本章包含如下内容:
在odoo的模型中,类是字段及业务逻辑的组合。第四章我们了解了添加字段。本节我们将学习如何添加业务逻辑。
我们来学习如何创建一个可由用户点击激活或者由其他业务函数代用的方法。
表现在LibraryBook类上,我们会创建一个改变图书状态的函数。
在前面LibraryBook类的基础上,新增state字段
from odoo import models, fields, api
class LibraryBook(models.Model):
# [...]
state = fields.Selection([
(‘draft‘, ‘Unavailable‘),
(‘available‘, ‘Available‘),
(‘borrowed‘, ‘Borrowed‘),
(‘lost‘, ‘Lost‘)],
‘State‘, default="draft")
创建业务逻辑
@api.model
def is_allowed_transition(self, old_state, new_ state):
allowed = [(‘draft‘, ‘available‘),
(‘available‘, ‘borrowed‘),
(‘borrowed‘, ‘available‘),
(‘available‘, ‘lost‘),
(‘borrowed‘, ‘lost‘),
(‘lost‘, ‘available‘)]
return (old_state, new_state) in allowed
def change_state(self, new_state):
for book in self:
if book.is_allowed_transition(book.state,new_state):
book.state = new_state
else:
continue
def make_available(self):
self.change_state(‘available‘)
def make_borrowed(self):
self.change_state(‘borrowed‘)
def make_lost(self):
self.change_state(‘lost‘)
<form>
...
<button name="make_available" string="Make Available" type="object"/>
<button name="make_borrowed" string="Make Borrowed" type="object"/>
<button name="make_lost" string="Make Lost" type="object"/>
<field name="state" widget="statusbar"/>
...
</form>
本节定义了几个函数。他们都是带有self参数的普通python函数。有几个函数带有了odoo.api装饰器。
小贴士
api装饰器是在odoo9引入的,以支持新旧框架。在odoo10中,不再支持老的api了,但是一写装饰器还可以使用。
当一个新的函数,没有使用装饰器,那么该函数式作用在数据集层面的。在这类函数中,self是任意数量记录的数据集(可以是空数据集),通常通过循环获取每一个数据进行处理。
@api.model装饰器类似,但是他被用作针对模型而不是记录集内容的函数。 他与python的@classmethod装饰器类似。
步骤1,我们创建了监测图书状态状态是否符合要求的函数is_allowed_transition()
步骤2,我们创建了改变图书状态的函数change_state()。
步骤3,我们通过调用change_state()实现图书状态的改变。
步骤4,我们在form视图下创建了几个按钮,用户可通过点击按钮实现改变图书的状态。其中,statusbar的组件(widget)将直观的展示图书的状态。
在函数执行的过程中,有时需要中断执行,因为用户没有权限或者其他的异常情况发生。本节将介绍如何想用户展示错误信息。
当我们通过change_state函数改变图书的状态的时候,若某些转变是不允许的。
from odoo.exceptions import UserError
from odoo.tools.translate import _
def change_state(self, new_state):
for book in self:
if book.is_allowed_transition(book.state, new_ state):
book.state = new_state
else:
msg = _(‘Moving from %s to %s is not allowed‘) % (book.state, new_state)
raise UserError(msg)
在python中,若发生异常,他将逐级调用堆栈,直到他被处理。在odoo中,RPC(remote procedure call远程过程调用)层将对客户端捕获到的异常行为进行处理。
如果异常在odoo.exceptions没有被定义,那么将会报服务器错误(HTTP status500)。UserError将会展示一个错误提醒弹框,并且当前数据库事务将会回滚。
_()定义在odoo.tools.translate的函数。用于标记字符串是可翻译的。
重要提醒
在使用_()时,要确保括号中只有字符串。比如,(‘Warning: could not find %s‘) % value是正确的。(‘Warning: could not find %s‘ % value) 就是错误的。
有时,您正在处理容易出错的代码,这意味着您正在执行的操作可能会生成错误。Odoo将捕获此错误并向用户显示一个回溯信息。如果您不想向用户显示完整的错误日志,您可以捕获错误并返回自定义的异常。在提供的示例中,我们通过try捕获异常并返回错误,而不是显示一个完整的错误日志,Odoo现在将显示一个有意义的消息警告:
def post_to_webservice(self, data):
try:
req = requests.post(‘http://my-test-service.com‘, data=data, timeout=10)
content = req.json()
except IOError:
error_msg = _("Something went wrong during data submission")
raise UserError(error_msg)
return content
在odoo.exceptions中定义了几个异常,这些都继承自except_orm异常类。它们中的大多数只在内部使用,除了以下几种:
当在写odoo模块的时候,我们可以通过self获取当前模型。如果想同时操作几个模型,我们没有办法直接实例化相关模型。我们需要获取相应模型的数据集。
本节将介绍获取odoo中定义的odoo模型的数据集。
class LibraryBook(models.Model):
