Linear Algebra Learning From Data
1.1 Multiplication Ax Using Columns of A
有关于矩阵乘法的理解深入
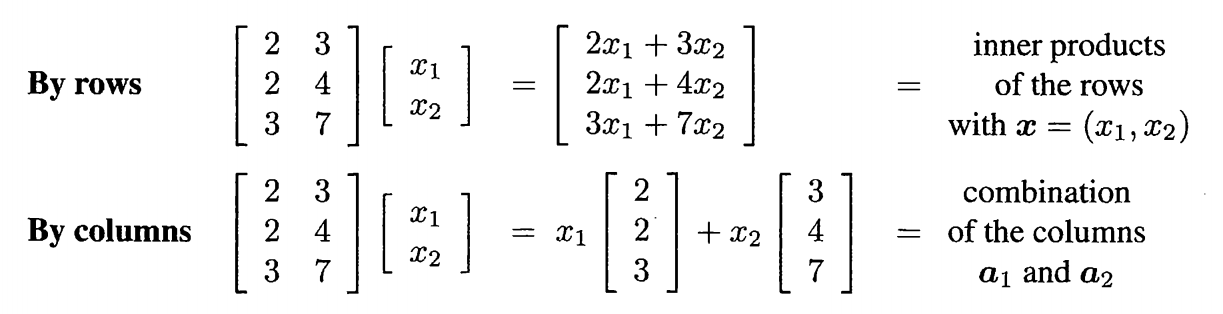
- 矩阵乘法理解为左侧有是一个向量集合,都是由列向量组成的,随后右侧则是一个待变换的向量,当这个向量作用于这个向量组之后等效于在这个向量组为基底进行了换底操作,这样就从原来的单位向量基底换到了这个新的向量基底。
向量空间理解

- 向量空间的理解: 所有的向量组都表示着一个向量空间,而这个向量空间是只能描述比这个向量底的维度,所有的向量空间都必须包含零空间(Zero Space)
矩阵A=CMR理论
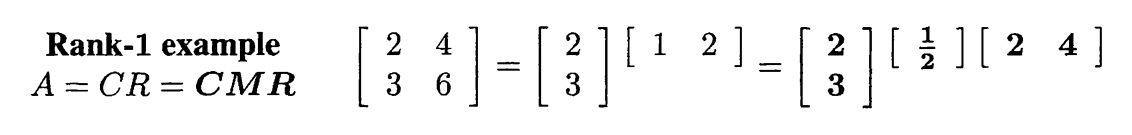
上述的第一步就是划分为A=CR的过程,从左侧的一个个向量组中寻找一个个线性无关的向量组,如果发现不相关,就以列向量的形式填入到右侧的C矩阵中,随后找完之后,取其系数填入右侧的R矩阵中,最后的M矩阵实际上是从R矩阵中剥离出来的一个方阵,根据这种变换方法,我们也可以证明有关于转置的一系列结论。

实际上每一个矩阵都可以做到A=CR分解,值得质疑的是到底下面这个式子是否真的有逆。
\[C^TC与RR^T
\]
首先我们C的列向量个数与R的行数都等于矩阵A的秩,这个秩的存在导致这两个矩阵的秩都是等于原来方阵的秩的,而这连个矩阵的行数与列数都是等于r的,再加上秩也等于r,那么这个方阵必有逆,也就是说这个M矩阵必定存在。
1.2 Matrix-Matrix Multiplication AB
- 引入,我们以前计算矩阵都是按照书上的公式化流程,实际上这种做法非常不正规,或者说不好理解,由上面的铺垫,我们现在得出了一个新的理解方法。
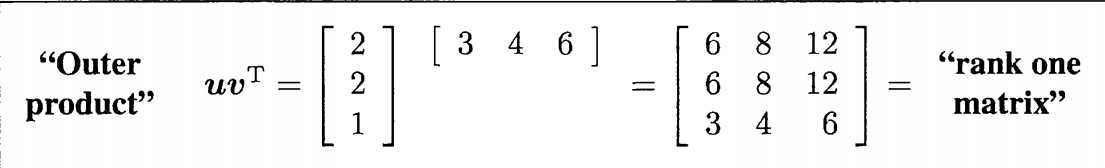
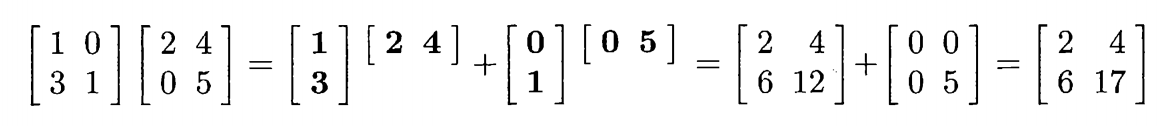
我们按照上面的方法实操一下;首先使用第一节的矩阵与向量乘法的理解与矩阵分解A=CR的理解,那么把右侧矩阵的每一列看作是一个向量,那么这个向量需要使用左侧的矩阵得以线性表示,按照左侧的向量划分,自然的来看,就比如说第一个向量,需要乘以右侧的矩阵的第一行的每一个元素,在各自的向量中占据第一维度的位置,那么就按照左侧第一列乘以右侧第一行来表示左侧第一个列向量在各个右侧向量组中的分量,自然就有后面的式子了。
其实这样也就理解了为什么矩阵的乘积是列数等于右侧,而行数等与左侧矩阵,左侧代表维度的变化,左侧的行数限制了最高维度,右侧的列数就是待变换的向量的个数,实际上也就是乘积所得矩阵中列向量的个数。
按照上面的理解不难有这样的推论,按照右侧为列向量,左侧为变换矩阵
\[\begin{bmatrix}
1 & 0 \3 & 1
\end{bmatrix}
\begin{bmatrix}
2 & 4\0 & 5
\end{bmatrix}
=
\begin{bmatrix}
\begin{bmatrix}
1 & 0 \3 & 1
\end{bmatrix}
\begin{bmatrix}
2\\0
\end{bmatrix}
&
\begin{bmatrix}
1 & 0 \3 & 1
\end{bmatrix}
\begin{bmatrix}
4 \\ 5
\end{bmatrix}
\end{bmatrix}
=\begin{bmatrix}
2 & 4 \6 & 17
\end{bmatrix}
\]
到现在你可能已经发现矩阵的乘法的内容其实非常多,理解方式不同,但是得到的结果确实是相同的,其实这也就是线性代数的魅力所在,矩阵的乘法也是及其严格的法则,不是随便定下来的。
为什么我们要做矩阵的分解
首先举一个例子,我最近在看书的时候遇到一个问题,当我想以我以前常用的那样对发现一个描述人脸的灰度向量使用一些诸如随机森林,梯度上升树之类的时候,发现算法的真确性及其低下,基本无法识别,这是由于典型算法对于数据非常敏感,准确的说,这个数据本身就是非常敏感的,当人脸稍微移动一点点的时候,整个向量的灰度值就会发生全体性的偏离,后来找到了一个叫做PCA的算法,这是一种矩阵分解的方法,它可以找到矩阵中最特殊的部分,分解出来,这样的矩阵就相比于直接使用大矩阵会高效很多,而且计算量也小了。
