当我们操作的文件有中文字符的时候,怎么操作呢这个时候我们就用到了字符流,我们去一个字符一个字符取读取。
能识别中文的码表:GBK、UTF-8;正因为识别中文码表不唯一,涉及到了编码解码问题。
对于我们开发而言;常见的编码 GBK UTF-8 ISO-8859-1
文字--->(数字) :编码。 “abc”.getBytes() byte[]
(数字)--->文字 : 解码。 byte[] b={97,98,99} new String(b,0,len)
字符输入流reader 字符输出流writer
read():读取单个字符并返回
read(char[]):将数据读取到数组中,并返回读取的个数。
查阅FileInputStream的API,发现FileInputStream 用于读取诸如图像数据之类的原始字节流。要读取字符流,使用 FileReader。
构造方法如图

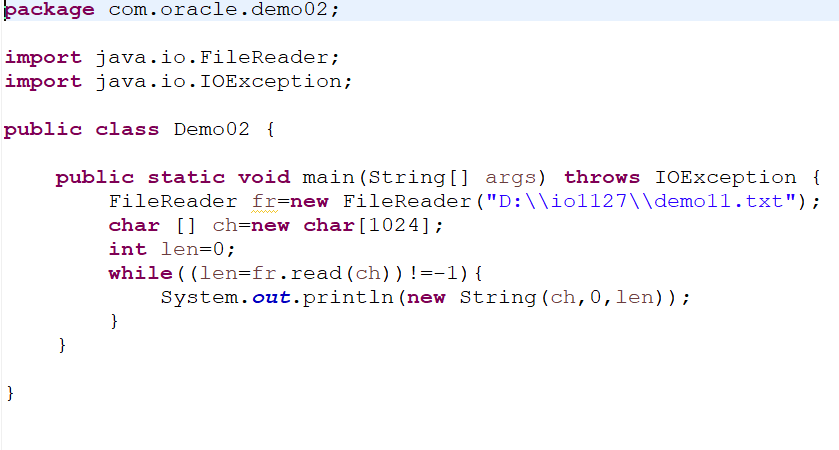
l 使用FileReader读取包含中文的文件时,代码如图所示(单字符)
查阅API,发现有一个Writer类,Writer是写入字符流的抽象类,

查阅FileOutputStream的API,发现FileOutputStream 用于写入诸如图像数据之类的原始字节的流。要写入字符流,请使用 FileWriter。此类的构造方法假定默认字符编码和默认字节缓冲区大小都是可接受的。如图所示
我们可以根据概述方法写出如下代码来实现我们的文件
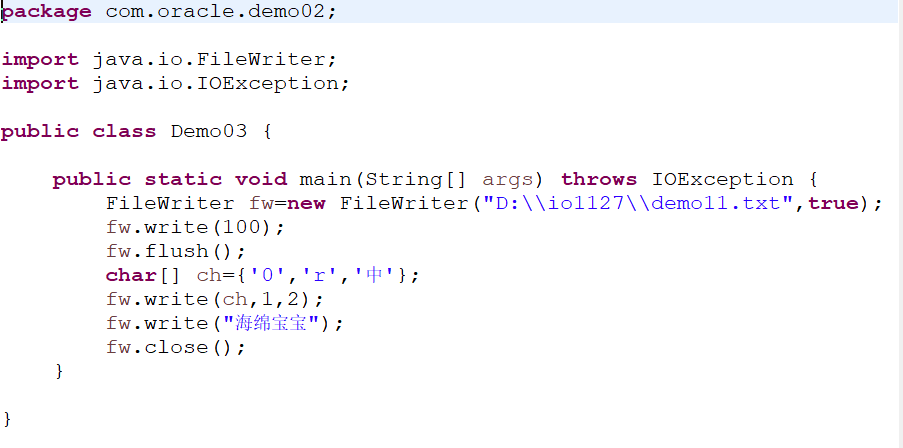
写入字符到文件中,先进行流的刷新,再进行流的关闭,flush和colse的区别是
flush():将流中的缓冲区缓冲的数据刷新到目的地中,刷新后,流还可以继续使用。
close():关闭资源,但在关闭前会将缓冲区中的数据先刷新到目的地,否则丢失数据,然后在关闭流。流不可以使用。如果写入数据多,一定要一边写一边刷新,最后一次可以不刷新,由close完成刷新并关闭。
原文:https://www.cnblogs.com/cactus1/p/14454090.html