# ...
def log_all_library_members(self):
# This is an empty recordset of model library. member
library_member_model = self.env[‘library.member‘]
all_members = library_member_model.search([])
print("ALL MEMBERS:", all_members)
return True
2. 在form视图添加按钮
```xml
<button name="log_all_library_members" string="Log Members" type="object"/>
在启动时,Odoo加载所有模块,并组合从Model派生的各种类,还定义或扩展给定的模型。这些类存储在Odoo注册表中,按名称建立索引。任何记录集的env属性,可通过self.env获取,他是定义在odoo.api模块中的Environment类的一个实例。
在odoo开发中,Environment扮演着重要的角色。
你需要知道你创建记录的模型的数据结构,特别是他们的名字和数据类型,以及字段间的约束。
创建library.book.category模型
class BookCategory(models.Model):
_name = ‘library.book.category‘
name = fields.Char(‘Category‘)
description = fields.Text(‘Description‘)
parent_id = fields.Many2one(
‘library.book.category‘,
string=‘Parent Category‘,
ondelete=‘restrict‘,
index=True
)
child_ids = fields.One2many(
‘library.book.category‘, ‘parent_id‘,
string=‘Child Categories‘)
def create_categories(self):
...
categ1 = {
‘name‘: ‘Child category 1‘,
‘description‘: ‘Description for child 1‘
}
categ2 = {
‘name‘: ‘Child category 2‘,
‘description‘: ‘Description for child 2‘
}
parent_category_val = {
‘name‘: ‘Parent category‘,
‘email‘: ‘Description for parent category‘,
‘child_ids‘: [
(0, 0, categ1),
(0, 0, categ2),
]
}
record = self.env[‘library.book.category‘].create(parent_ category_val)
<button name="create_categories" string="Create Categories" type="object"/>
通过create(values)函数创建记录,返回值为长度为1的新创建的记录集。
在values中,需传递正确的类型,odoo中的类型与python中的类型对应如下:
| 元组 | 影响 |
| (0, 0, dict_val) | 关联到主记录的新纪录 |
| (6, 0, id_list) | 创建新旧记录的关联管理。IDs是名为id_list的python列表 |
如果模型中定义了默认值,那么create()将自动处理默认值。
create()函数支持批量创建记录,可在传参时传递列表。
在library.book模型中有个名为date_release的字段。
def change_release_date(self):
self.ensure_one()
self.date_release = fields.Date.today()
<button name="change_release_date" string="Update Date" type="object"/>
首先我们先调用ensuer_one()函数监测传递的self记录集是否只要一条记录。若记录集中数据超过一条,那么调用将停止。这是必要的,因为我们不想更改多个记录的日期。如果希望更新多个值,可以删除ensure_one()并使用记录集上的循环更新属性。
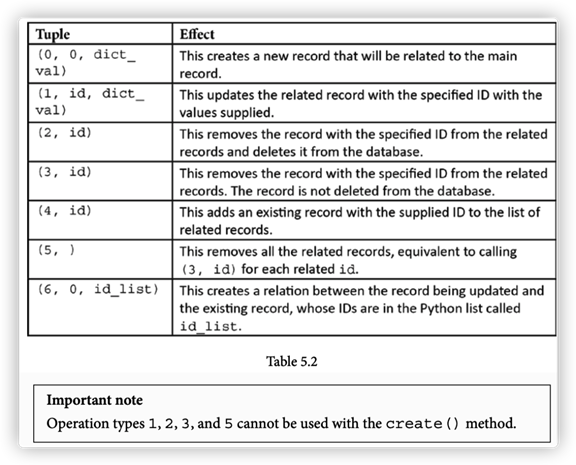
有三种方式实现数据更新
| 元组 | 影响 |
| (0, 0, dict_val) | 将新创建的记录对象关联到主记录上 |
| (1, id, dict_val) | 更新特定(ID)关联记录的值 |
| (2, id) | 移除ID的记录,并从数据库删除ID的记录 |
| (3, id) | 取消记录ID的关联,但并不从数据库删除记录 |
| (4, id) | 添加关联新的已经存在的纪录 |
| (5, ) | 移除所有的记录,类似于对每一个ID调用(3, id) |
| (6, 0, id_list) | 这将在正在更新的记录和现有记录之间创建一个关系,现有记录的id在名为id list的Python列表中。 |
我们将在library.book中创建一个名为find_book(self)的函数
def find_book(self):
...