目前的一系列分解问题

实对称矩阵对角化的证明
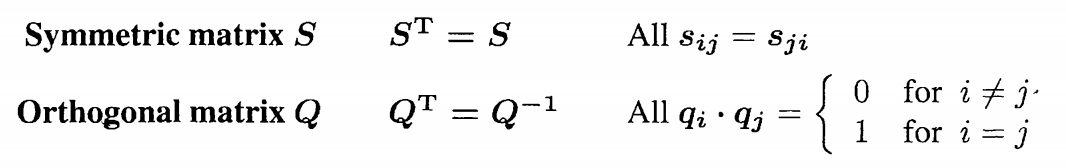
- 实对称矩阵的特征向量一定正交
\[假设有一个A矩阵,A是一个n阶实对称矩阵,已经存在n个线性无关的特征向量,假设有特征值\lambda _1 \dots \lambda_m\Ax_1=\lambda_1x_1 \dots\dots (1)\Ax_2=\lambda_2x_2 \dots\dots (2)\对(1)同时左x_2^T\x_2^T Ax_1=x_2^T\lambda_1x_1 \再同时转置\x_1^TAx_2=x_1^T\lambda_2x_2=x_1^T\lambda_1x_2\\Rightarrow(\lambda_1-\lambda_2)x_1^Tx_2=0\那么由于\lambda_1 不等于\lambda_2则向量x_1与x_2正交
\]
有了上述这个结论之后就可以假定q为我们的特征向量,而Q为特征向量组成的特征向量组,当然这个向量组也是正交的
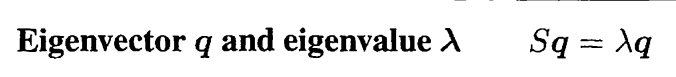
- 证明结论
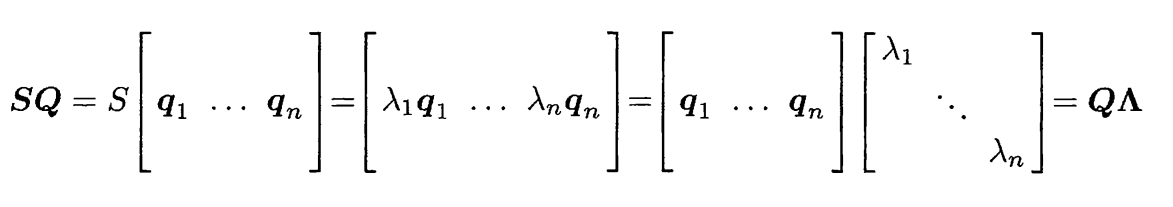
由于Q是正定的,所以说是可逆的,那么同时右乘以Q的逆,则证毕。
\[S = Q\Lambda Q^{-1}\又因为Q^{-1} = Q^{T}\S = Q\Lambda Q^T
\]
结合上述已经涉及到的内容又出现了这些小想法,S的秩是与中间对角阵的特征值数量挂钩的,又与正交矩阵Q的像两个数相挂钩。
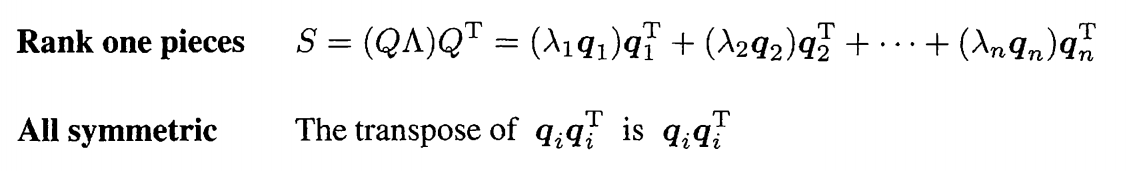
\[Q\Lambda = \begin{bmatrix}
\lambda_1q_1 & \lambda_2q_2 & \dots & \lambda_nq_n
\end{bmatrix}
\]
同样的也可以反向证明这个结论的真确性,在上式子同时右乘以qn那么不同的会应为正定而变为0,相同的为1,则成立。
1.3 The Four Fundamental Subspaces
向量空间的维度划分
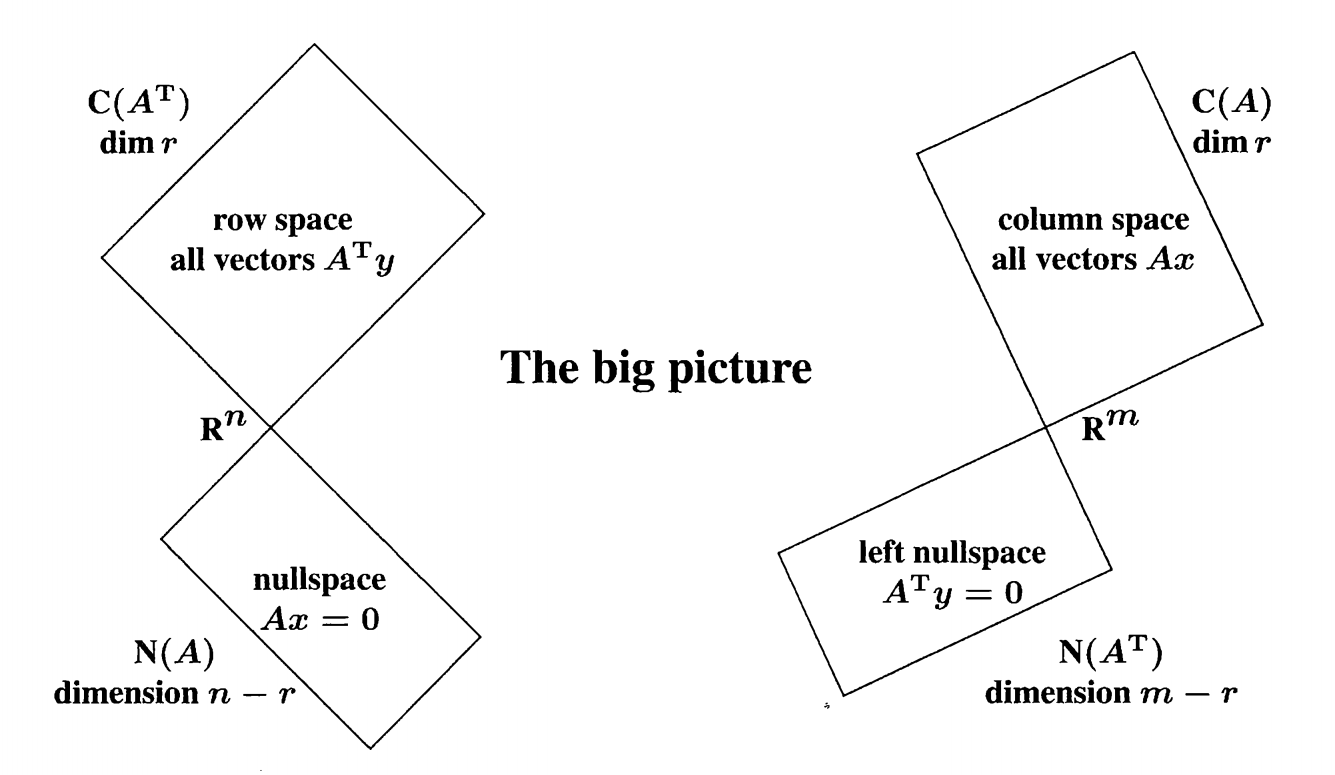
上述就是我们的真实的矩阵维度图
- 矩阵维度
- Column Space(列空间)
- Row Space (行空间)
- Right Nullspace (零解空间) 也就是行空间对应的零解空间
- Left NullSpace (右侧零解空间) 也就是列向量对应的零解空间 (一般用的很少)
举个例子
\[我们现在有一个矩阵叫做A=
\begin{bmatrix}
1 & 2 & 3 \2 & 4 & 6
\end{bmatrix}\经过上面几节的陈述我们已经知道矩阵是可以分解的A=CR\A=
\begin{bmatrix}
1 & 2 & 3 \2 & 4 & 6
\end{bmatrix} = \begin{bmatrix}1 \\ 2\end{bmatrix}\begin{bmatrix}1 & 2 & 3\end{bmatrix}\经过上式我们不难发现A的列向量空间维度与行向量空间维度都是1。也就是说\C(A)=1 \ \ \ C(A^T)=1\我们把A分解出来的列向量与行向量分别抽取出来\令C = \begin{bmatrix}1 \\ 2\end{bmatrix}\ \ \ R = \begin{bmatrix}1 & 2 & 3\end{bmatrix}\取出R,我们使之与一个未知向量x相乘等于零,也就是说Rx=0\不难解出来这个方程x有两个独立的向量\x_1 = \begin{bmatrix}3 \\ 0 \\ -1\end{bmatrix}\ \ \ x_2 = \begin{bmatrix}2 \\ -1 \\ 0\end{bmatrix}\而这个解其实也就是我们说的Ax=0的解了,那么这个零解空间也就是与A行空间垂直的\\那一个零解空间(可以回想矩阵乘法的过程,可以得到结论的正确性)\反之转置过后的方程也可以得到一样的流程去操作\得到的x=\begin{bmatrix}2 \\ -1\end{bmatrix}\\ 只有一个向量那么这个维度就是1了\最后得出下面这样的结论
