自编码器的学习目标:最小化重构错误(reconstruction errors)
https://blog.csdn.net/qq_27825451/article/details/84968890
以一个手写数字的图片编码-解码为例。
当我们对解码器输入一个训练集中从未出现的编码的时候,我们得到的重构的输出可能是一个完全的乱码或者是噪声,也就是说与手写数字数据毫无关系,很显然,这并不是我们所希望的。我们希望的是“生成模型”能够对任意的输入编码产生有相关意义的数据,这就是我们后面的“变分自编码器VAE”所要做的事情。
所以,自编码器其实并不是一个真正意义上“生成模型”
f.自编码器的两个重要特征
(1)压缩编码的数据维度一定要比元时输入数据更少。也就是所谓的要具有一定的“瓶颈限制”,如果压缩编码的数据维度更多,那就到不到数据降维的目的了,那编码还有什么意义呢?
(2)不管是编码器,还是解码器,本质上都是神经网络层,神经网络层一定要具有一定的“容量”。什么是容量,就是一定要不止一个神经网络层才行,为什么?因为我们知道神经网络层数意味着对数据的隐含特征进行提取(虽然我不知道到底是怎么提取的,但是我知道一定是有隐含关联性的),如果向上面的只有一个中间的压缩编码数据层,此时我们的数据输入层与编码输出层是直接相连接的,如果我在神经元节点上不使用非线性激活函数,我们发现,这会得到和PCA类似的降维效果。所以,最好是多添加几个网络层,来储存输入数据之间的那些隐含关系,存储它们的潜在特征和关联。
总结起来:自编码器需要“瓶颈+容量”
3、编码器的常见应用
异常监测、数据去噪、数据降维、图像修复、信息检索
https://baike.baidu.com/item/无监督学习/810193?fr=aladdin

在[Vincent,08] 中,随机损坏过程随机地将一些输入设置成零,有时可达一半。因此降噪自动编码机试图从未损坏(未缺失)值预测损坏(缺失)值,通过随机从损坏模式中选择子集。注意能从重置中预测任何变量子集是完全捕捉一组变量联合分布的充要条件(这也是Gibbs取样的原理)。将自动编码机转化为降噪自动编码机我们只要在输入中加入随机损失步骤。输入损失可以用很多方式,但我们使用最基本的随机使输入为零的方式。
http://mp.ofweek.com/ai/a045673121216
AutoEncoder通过普通的BP神经网络进行预训练,从而确定神经网络中权重矩阵W的初始值。其目标是让输入值等于输出值。首先用W对输入进行编码,经过激活函数后,再用WT进行解码,从而使得h(x)≈x。该过程可以看作是对输入数据的压缩编码,将高维的原始数据用低维的向量表示,使压缩后的低维向量能保留输入数据的典型特征,从而能够较为方便的恢复原始数据。需要注意的是:在对数据进行编码和解码时,使用的是同一个参数矩阵W。这可看作是一种约束,可以减少参数个数,降低模型复杂度。
数据压缩是指限制隐藏层神经元数量。数据压缩依靠的是数据本身是有冗余信息的。当输入是完全随机,相互独立同分布的时候,网络将很难学得一个有效的压缩模型,然而现实中的数据(自然图像、语言、声音)总是存在不同程度的冗余性。Autoencoder自编码网络通过学习发现并去掉了这些冗余信息。
实际上,自编码网络学习出的低维数据表示十分类似于PCA[请参见人工智能(46)]学习出的主成分。学习过程可以简单地描述为最小化一个损失函数L(x,g(f(x)))+Ω(h) , Ω(h)是惩罚项。当解码器是线性的且L是均方误差,就可以学习出与PCA方法相同生成子空间。AutoEncoder其实是增强的PCA。AutoEncoder 具有非线性变换单元,因此学出来的Code可能更精炼,对Input的表达能力更强。
另外一种数据压缩方式就是限制隐藏层的稀疏性,要求隐藏层中的激活神经元是“稀疏”的,即隐藏层中大部分神经元处于非激活状态。这样的编码器称为SparseAutoencoder稀疏自编码器。
算法流程大概为:由输入与输出的差别构造准则函数,再求各个参数的偏导数,再用BP方式更新各个权重(采用梯度下降法)。在Sparse Autoencoder网络训练中,前向传播步骤应同时计算ρ,然后在后向传播步骤时做相应的修改。
Autoencoder算法意义:
Autoencoder自动编码器尝试逼近一个恒等函数,使得输出x^接近于输入x。当然为了使这个函数有意义,需要加入一些限制条件,比如说限制隐藏神经元的数目,就可以发现一些有意义的结构。Autoencoder可以学习到数据的一些压缩表示。例如如果输入数据为200维,隐藏层为100个,那么就需要从这100维的数据中重构出200维的输出,使这个输出接近于200维的输入。因此这个隐藏层的100维的数据就必然会包含着输入数据的一些相关性。所以说Autoencoder就是为了学习到输入数据的相关性表示的一种方法。
Autoencoder算法优点:
1)有降维效果,可以用于提取主要特征;
2)可以抓住主要特征,故具有一定抗噪能力;
3)稀疏的可解释性好,现实场景大多满足这种约束;
4)算法比较稳健;
5)表达能力强;
6)扩展能力强;
7)便于数据可视化分析。
Autoencoder算法缺点:
1)理论上看起来很智能,但是实际上并不太好用;
2)压缩能力仅适用于与训练样本相似的样本;
3)要求 encoder 和 decoder 的能力不能太强。
https://blog.csdn.net/huaweimember/article/details/26863879

https://blog.csdn.net/randompeople/article/details/91351177
聚类算法是一种无监督的算法,由于不需要训练集,算法简单快速
K_means
对 K 值敏感。也就是说,K 的选择会较大程度上影响分类效果。在聚类之前,我们需要预先设定 K 的大小,但是我们很难确定分成几类是最佳的,比如上面的数据集中,显然分为 2 类,即K = 2 最好,但是当数据量很大时,我们预先无法判断。
对离群点和噪声点敏感。如果在上述数据集中添加一个噪音点,这个噪音点独立成一个类。很显然,如果 K = 2,其余点是一类,噪音点自成一类,原本可以区分出来的点被噪音点影响,成为了一类了。如果 K = 3,噪音点也是自成一类,剩下的数据分成两类。这说明噪音点会极大的影响其他点的分类。
初始聚类中心的选择。K-means 是随机选择 K 个点作为初始的聚类中心。但是,我们可以对这个随机性进行一点约束,使迭代速度更快。举个例子,如果上面的数据集我随机选择了(0,0)和(1,0)两个点,或者选择了(1.5,1.5)和(9,9)两个点,即可以加快迭代速度,也可以避免陷入局部最优。
只能聚凸的数据集。所谓的凸数据集,是指集合内的每一对点,连接两个点的直线段上的每个点也在该集合内。通俗讲就是K-means 聚类的形状一般只能是球状的,不能推广到任意的形状,但是有研究表明,若采用 Bregman 距离,则可显著增强此类算法对更多类型簇结构的适用性
https://blog.csdn.net/fantacy10000/article/details/92664417
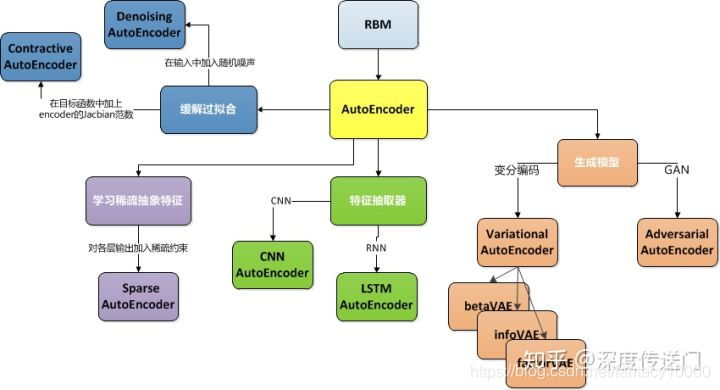
https://wenku.baidu.com/view/94dbd96988eb172ded630b1c59eef8c75ebf95ce.html
其实原理特别简单,只需要在编码过程给它增加一些限制,迫使其生成的隐含向量能够粗略的遵循一个标准正态分布,这就是其与一般的自动编码器最大的不同。
这样我们生成一张新图片就很简单了,我们只需要给它一个标准正态分布的随机隐含向量,这样通过解码器就能够生成我们想要的图片,而不需要给它一张原始图片先编码。
在实际情况中,我们需要在模型的准确率上与隐含向量服从标准正态分布之间做一个权衡,所谓模型的准确率就是指解码器生成的图片与原图片的相似程度。我们可以让网络自己来做这个决定,非常简单,我们只需要将这两者都做一个loss,然后在将他们求和作为总的loss,这样网络就能够自己选择如何才能够使得这个总的loss下降。另外我们要衡量两种分布的相似程度,如何看过之前一片GAN的数学推导,你就知道会有一个东西叫KL divergence来衡量两种分布的相似程度,这里我们就是用KL divergence来表示隐含向量与标准正态分布之间差异的loss,另外一个loss仍然使用生成图片与原图片的均方误差来表示。
原文:https://www.cnblogs.com/rinroll/p/14436534.html