domain = [
‘|‘,
‘&‘, (‘name‘, ‘ilike‘, ‘Book Name‘),
(‘category_id.name‘, ‘ilike‘, ‘CategoryName‘),
‘&‘, (‘name‘, ‘ilike‘, ‘Book Name 2‘),
(‘category_id.name‘, ‘ilike‘, ‘Category Name2‘)
]
books = self.search(domain)
步骤2,创建搜索条件。我们将在第九章“定义过滤条件”章节详细介绍。
步骤3,调用search()。支持的参数:
重要提醒
search_count(domain)同样可以搜索数量,这是也官方推荐的方法。
有时我们需要搜索另一个模型的数据,因此我们首先要获取该模型的空数据集。然后再调用search()函数。如下
def find_partner(self):
PartnerObj = self.env[‘res.partner‘]
domain = [
‘&‘, (‘name‘, ‘ilike‘, ‘Parth Gajjar‘),
(‘company_id.name‘, ‘=‘, ‘Odoo‘)
]
partner = PartnerObj.search(domain)
在过滤条件中"&"是默认的。
通过search()获取的内容其实是首先要经过权限验证的。并且对于拥有active属性的模型,在active=False时,默认也是不进行搜索的。
关于不添加隐式的active=True条件的方法,请参阅第8章“高级服务器端开发技术”中使用不同的上下文配方调用方法。关于记录级别访问规则的更多信息,请参阅第10章“安全访问”中的“使用记录规则限制记录访问”配方。
如果由于某种原因,你需要通过SQL查询来查找记录id,
确保你使用了self.env[‘record.model‘].search(((“id”,“in”,tuple(ids)))).ids应用了安全规则。这在多公司的Odoo案例中尤其重要,因为记录规则被用来确保公司之间的隔离。
两个以上的数据集
result = recordset1 + recordset2
result = recordset1 | recordset2
3.要找到两个记录集共有的记录,使用以下操作:
result = recordset1 & recordset2
记录集的组合是通过对python运算符的重定义实现的。
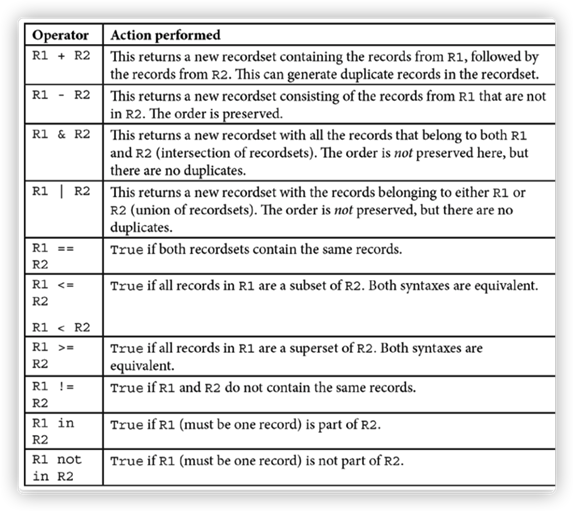
还有 +=, -=, &=, and |=, 运算符,将得出的结果赋值给左侧。这些在更新记录的One2many或Many2many字段时非常有用。
有时,我们已经得到了数据集,但我们只需要其中一部分数据。我们可以迭代数据集并通过判断条件实现,但更为高效的是通过filter()函数实现。
@api.model
def books_with_multiple_authors(self, all_books):
def predicate(book):
if len(book.author_ids) > 1:
return True
return False
return all_books.filter(predicate)
filter()函数创建了一个空数据集,所有的符合过滤条件的记录都会被添加到数据集中。最后将返回新的数据集。
以上可以简写成
@api.model
def books_with_multiple_authors(self, all_books):
return all_books.filter(lambda b: len(b.author_ids) > 1)
其实我们过滤数据集是根据记录中字段的值需符合python意义上的真(非空字符串、非0数字、非空容器等)。所以我们可以简单的过滤如下: all_books.filter(‘category_id‘)。
filter()过滤是在内存中实现的。如果我们需要在一个特别重要的函数中优化性能,那么通过搜索域或者直接原生SQL是不错的选择。
当数据集的长度为1时,那么模型的属性可直接被recordsets使用。
本章节我们将使用mapped()函数遍历数据集关系。
@api.model
def get_author_names(self, books):
return books.mapped(‘author_ids.name‘)
步骤2,我们调用mapped(path)方法获取数据集的字段值。path是以"."分隔的字段名。在path中的每个字段,mapped()都将获取每个字段的的数据集,并接着获取后续字段的值。比如上面,我们获取到一本书的所有的作者(author_ids)数据集,然后在这个新的数据集上获取所有记录中name的值,并以列表的形式返回。若最后一个字段是关联字段的话,那么返回的将是数据集。
mapped()有两个非常有用的属性:
重要提醒(感觉翻译就变味了)