\]
设有一个mxn的矩阵A
| 向量空间 |
维度 |
| 列向量空间 C(A) |
r |
| 行向量空间 C(A^T) |
r |
| 左零解空间 N(Ax=0解得的x的维度, 与行向量空间垂直的零解空间) |
n - r |
| 右零解空间 N (A^Tx=0解的x的维度,与列向量空间垂直的零解空间) |
m - r |
关于空间的垂直关系可以这样理解: 上述的A=CR分解中,C是从A中剥离出来的列向量空间;R是从A中剥离出来的行向量空间
而在去求解NullSpace的时候,同时右乘上的x是可以直接与R作用的(内积),而R是A的行向量空间,
而这个Rx的乘积的零向量,那么也就是说这里的x向量组合是与R这个行向量空间是垂直的(内积为0)或者说,正定的。
这也是为什么Ax=0解得的是与列向量空间垂直的NullSpace空间
- 再借助上面的例子提一句话,如果一个向量组是线性相关的,那么我们就可以构建一个闭环去描述这个向量组空间,其中每一个节点都是一个向量,如果不是线性无关的,那么这个向量空间将不是闭合的,我们称前面的那种为loop,后面的为tree。(这里涉及离散数学的图论,目前还不很清楚原理)
The Ranks of AB and A+B

- 矩阵AB的秩不大于A的秩,也不大与B的秩.也就是Rank(AB) ≤ min{Rank(A), Rank(B)}
- 首先把A当作一个变换矩阵,那么这个矩阵A规定了我们的基底向量,组成了基底向量组,而B矩阵只是一堆待变换的向量组,所以说AB的秩是完全不大于A的秩的,同理在经过转置之后也可以得到后面的B的秩也是大于等于AB的秩的。同样使用方程组的思想也可以证明。
- A+B的秩不大于各自矩阵秩的和
- 矩阵若能进行加法,则矩阵之间的行列数必须完全相同,所以A+B的秩一定是小于等于max{Rank(A), Rank(B)}的因此也就一定有上式成立了
- 秩相等
- 假设A为mxn的矩阵,首先A的秩与A的转置的秩一定相等,A的转置乘以A时候,得到的是一个mxm阶的矩阵,时刻注意矩阵的分解,这时候把A看作是R,那么就有矩阵的而转置不改变秩,那么就有上式的秩与A的秩相等了。同理这个转置后不改变秩,那么仍然成立
- 如果A是mxr阶矩阵,B是rxn阶矩阵,那么我们就有AB的秩也为r
- 矩阵的分解,同样可以证明。实际上写出来就是A=CMR了,中间的M矩阵就是那个r阶矩阵,由于A和B的秩都为r,那么有A^T A的秩也为r,B^T B的秩也为r那么我们使用定理1得到了rank(AB)大于等于rank(ATABBT)那么也就是说我们这个矩阵的秩是大于等于r的,而我们又知道rank(AB)小于等于rank(A),所以明题得证
Hadamard矩阵
定义1.1
设H为一个(1, -1)矩阵,即以1, -1为基本元素的\(n\times n\)的矩阵,若:
\[HH^T=nI
\]
则称H为一个n阶Hadamard矩阵,简称\(H-矩阵\)
定义1.2
假定存在\(m\)阶矩阵Hadamard矩阵,若其第一行的元素全是1,则称其为一个行规范的\(H-矩阵\);
若其第一列元素全部都是1,则称其为一个列规范型\(H-矩阵\);若既是列规范又是行规范,则称其为规范的\(H-矩阵\)
性质1.1
假定存在一个m阶的\(H-矩阵H_m\),则
\[|detH_m|=m^{\frac{m}{2}}
\]
反之则存在矩阵
\[H=(a_{ij})_{m\times m},若|a_{ij}|\leq1(1\leq i, j \leq m),且|detH|=m^{\frac{m}{2}}
\]
这也就是说每个元素\(|a_{ij}|\)都是小于等于 1
则称这个H为\(H-矩阵\)
性质1.2
假定\(H\)是\(H-矩阵\),令把对其实行的下述变换的任意组合所得到的矩阵记作为\(H‘\)
\[(1)行换序;\(2)列换序;\(3)对于某些行(列)乘以-1;\(4)转置;
\]
由\(H\)的正定性知\(H‘\)仍然为\(H-矩阵\).
