization,q=2为L2 regularization
logistic regression:
LR将推荐问题转换成为点击率(CTR)的问题
linear regression + sigmoid
POLY2:
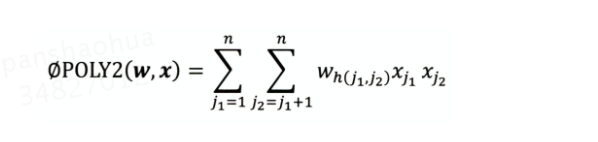
特征两两交叉
FM:
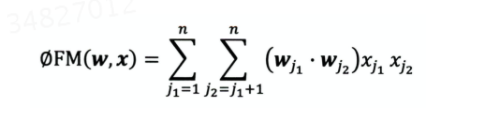
1.引入了隐向量,可以把权重参数n^2 -> nk
2.解决数据稀疏的问题,泛化能力提高
FFM:
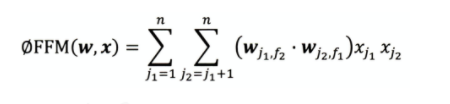
引入了特征域
GBDT + LR:
利用GBDT自动进行特征筛选和组合,生成新的离散特征向量,把特征向量当作LR的输入
LS-PLM:
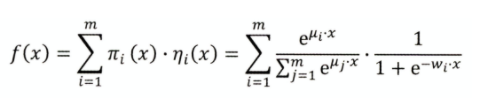
端到端非线性学习能力
用了L1 regularization,更容易求得稀疏解
原文:https://www.cnblogs.com/isshpan/p/14438244.html