This second property is very useful when you want to perform an operation on all the records that are pointed to by a Many2many field for all the records in self, but you need to ensure that the action is performed only once (even if two records of self share the same target record).
mapped()是在内容中实现的,因此如果需要优化性能,可通过search()及原生SQL实现。
当在通过search()查找数据集的时候,可传递参数以进行排序。但是当我们进行数据集的组合时,有可能导致顺序错乱。
本章节将介绍通过sorted()函数对数据集进行排序。
@api.model
def sort_books_by_date(self, books):
return books.sorted(key=‘release_date‘)
步骤2进行排序,sorted有个可选参数reverse,决定排序的方式。如下
books.sorted(key=‘release_date‘, reverse=True)
sorted()函数将对数据集进行排序。若没有参数,那么模型的_order属性将会被使用。
重要提醒
当使用模型的_order时,排序将通过数据库实现。否则将通过odoo内部实现。两者存在一定的性能不同。
在Odoo中,将应用程序特性划分为不同的模块是一种非常常见的做法。通过这样做,您可以通过安装/卸载应用程序来启用/禁用特性。当你向现有的应用程序添加新功能时,你就需要自定义在原始应用程序中定义的一些方法的行为。有时,你还想向现有的模型添加新字段。这在Odoo中是一项非常简单的任务,也是底层框架最强大的特性之一。
在此菜谱中,我们将看到如何从另一个模块中的方法扩展一个方法的业务逻辑。我们还将从新模块向现有模块添加新字段。
我们创建一个新的模块my_library_return,这个模块依赖于my_library模块。在这个模块中,我们返回所借图书的日期并计算归回日期。
在第4章“应用程序模型”的“使用继承配方向模型添加特性”中,我们看到了如何向现有模型添加字段。在这个模块中,扩展这个库。图书模型如下:
class LibraryBook(models.Model):
_inherit = ‘library.book‘
date_return = fields.Date(‘Date to return‘)
扩展library.book.category模型
class LibraryBookCategory(models.Model):
_inherit = ‘library.book.category‘
max_borrow_days = fields.Integer(
‘Maximum borrow days‘,help="For how many days book can be borrowed",default=10)
def make_borrowed(self):
day_to_borrow = self.category_id.max_borrow_days or 10
self.date_return = fields.Date.today() + timedelta(days=day_to_borrow)
return super(LibraryBook, self).make_borrowed()
def make_available(self):
self.date_return = False
return super(LibraryBook, self).make_available()
在Odoo模型的情况下,父类不是您从Python类定义中所期望的那样。框架为我们的记录集动态地生成了一个类层次结构,父类是我们依赖的模块中的模型定义。因此,对super()的调用带回了library的实现。从my_module书。在这个实现中,make_borrowed()将book的状态更改为Borrowed。因此,调用super()将调用父方法,并将图书状态设置为Borrowed。
一般我们在重写函数后会去调用父函数,否则父函数将不会被执行。
重写函数中,在调用父函数前后我们可以:
和上一些内容类似,需要注意的如下:
class MyModel(models.Model):
def write(self, values):
sup = super(MyModel, self).write(values)
if self.env.context.get(‘MyModelLoopBreaker‘):
return
self = self.with_context(MyModelLoopBreaker=True)
self.compute_things() # can cause calls to writes
return sup
本章节将重新定义name_search,以按书名、作者或书号在Many2one小部件中搜索一本书。
class LibraryBook(models.Model):
_name = ‘library.book‘
name = fields.Char(‘Title‘)
isbn = fields.Char(‘ISBN‘)