两个同阶\(H-矩阵\)等价,若通过其中一个出发经过上述有限次变换之后都可以变换称为另外一个,显而易见的是任意两个同阶的\(H-矩阵\)等价
性质1.3
若m阶\(H-矩阵\)存在,则\(m=1,2\)或者\(m(mod 4 )=0\) (m对4取余一定等于0).
\[\sum_{j=1}^{m}(h_{1j} + h_{2j})(h_{1j}+h_{3j})=\sum_{j=1}^{m}h_{1j}^2=m
\]
这里使用左侧是强行凑上去的两\(h_{2j},h_{3j}\)是为了使用下面的结论
\[h_{1j}+h_{2j}=\pm2,0\ \ \ \ \ \ \ h_{1j} + h_{3j}=\pm2, 0 \ \dots\dots (1)
\]
首先\(H-矩阵\)是正交的,\(h_{1j}\)代表的是一行行的元素,那么每行的元素的内积一定是1
从元素的角度分析,当不同行的元素的成内积的时候,由于\(H-矩阵\)的元素只有\(\pm1\)
所以应为不同行的元素内积得0,得出这两行的元素的对应位置上相同的元素个数与不同
元素的个数是完全相等的,只有这样才能得出内积为0的结果,计算两个向量的和的时候,
由于对应位置上元素不同的位置的和为0,那么也就是说其相同项的由于元素完全相同,那么
只是留下了\(\pm2\),所以我们说这个\(h_{1j}+h_{2j}=\pm2,0\),表示这个向量只有\(\pm2与0所组成\)
所以上式就可以提出来一个2,那么m就一定是4的倍数了,也就是说如果一个\(H-矩阵\),那么它的阶数一定是$m(mod\ 4)\ =\ 0 $
构造方法
方法一:使用矩阵的\(Kronecker\) 积构造\(Hadamard\)矩阵
-
定义2.1
? 设\(A=(a_{ij})\)为一个\(m\times p\)的矩阵,\(B=(b_{ij})\)为一个\(n\times q\)矩阵,令:
\[A\times B=\begin{bmatrix}
a_{11}B & a_{12}B & \dots & a_{1p}B\a_{21}B & a_{22}B & \dots & a_{2p}B\\vdots & \vdots & \ddots & \vdots\a_{m1}B & a_{m2}B & \dots & a_{mp}B
\end{bmatrix}
\]
这样的形式\(A\times B\)被称作为直积,也被叫做\(Kronecker\)积
-
引理
设m为一个常数,\(A,A_1, A_2\)为\(m\times p\)矩阵,\(B,B_1,B_2\)为\(n\times q\)的矩阵,C为\(p\times s\)矩阵,D为\(q\times t\)矩阵,则有下面这些定理的出现
\[(1)m(A\times B)=(mA)\times B \(2)A\times (B_1+ B_2)=A\times B_1 + A\times B_2\(3)(A_1 + A_2)\times B = A_1 \times B + A_2\times B\(4)(A\times B)^T=A^T \times B^T\(5)(A\times B)(C\times D)=AC\times BD\ \ (这个与预想的不同)
\]
(1)~(4)显然成立,现在证明(5)
\[A=\begin{bmatrix}
a_{11} & a_{12} & \dots & a_{1p}\a_{21} & a_{22} & \dots & a_{2p}\\vdots& \vdots & \ddots & \vdots\a_{m1} & a_{m2} & \dots & a_{mp}
\end{bmatrix}\C=\begin{bmatrix}
c_{11} & c_{12} & \dots & c_{1s}\c_{21} & c_{22} & \dots & c_{2s}\\vdots& \vdots & \ddots & \vdots\c_{p1} & c_{p2} & \dots & c_{ps}
\end{bmatrix}\(A\times B)(C\times D)=\begin{bmatrix}
a_{11}B & a_{12}B & \dots & a_{1p}B\a_{21}B & a_{22}B & \dots & a_{2p}B\\vdots& \vdots & \ddots & \vdots\a_{m1}B & a_{m2}B & \dots & a_{mp}B
\end{bmatrix}\begin{bmatrix}
c_{11}D & c_{12}D& \dots & c_{1s}D\c_{21}D & c_{22}D & \dots & c_{2s}D\\vdots& \vdots & \ddots & \vdots\c_{p1}D & c_{p2}D& \dots & c_{ps}D
\end{bmatrix}\=\begin{bmatrix}
\sum_{i=1}^{p}a_{1i}c_{i1}BD & \sum_{i=1}^{p}a_{1i}c_{i2}BD & \dots & \sum_{i=1}^{p}a_{1i}c_{is}BD \\
\vdots & \vdots & \dots & \vdots \\sum_{i=1}^{p}a_{mi}c_{i1}BD & \sum_{i=1}^{p}a_{mi}c_{i2}BD & \dots & \sum_{i=1}^{p}a_{mi}c_{is}BD
\end{bmatrix}=(AC)\times (BD)
\]
所以不难证明这个定理是成立的。
定理2.1
\[\begin{eqnarray*}
(H_1\times H_2)(H_1\times H_2)^T
&& =(H_1\times H_2)(H_1^T\times H_2^T)\&& =(H_1H_1^T)\times (H_2H_2^T)\&& =(mI)\times (nI)\&& =mnI
