引用计数(Reference Counting)算法是每个对象计算指向它的指针的数量,当有一个指针指向自己时计数值加1;当删除一个指向自己的指针时,计数值减1,如果计数值减为0,说明已经不存在指向该对象的指针了,所以它可以被安全的销毁了。
需要单独的字段存储计数器,增加了存储空间的开销;
每次赋值都需要更新计数器,增加了时间开销;
垃圾对象便于辨识,只要计数器为0,就可作为垃圾回收;
及时回收垃圾,没有延迟性;
不能解决循环引用的问题;
例如: Lua就采用了mark-sweep的垃圾回收机制
标记-清除(Mark-Sweep)算法依赖于对所有存活对象进行一次全局遍历来确定哪些对象可以回收,遍历的过程从根出发,找到所有可达对象,除此之外,其它不可达的对象就是垃圾对象,可被回收。整个过程分为两个阶段:标记阶段找到所有存活对象;清除阶段清除所有垃圾对象。
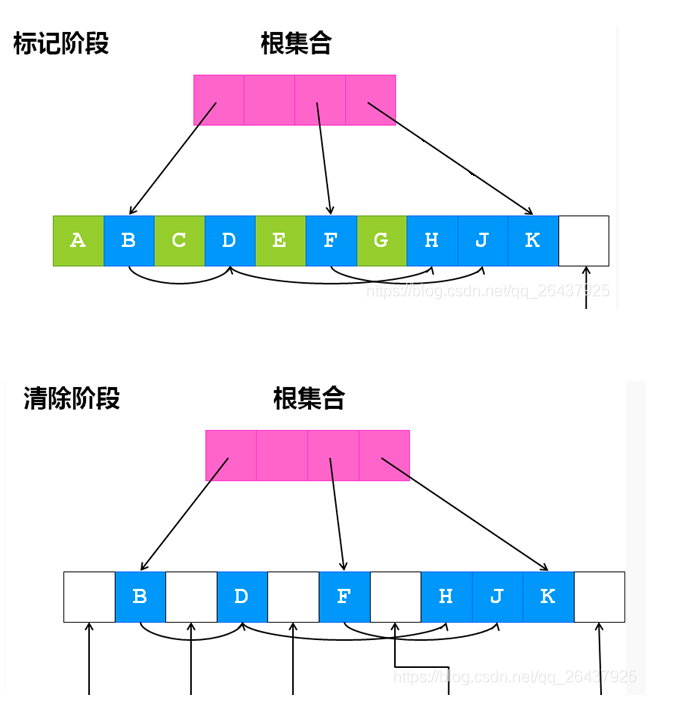
相比较引用计数算法,标记-清除算法可以非常自然的处理环形引用问题,
另外在创建对象和销毁对象时时少了操作引用计数值的开销
标记-清除算法是一种“停止-启动”算法,在垃圾回收器运行过程中,应用程序必须暂时停止
标记-清除算法在标记阶段需要遍历所有的存活对象,会造成一定的开销
在清除阶段,清除垃圾对象后会造成大量的内存碎片。
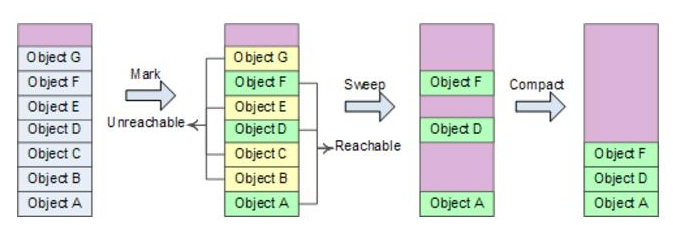
整个过程可以描述为
标记-压缩算法最大的难点在于如何选择所使用的压缩算法,如果压缩算法选择不好,将会导致极大的程序性能问题,如导致Cache命中率低等。一般来说,根据压缩后对象的位置不同,压缩算法可以分为以下三种:
任意:移动对象时不考虑它们原来的次序,也不考虑它们之间是否有互相引用的关系。
线性:尽可能的将原来的对象和它所指向的对象放在相邻位置上,这样可以达到更好的空间局部性。
滑动:将对象“滑动”到堆的一端,把存活对象之间的自由单元“挤出去”,从而维持了分配时的原始次序。
节点拷贝算法是把整个堆分成两个半区(From,To), GC的过程其实就是把存活对象从一个半区From拷贝到另外一个半区To的过程,而在下一次回收时,两个半区再互换角色。在移动结束后,再更新对象的指针引用
参考
http://blog.csdn.net/sinat_36246371/article/details/53002209
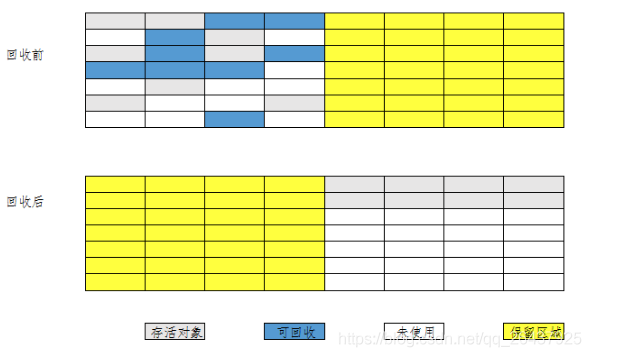
简单,高效,空间换时间。
分代收集算法是目前大部分JVM的垃圾收集器采用的算法。它的核心思想是根据对象存活的生命周期将内存划分为若干个不同的区域。一般情况下将堆区划分为老年代(Tenured Generation)和新生代(Young Generation),老年代的特点是每次垃圾收集时只有少量对象需要被回收,而新生代的特点是每次垃圾回收时都有大量的对象需要被回收,那么就可以根据不同代的特点采取最适合的收集算法。
目前大部分垃圾收集器对于新生代都采取Copying算法,因为新生代中每次垃圾回收都要回收大部分对象,也就是说需要复制的操作次数较少,但是实际中并不是按照1:1的比例来划分新生代的空间的,一般来说是将新生代划分为一块较大的Eden空间和两块较小的Survivor空间,每次使用Eden空间和其中的一块Survivor空间,当进行回收时,将Eden和Survivor中还存活的对象复制到另一块Survivor空间中,然后清理掉Eden和刚才使用过的Survivor空间。
而由于老年代的特点是每次回收都只回收少量对象,一般使用的是Mark-Compact算法。
注意,在堆区之外还有一个代就是永久代(Permanet Generation),它用来存储class类、常量、方法描述等。对永久代的回收主要回收两部分内容:废弃常量和无用的类。
原文:https://doctording.blog.csdn.net/article/details/53728388?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.control&dist_request_id=6b460756-003e-4553-a15f-de282251b1c3&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.control
原文:https://www.cnblogs.com/lshan/p/14462946.html