author_ids = fields.Many2many(‘res.partner‘, ‘Authors‘)
def name_get(self):
result = []
for book in self:
authors = book.author_ids.mapped(‘name‘)
name = ‘%s (%s)‘ % (book.name, ‘, ‘.join(authors))
result.append((book.id, name))
return result
当使用这个模型时,Many2one小部件中的一本书将显示为书名(Author1, Author2…)。用户希望能够输入作者的名字,并找到根据这个名字过滤的列表,但是这不会起作用,因为name_search的默认实现只使用的_rec_name属性引用的属性。我们还希望允许按ISBN号进行过滤。
@api.model
def _name_search(self, name=‘‘, args=None, operator=‘ilike‘,limit=100, name_get_uid=None):
args = [] if args is None else args.copy()
if not(name == ‘‘ and operator == ‘ilike‘):
args += [‘|‘, ‘|‘,(‘name‘, operator, name),(‘isbn‘, operator, name),(‘author_ids.name‘, operator, name)]
return super(LibraryBook, self)._name_search(name=name, args=args, operator=operator,limit=limit, name_get_uid=name_get_uid)
old_edition = fields.Many2one(‘library.book‘, string=‘Old Edition‘)
<field name="old_edition" />
name_search()默认的实现方式只是调用了_name_search()函数。_name_search()有一个额外的参数, name_get_uid, 是搜索主题的用户,可以是sudo()或者其他的用户。
我们一般只是将参数进行传递而已,并不做修改:
在前面的章节中,我们看到了如何从数据库中搜索和获取数据。但有时,您希望通过汇总记录得到结果,例如上月销售订单的平均成本。通常,我们在SQL查询中使用group by和aggregate函数来得到这样的结果。幸运的是,在Odoo中,我们有read_group()方法。在本食谱中,您将学习如何使用read_group()方法来获取聚合结果。
library.book模型
class LibraryBook(models.Model):
_name = ‘library.book‘
name = fields.Char(‘Title‘, required=True)
date_release = fields.Date(‘Release Date‘)
pages = fields.Integer(‘Number of Pages‘)
cost_price = fields.Float(‘Book Cost‘)
category_id = fields.Many2one(‘library.book.category‘)
author_ids = fields.Many2many(‘res.partner‘, string=‘Authors‘)
添加library.book.category模型。简单起见,直接添加在library_book.py文件中。
class BookCategory(models.Model):
_name = ‘library.book.category‘
name = fields.Char(‘Category‘)
description = fields.Text(‘Description‘)
我们将计算每个品类图书的平均值。
要提取分组的结果,我们将向library.book模型添加_get_average_cost方法。它将使用read_group()方法获取组中的数据:
@api.model
def _get_average_cost(self):
grouped_result = self.read_group(
[(‘cost_price‘, "!=", False)], # Domain
[‘category_id‘, ‘cost_price:avg‘], # Fields to access
[‘category_id‘] # group_by
)
return grouped_result
read_group()函数其实是通过SQL的groupby和aggregate函数实现的。常用的参数如下:
read_group()支持一些可选参数,如下:
性能提醒
read_group()性能优于获取记录后再进行计算的方式。
原文:https://www.cnblogs.com/xushuotec/p/14460115.html