\end{eqnarray*}
\]
推论1
- 若H为一个m阶\(H-矩阵\),则\(\begin{pmatrix}H & H\\ H & -H\end{pmatrix}\)是一个2m阶\(H-矩阵\)
由于\(H_2\)是\(\begin{pmatrix}1 & 1\\ 1 & -1\end{pmatrix}\),所以上述的结论显然成立
推论2
- 任意\(t \geq 0, 2^i\)阶的\(H-矩阵\)都是一定存在的
方法二:利用矩阵的强直积构造\(Hadamard\)矩阵
- 定义2.2.2 设\(A\)为如下的\(tm\times tm\)矩阵
\[A=
\begin{bmatrix}
A_{11} & A_{12} & \dots & A_{1t}\A_{21} & A_{22} & \dots & A_{2t}\\vdots & \vdots & \ddots & \vdots\A_{t1} & A_{t2} & \dots & A_{tt}\\end{bmatrix}\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ A是一个m\times m阶矩阵\\]
又设B为如下的\(tn\times tn\)矩阵
\[B =
\begin{bmatrix}
B_{11} & B_{12} & \dots & B_{1t}\B_{21} & B_{22} & \dots & B_{2t}\\vdots & \vdots & \ddots & \vdots \B_{t1} & B_{t2} & \dots & B_{tt}\\end{bmatrix}\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ B是一个n\times n阶矩阵
\]
令下式成立:
\[A\otimes B=P=
\begin{bmatrix}
P_{11} & P_{12} & \dots & P_{1t}\P_{21} & P_{22} & \dots & P_{2t}\\vdots & \vdots & \ddots & \vdots \P_{t1} & P_{t2} & \dots & P_{tt}\\end{bmatrix}
\]
其中\(P_{ij}=\sum_{k=1}^{t}A_{ik}\times B_{kj}(1\leq i, j\leq t)\)则称\(P\)为\(A\)与\(B\)的强直积
元素换成矩阵的一种乘法
引理2.2.2 定义2.2.2中\(A\)与\(B\)若满足
\[AA^T=rI_{tm};\ \ BB^T=sI_{tm}
\]
则
\[(A\otimes B)(A\otimes B)^T=rsI_{tmn}
\]
证明:设
\[(A\otimes B)(A\otimes B)^T=
\begin{bmatrix}
L_{11} & L_{12} & \dots & L_{1t}\L_{21} & L_{22} & \dots & L_{2t}\\vdots & \vdots & \ddots & \vdots\L_{t1} & L_{t2} & \dots & L_{tt}\\end{bmatrix}
\]
则有当\(1\leq a, b \leq t\),
\[\begin{eqnarray*}
L_{ab}
&&=\sum_{k=1}^t(A_{a1}\times B_{1k} + A_{a2}\times B_{2k}+\dots+A_{at}\times B_{tk})(A_{b1}^T\times B_{1k}^T+A_{b2}^T\times B_{2k}^T+\dots + A_{bt}^T\times B_{tk}^T)\&&=\sum_{k=1}^{t}\sum_{i=1}^{t}\sum_{j=1}^{t}(A_{ai}\times B_{ik})(A_{bj}^T\times B_{jk}^T)\&&=\sum_{k=1}^{t}\sum_{i=1}^{t}\sum_{j=1}^{t}(A_{ai}A_{bj}^T)\times (B_{ik}B_{jk}^T)\&&=\sum_{k=1}^{t}\sum_{i=1}^{t}(A_{ai}A_{bj}^T)\times\sum_{j=1}^{t}(B_{ik}B_{jk}^T)
\end{eqnarray*}
\]
分析:
\[B_{ik}B_{jk}=
\begin{cases}
0\ \ \ \ \ \ \ \ \ \ \ i\neq j\sI_{n} \ \ \ \ \ \ \ i=j
\end{cases}
\]
而:
\[A_{ai}A_{bj}=
\begin{cases}
0\ \ \ \ \ \ \ \ \ \ \ a\neq b\rI_{m} \ \ \ \ \ \ a=b
\end{cases}
\]
则可以知道只有当\(a=b\)时候才有值不等于零,而这个值就是\(rsImn\), 证毕!
定理2.2.2
- 若\(A\)为\(2m\)阶的\(H-矩阵\),\(B\)为\(2n\)阶的\(H-矩阵\),则\(2mn\)阶矩阵\(H-矩阵\)也必然存在。
证明:
令
\[C=\frac{1}{2}A
\begin{bmatrix}
I_m & I_m\I_m & -I_m
\end{bmatrix}
\]
这么设的目的完全是为了构造
则:
\[CC^T=\frac{1}{2}AA^TmI_{2m}=mI_{2m}
\]
易知:
\[BB^T=2nI_{2n}
\]
则通过引理知道:
若
\[H=C\otimes B
\]
则:
\[HH^T=(C\otimes B)(C \otimes B)^T=2mnI_{2mn}
\]
所以说这个\(2mn\)阶的\(H-矩阵\)一定存在的,证毕!
