优化分析
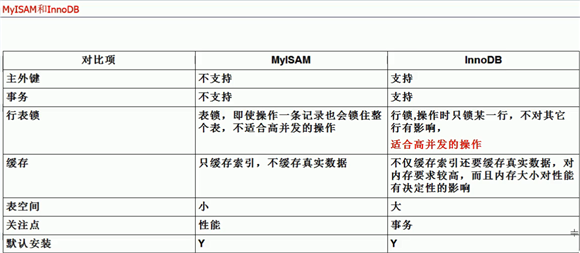
一、存储引擎的对比
二、性能下降SQL慢 、执行时间长、等待时间长
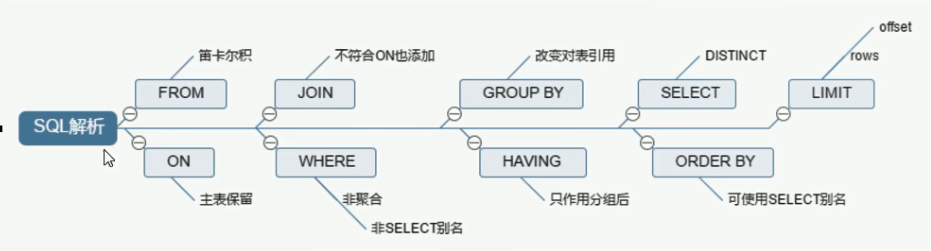
三、常见的Join查询
#sql语句的手写顺序 SELECT DISTINCT <select_list> FROM <left_table> <join_type> JOIN <right_table> ON <join_condition> WHERE <where_condition> GROUP BY <group_by_list> HAVING <having_condition> ORDER BY <order_by_condition> LIMIT <limit_number>
机读顺序:
#机读顺序 FROM <left_table> ON <join_condition> <join_type> JOIN <right_table> WHERE <where_condition> GROUP BY <group_by_list> HAVING <having_condition> SELECT DISTINCT <select_list> ORDER BY <order_by_condition> LIMIT <limit_number>
总结:https://database.51cto.com/art/201911/605471.htm
四、七种Join如下所示:
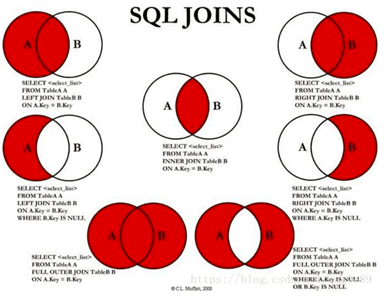
注意:mysql不支持全外连接,但是可以使用union(联合+去重)把左外连接和右外连接联合起来。
五、索引
定义:索引(Index)是帮助MySQL高效获取数据的数据结构 。索引的目的在于提高查找效率,类比字典。除了数据本身之外,数据库还维护一个满足特定查找算法的数据结构,这些数据结构以某种方式指向数据,这样就可以在这些数据结构的基础上实现高效的查找算法,这种数据结构就是索引(排序好的快速查找的数据结构)。
一般来说索引本身很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储在磁盘上。
索引的优势:
索引的劣势:
索引的分类:
mysql索引结构:
哪些情况需要创建索引:
性能分析:
1、Explain:使用EXPLAIN关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的,分析你的查询语句或是表结构的性能瓶颈。
2、使用方法:
EXPLAIN SELECT * FROM <table>;
3、explain的作用:
通过EXPALIN,我们可以分析出以下结果:
执行计划各个字段的含义
![]()
1. id: select查询的序列号,表示查询中执行select子句或操作表的顺序
一、id会出现三种结果:
1.id相同,执行顺序由上至下
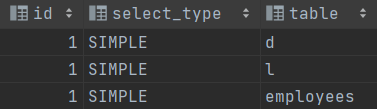
有上图可见,操作表的id号均为1,所以操作顺序为
d->l->employees
2. id不同时,id值越大优先级越高,越先被执行
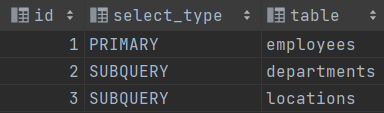
如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行
3. id既有相同的,又有不同的
说明:id如果相同,可以认为是一组,从上往下顺序执行;在所有组中,id值越大,优先级越高,越先执行
注意:执行过程中,衍生的表用derived表示。
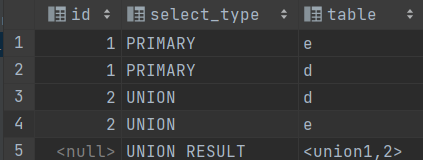
二、查询类型select_type
作用:用来表示查询的类型,主要用于区别普通查询、联合查询、子查询等复杂查询
eg.
explain select * from employees e left join departments d on e.department_id = d.department_id union select * from employees e right join departments d on e.department_id = d.department_id;
三、table
table就是操作表
四、type
type表示使用了那种类型的查询,分为以下几种:
查询效率从高到低依次为:
system > const > eq_ref > ref > range > index > all
一般来说,需要保证查询至少达到range级别,最好能达到ref。
select * from table where id(主键) = XX;
select * from table where id between 30 and 60;
select employee_id from employees;
select * from employees;
五、ref
将列与索引进行比较,主要用来表示表的连接条件(即哪些列或常量被用于查找索引列上的值)
#案例:查找部门编号为1700的员工信息 explain select * from employees e, departments d where e.department_id = d.department_id and d.location_id = 1700;

分析结果可以看出:d表的location_id索引列匹配了一个常量(1700);e表的department_id索引列匹配了d表的department_id。他们之间的匹配关系我们可以清楚地从ref中查看到
六、rows
根据表的统计信息和索引的选用情况,大致估算出找到所需记录所需要读取的行数,rows列中的值,越小越好。
七、Extra
explain select last_name, department_id from employees order by salary;
覆盖索引,也叫索引覆盖:select的数据列只用从索引中就能够取得,不必从数据表中读取。mysql可以利用索引返回select列表的字段,即查询的列要被所建的索引覆盖
explain select employee_id from employees;
1,SIMPLE,employees,null,index,,dept_id_fk,5,null,107,100,Using index
八、索引优化
索引优化的总结
九、索引失效
十、查询优化
# 小表驱动大表 use myemployees; # 员工表有107条数据 select count(*) from employees; # 部门表有27条数据 select count(*) from departments; # 案例1. # 88ms select * from employees e where e.department_id in ( select d.department_id from departments d ); # 107ms select * from employees e where exists(select 1 from departments d where d.department_id = e.department_id); # 当d表的数据小于e表时,采用in要由于exists # in后面跟的是小表,exists后面跟的是大表(in后小,exists大) # select ...from table where exists(subquery)的理解:将主查询中的数据放入子查询中做条件验证,根据验证的结果(true/false)来决定主查询的数据是否保留
原则:尽量使用Index方式排序,避免使用FileSort方式排序。链接一
filesort的原理,以及两种算法。链接二
原文:https://www.cnblogs.com/xiazhenbin/p/14442387.html