方法三: 利用反形\(H-矩阵\)和\(H-矩阵\)睦偶来构造\(Hadamard\)矩阵
定义2.2.3
- 若存在一个\(H-矩阵\)\(H\),满足条件\(H=S+I\),\(S^T=-S\),则称\(H\)是一个反形\(H-矩阵\)
定义2.2.4
- 若存在\(H-矩阵\)\(H\),若满足\(H^T=H\),则称\(H-矩阵\)是对称\(H-矩阵\)
定义2.2.5
- 设\(M\)是一个反型\(H-矩阵\),\(N\)是一个同阶的对称\(H-矩阵\),如果满足条件
\[MN=NM^T
\]
- 则称\(M\)和\(N\)为一对\(Hadamard\)矩阵睦偶,简称一对\(H-矩阵\)睦偶
也就是说这个MN矩阵是对称矩阵
定理2.2.3
(1) \(h\)阶反型\(H-矩阵\)\(H=U+I\);
(2) \(m\)阶\(H-矩阵\)睦偶\(M=W+I\), \(N=N^T\)
(3)三个\(l\)(1, -1)矩阵\(X,Y,Z\)满足
\[(XY^T)^T=XY^T, (YZ^T)^T=YZ^T,\(ZX^T)^T=ZX^T,XX^T=aI+(l-a)J,\YY^T=cI+(l-c)J,ZZ^T=(l+1)I-J;
\]
这里的,\((m-1)c=m(l-h+1)-a\),那么矩阵
\[\overline{H}=U\times N\times Z + I_{n}\times W\times Y + I_n\times I_m \times X
\]
是一个\(mlh\)阶的\(H-矩阵\)
证明: 由\(\overline{H}\)的构造式子可知,\(\overline{H}\)是一个(1, -1)矩阵,另外一方面,由条件(1),(2)知:
\[U^T=-U,UU^T=(h-1)I_h;\\W^T=-W,WW^T=(m-1)I_m\MN=NM^T,MM^T=N^2=mI_m,WN=NW^T(下有简单证明)
\]
M,N都是两个\(Hadamard\)矩阵,所以有\(MM^T=NN^T=mI_m\)
\[MN=NM^T\(W+I)N=N(W+I)^T\WN=NW^T\\]
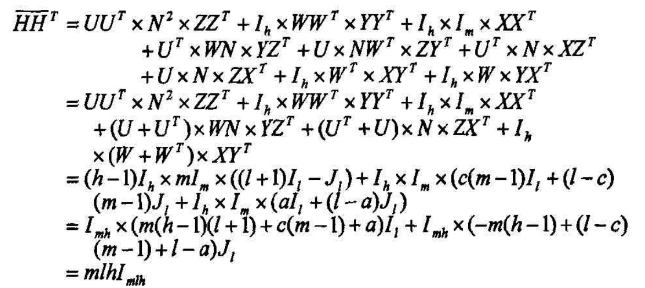
- 所以这个\(\overline{H}\)Hadamard矩阵存在
Hadamard矩阵学习
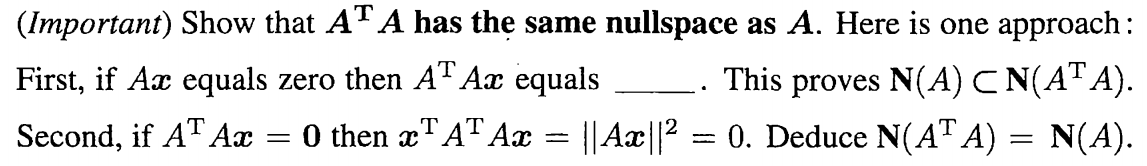
如果说\(Ax=0\)那么\(A^TAx=0\)所以说,\(Ax=0\)的解一定属于\(A^TAx=0\)的解
如果说\(A^TAx=0\),然后左右同时乘以\(x^T\)\(\Rightarrow\)\(x^TA^TAx=0\)\(\Rightarrow\)\(||Ax||=0\)也就是说这个\(Ax=0\)成立
所以说这两个矩阵\(A^TA与A\)矩阵同阶
如果说\(A^2\)与\(A\)拥有同一个nullspace,那么这个矩阵\(A\)一定就是方阵
为解决的问题:
如果说N(A)是一个零向量,那么也就是说这个\(Ax=0\)的列向量空间满秩了,
如果说B= \(\begin{bmatrix}A & A & A\end{bmatrix}\)如果去找\(Bx=0\)的解,由于A已经是列满秩,那么会多出来
1.4 Elimination and \(A = LU\)
前面学过的矩阵的分解,我们可以知道关于方程组\(Ax=0\)的解实际上是解的\(A\)的行向量空间的解,那么我们理所当然的知道\(xA=0\)的解是行空间的解。
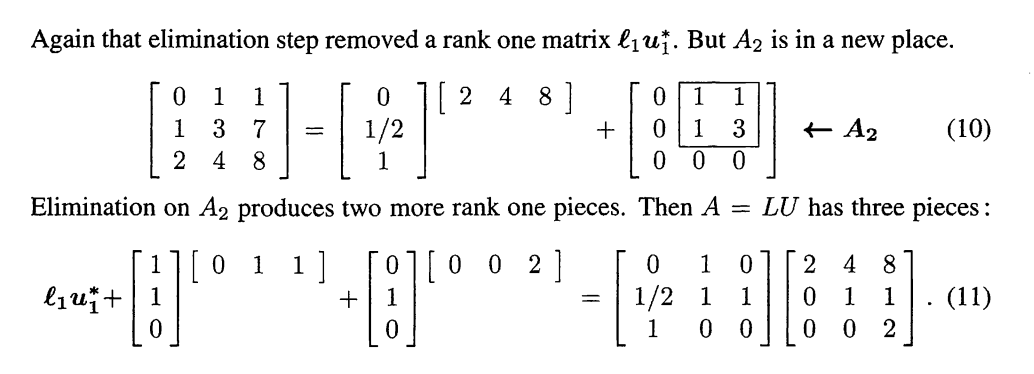
- 使用之前学习的矩阵的\(A=CMR\)可以对每一列的元素与之对应的行进行构造,使得所有的行与列都可以构造出一个秩为1的新矩阵,最后再加和起来就形成了矩阵的分解,有时候需要强调的是,矩阵分解过后不一定是两个上下三角的矩阵,所以需要酌情进行行变换!注意是行变换
这么做确实是有点麻烦,我想要算矩阵的行列式,本来应该非常迅速(直接转换称为上三角矩阵),但是这种方法的好处在与把变换矩阵也顺便存储了下来,避免了矩阵行变换时候的变化导致的原矩阵与后来矩阵的不等关系
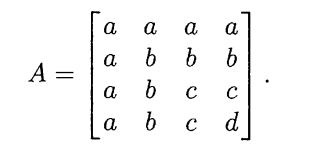
计算上类行列式公式:\(|A|=a(b-a)(c-b)(d-c)\)也就是除了第一行元素以外的所有相对差值之积
- 二次型的标准化的合同过程,由于对称,所以两个方向上的变换可以由一个变换矩阵来描述
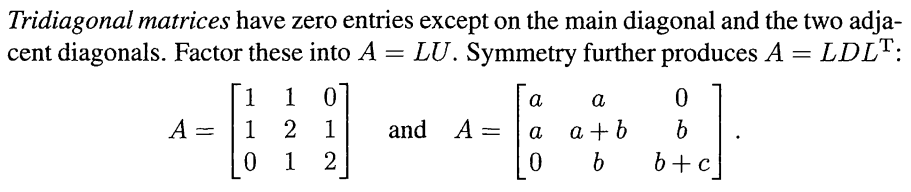
关于选择矩阵拆分的时候,如果选择从左上角往右下角去拆,得到的将会是很标准的矩阵变换形式,但是如果从左下到右上角的变换,则会变成两个不那么标准的变换矩阵的乘积形式,所以推荐使用从左上到右下,也就是从第一行第一列开始变换
1.5 Orthogonal Matrices and Subspaces
左逆与右逆矩阵

![技术分享图片]()
关于左右伪逆矩阵,通过左右逆矩阵的形式构造出来的,例如左伪逆矩阵的\(L=(A^TA)^{-1}A^H\Rightarrow (A^TA)^{-1}A^HA=I\)
显然成立,这就是显然成立
本质上就是通过矩阵无法增维的想法,首先先构造一个满秩的\(n\times n\)的矩阵空间,随后逆过去,使得\(A\)作用于这个变换矩阵,最后得到我们的左伪逆。
旋转矩阵与反射矩阵
\[旋转矩阵=\begin{bmatrix}cos\theta & -sin\theta\\sin\theta & cos\theta\end{bmatrix}
\]
\[反射矩阵=\begin{bmatrix}cos\theta & sin\theta \\ sin\theta & -cos\theta\end{bmatrix}
\]
- 旋转矩阵:使得一个向量旋转\(\theta\)的角度
- 反射矩阵:使得所有的向量镜面投影到另外一个面上
\(Household Transformation\)
- 首先我们有一个单位向量\(u\),满足\(u^Tu=1\)
- 令\(H=I-2u^Tu\)
- 容易检验\(H^TH=I\)
- 这样就说明了这个矩阵是正交的
- \(H_n = I - 2uu^T = I - \frac{2}{n}ones(n)\)
Householder Transformation 阅读资料
$Hadamard矩阵 $
\(Haar\ \ wevalets\)
从正交角度理解\(Ax=0\)
\(Ax=0\)自然是可以看作是一个矩阵正交的过程,而这里找到的是\(A\)中行空间的正交关系,首先分析一个简单的情况
\[A = \begin{bmatrix}1 & 0 & 0\\ 0 & 1 & 0\\ 1 & 1 & 0\end{bmatrix}
\]
要找到这个\(Ax=0\)的解那么我们必须得去找到\(A\)行空间中的最小的无关向量组,也就是第一第二行,这样再去找一个向量,完全与这两个都正交,现在再想,把这两个行向量看作是\(x,y\)平面上的单位向量那么这个,这个其实就是描述的是\(xoy\)平面自然的,\(z\)轴上的分量的长度就不需要加以限制了
有换句话说,如果说秩为1的话,A矩阵描述的就是一个向量,在这个\(3\times 3\)的矩阵空间中,可以垂直于这个向量的必然存在着一个平面,而描述这个平面又可以又很多的向量,这也就是为什么这种方程的解总不是唯一的,应为一个维度解总不是唯一的。
理解了3维以后,上升到4维,空间总是会沾满的,A描述的空间,不够充足的部分,将由零解空间去填满。
正交投影(\(Orthongonal Projection\))
- 如果说一个矩阵存在一个它本身的转置使得\(Q^TQ=I\)
- 那么令一个矩阵为\(P= QQ^T\)
在了解正交投影之前先举一个最基本的例子
\[有这样一个变换矩阵A= \begin{bmatrix}1 & 0\\ 0 & 1\\ 0 & 0\end{bmatrix}\现在有一个向量v = \begin{bmatrix}1\\2\\3\end{bmatrix}
\]
则有
\[A^T = \begin{bmatrix}1 & 0 & 0\\ 0 & 1 & 0 \end{bmatrix}
\]
那么
\[A^Tv = 1\begin{bmatrix}1 \\ 0\end{bmatrix} + 2\begin{bmatrix}0 \\ 1\end{bmatrix} + 3\begin{bmatrix}0 \\0\end{bmatrix} = \begin{bmatrix}1 \\ 2\end{bmatrix}
\]
解释
- 之前理解的,这个矩阵乘法实际上就是向量向矩阵A的行向量空间的变换,而这个\(A^Tv\)向量就是存在于\(A^T\)空间中的(可以使用矩阵乘法的向量形式去理解)
然后
\[AA^Tv=\begin{bmatrix}1 & 0\\ 0 & 1\\ 0 & 0\end{bmatrix}\begin{bmatrix}1 \\ 2\end{bmatrix}
\]
而这一步则是将投影在A行空间中的向量再次投影回来
\[AA^Tv=\begin{bmatrix}1 \\ 2 \\ 0\end{bmatrix}
\]
可以发现这个向量就是存在于矩阵列向量空间的一个子向量
\[v_{\perp}= (I - AA^T)v
\]
同样的对于一个任意一个正交矩阵,即上述的\(Q\)
向量\(v\)在经过\(AA^T\)变换之后,正交投影到了A向量空间之中,也就是说\(AA^Tv\)是完全存在于\(A\)中的,
\[v_{\perp} = (I -AA^T)v
\]
关于为什么一定是得是\(AA^T=I\)这种类型的\(A\)
如果不是正定的,那么在投影到矩阵空间A的过程中,会导致一定程度的缩放,这样虽说\(v\)仍然还是在\(A\)空间中的,但是\(v_{\perp}\)就不能用上述公式求了,也自然计算会不方便,在几何上也就没那么美好了。
正交投影拓展阅读资料
写到这里,我发现有一点问题需要摒弃掉\(A\times v\)矩阵乘以向量,我们以前有两种方式去表示,一是完全的符号语言,二是向量的坐标表示,这表示的是数字,而可以知道,这些数本质都是在标准坐标系中的投影,数字非常具有迷惑性,老让你觉得数字不正常,其实说来,在完成这个矩阵乘法之后,我们应该看数字,而是看比例关系,看\(A\)中的向量组中的各个向量为一个独立的整体,而数字只是为了计算。上述的话总结成为一句话:
向量往矩阵的线性变换需要改变视角从这个矩阵的视角去看待这次变换,如果这个矩阵是正定的,那么其实无异于我们最基础的坐标系,数字只是为了方便于计算,除了比例关系,无实际意义。
小提示: 这样在找到垂直向量之后我们在倍延长\(v_{\perp}\)得到了对应面的镜面反射向量
1.6 \(Eigenvalues\) \(and\) \(Eigenvectors\)?
值得补充的是
1.7 \(Singular\) \(Value\) \(Decomposition\) (\(SVD\))
矩阵的奇异值分解就是\(A = U\Sigma V^T\)
-
首先先分析两个独特的矩阵
-
\(A^TA\), \(AA^T\)
\[A^TA = (A^TA)^T\AA^T = (AA^T)^T
\]
这两个矩阵是对称矩阵,那么其特征向量之间就一定是正交的,则有下式:
\[A^TA = V\Lambda V^T\AA^T = U\Lambda U^T
\]
在奇异值分解中我们需要得到这样的式子
\[Av_1 = \sigma_1u_1 \\dots\ \dots\Av_r =\sigma_r u_r
\]
我们要做的就是找到两个正交矩阵,使用\(A\)矩阵的线性变换去满足这两个矩阵的沟通
\[A[v_1 \dots v_r] = [u_1 \dots u_r]\begin{bmatrix}\sigma_1 & & & \\ & \ddots \\ & & & \sigma_r\end{bmatrix}\AV = U\Sigma\\]
故
\[A = U\Sigma V^T
\]
另外的
\[A^TA = V\Sigma ^TU^TU\Sigma V^T = V(\Sigma ^T\Sigma)V^T
\]
奇异值是特征值的开方\(\sigma_r = \sqrt{\lambda_r}\)
然后我们发现
\[v_1^Tv_2 = 0
\]
根据上式
\[u_1 = \frac{Av_1}{\sigma_1}\u_2 = \frac{Av_2}{\sigma_2}
\]
所以
\[u_1^Tu_2 = \frac{v_1^TA^TAv_2}{\sigma_1\sigma_2}=\frac{v_1^T\sigma_2^2v_2}{\sigma_1\sigma_2}=\frac{\sigma_2}{\sigma_1}v_1^Tv_2=0
\]
所以自然成立两个正交矩阵
至此我们的奇异值分解已经完成了
Notation
这里的\(U\)是一个行数与原矩阵相等的方阵, \(V\)是一个列数与原矩阵相同的方阵
\[Ax 的几何意义
\]
在矩阵\(A\)的变换效果下,\(x\)进行变换
\[Ax = U\Sigma V^Tx
\]
- 两个正交矩阵代表着旋转
- 中间的奇异值矩阵代表着伸缩
总结
先旋转,在伸缩,再旋转
\(Polar Decomposition\)
\[A = U\Sigma V^T = U\Sigma U^TUV^T = (U\Sigma U^T)UV^T
\]
显然前面一个是一个对称矩阵,下面证明后者是一个正交矩阵
\[(UV^T)^TUV^T= VU^TUV^T = VV^T = I
\]
结果显然。
小结:
$Singular\ value\ Decomposition \(和\)Polar\ Decomposition$都可以完成分解
奇异值分解可以帮助辨析,哪些信息是有用的,哪些是噪点,帮助我们找到主要的特征去描述这个对象,提高训练的准确度,和针对性,可以用在很多特征提取的地方
奇异值分解可以帮助我们挑出秩为1的组和
1.8 \(The\) \(Closest\) \(Rank\) \(k\) \(Matrix\) \(to\) \(A\)
如果说矩阵\(B\)的秩是\(k\), 那么\(||A-B||\) \(\geq\) \(||A- A_k||\)
这里的矩阵是取得的范数
矩阵的范数
-
欧式范数
- \(||V||_2\) = \(\sqrt{|v_1|^2 + \dots + |v_n|^2}\)
-
无限范数
- \(||V||_{\infty}\) = \(max|v_i|\)
-
\(l1\)范数
- \(||V||_1\)=\(|v_1|\) + \(|v_2|\) + \(|v_3|\) + \(|v_4|\) $+ \dots + $ + \(|v_n|\)
-
矩阵范数
-
定义
-
正定性: 矩阵A的范数\(||A|| \geq 0\) ,且 \(||A|| = 0 \iff A = 0_{m\times n}\)
-
线性性: \(||\alpha A|| = |\alpha||A||\)
-
三角不等式: \(||A + B|| \leq ||A|| + ||B||\)
-
某些情况下如果是方阵: \((n\times n)\)一致性: \(||AB|| \leq||A||\ ||B||\)
-
借助向量的范数推出矩阵范数
-
比如说矩阵\(A\)的范数\(||A||\) = \(sup\{||Ax||:x\in k^n\ when||x|| = 1\}\)
-
或者说\(||A|| = sup\{\frac{|Ax||}{||x||}: x\in k^n,x\neq \vec{0} \}\)
-
P-范数(针对的是向量范数)
- \((\sum_{i=1}^{n}|x_i|^p)^{\frac{1}{p}}\)
- 其中\(x = \begin{bmatrix}x_1\\x_2\\ \vdots x_n\end{bmatrix}\), 是个n维向量
-
由此得到我们矩阵的范数
\[||A|| = max\frac{||Ax||_p}{||x||_p}=max\frac{[\sum_{i=1}^{m}|\sum_{j=1}^{n}a_{ij}x_j|^p]^{\frac{1}{p}}}{[\sum_{j=1}^{n}|x_i|^p]^{\frac{1}{p}}}
\]
直接记结果,想知道为什么--->周国标师生交流讲席
简单分析下p的几个取值
\(p=1\) : 这时求解最大值的过程实际上就是在找\(x\)的过程,用\(||x||=1\)比较方便计算,则有\(|x_1|+ \dots + |x_n|=1\),要想取得最大值,我们就得给最大列分配最大的系数。那么就得出\(||A||_1 = max\sum_{i=1}^{m}|a_{ij}|\ (1\leq j \leq n)\)
\(p= +\infty\): 这时候求解最大值时候,求解\(||x||_{\infty}\),有个不等式,得出\(||x|| = \begin{bmatrix}1 \\ 1 \\ \vdots \\ 1\end{bmatrix}\)这样,\(||A||_{\infty} = max\sum_{j=1}^{n}|a_{ij}|\ (1 \leq i \leq m)\),取最大行
\(p=2\) 引入\(Frobenius\ norm / Hilbert\ Schmich\ norm\)
\(||A||_F\) = \(\sqrt{trace(A^TA)} = \sqrt{\sum_{i=1}^{min\{m ,n\}}\sigma_i^2}\)
\(||A||_2\) = \(\sigma_{max}(A)\) \(\leq ||A||_F\)
\(p=0\): 非零元素的个数
- 核范数
- \(||A||_N = \sum_{i=1}^{r}|\sigma_i|\)
Linear Algebra From Data
原文:https://www.cnblogs.com/mushrain/p/14444568.html