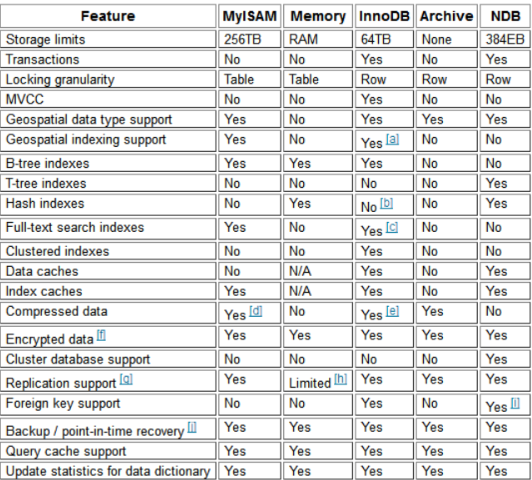
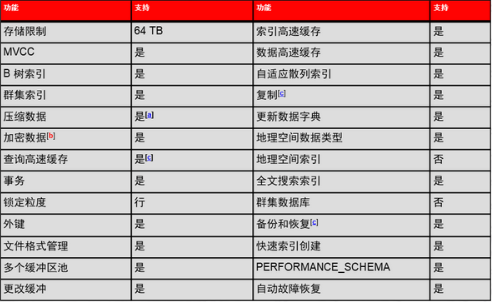
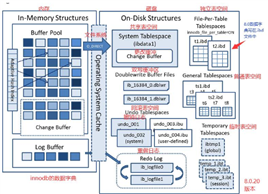
存储引擎MySQL中的“文件系统”
mysql
MariaDB [(none)]> show engines; 可以查看当前My1SAM和InnoDB信息
+--------------------+---------+----------------------------------------------------------------------------+--------------+------+------------+
| Engine | Support | Comment | Transactions | XA | Savepoints |
+--------------------+---------+----------------------------------------------------------------------------+--------------+------+------------+
| MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO | NO | NO |
| MRG_MYISAM | YES | Collection of identical MyISAM tables | NO | NO | NO |
| CSV | YES | CSV storage engine | NO | NO | NO |
| BLACKHOLE | YES | /dev/null storage engine (anything you write to it disappears) | NO | NO | NO |
| MyISAM | YES | MyISAM storage engine | NO | NO | NO |
| InnoDB | DEFAULT | Percona-XtraDB, Supports transactions, row-level locking, and foreign keys | YES
| MyISAM | InnoDB |
|---|---|
| 不支持事务 | 支持事务,适合处理大量短期事务 |
| 表级锁,当表锁定时,其他人都无法使用,影响并发性范围大 | 行级锁 |
| 读写相互阻塞,写入不能读,读时不能写 | 读写阻塞与事务隔离级别相关 |
| 只缓存索引 | 可缓存数据和索引 |
| 不支持外键约束 | 支持外键 |
| 不支持聚簇索引 | 支持聚簇索引 |
| 读取数据较快,占用资源较少 | MySQL5.5后支持全文索引 |
| 不支持MVCC(多版本并发控制机制)高并发 | 支持MVCC高并发 |
| 崩溃恢复性差 | 崩溃恢复性好 |
| MySQL5.5.5前默认的数据库引擎 | MySQL5.5.5后默认的数据库引擎 |
| 适用只读(或者写较少)、表较小(可以接受长时间进行修复操作)的场景 | 系统表空间文件:ibddata1, ibddata2, ... |
| tb_name.frm 表结构,tb_name.MYD 数据行,tb_name.MYI 索引 | 每表两个数据库文件:tb_name.frm 每表表结构,tb_name.ibd 数据行和索引 |
彩蛋:InnoDB 核心特性有哪些? InnoDB和MyISAM区别有哪些? InnoDB支持事务、MVCC、聚簇索引、外键、缓冲区、AHI、CR、DW,MyISAM不支持。 InnoDB支持行级锁,MyISAM支持表级锁。 InnoDB支持热备(业务正常运行,影响低),MyISAM支持温备份(锁表备份)。 InnoDB支持CR(自动故障恢复),宕机自动故障恢复,数据安全和一致性可以得到保证。MyISAM不支持,宕机可能丢失当前修改。
mysql> show engines;
MRG_MYISAM
CSV
MyISAM
BLACKHOLE
PERFORMANCE_SCHEMA
InnoDB
ARCHIVE
MEMORY
FEDERATED
不支持事务
表级锁定,当表锁定时,其他人都无法使用,影响并发性范围大
读写相互阻塞,写入不能读,读时不能写
只缓存索引
不支持外键约束
不支持聚簇索引
读取数据较快,占用资源较少
不支持MVCC(多版本并发控制机制)高并发
崩溃恢复性较差
MySQL5.5.5前默认的数据库引擎<br> 数据库有三个文件,有frm、MYD、MYI后缀的文件
只读(或者写较少)、表较小(可以接受长时间进行修复操作)
tbl_name.frm 表格式定义
tbl_name.MYD 数据文件
tbl_name.MYI 索引文件
行级锁
支持事务,适合处理大量短期事务
读写阻塞与事务隔离级别相关
可缓存数据和索引
支持聚簇索引
崩溃恢复性更好
支持MVCC高并发
从MySQL5.5后支持全文索引
从MySQL5.5.5开始为默认的数据库引擎<br> 数据库有两个文件frm和idb后缀的文件
InnoDB支持更好的特性:Percona-XtraDB, Supports transactions(支持事务), row-level locking(行级锁), and foreign keys(支持外键)
1.由一系列动作组合起来的一个完整的整体,需要将所有的动作全部做掉,要么全不做,具有原子性。
2.(rollback)支持回滚、撤销之前未做完的事务。
所有InnoDB表的数据和索引放置于同一个表空间中
表空间文件:datadir定义的目录下
数据文件:ibddata1, ibddata2, ...
每个表单独使用一个表空间存储表的数据和索引
启用:innodb_file_per_table=ON
参看:https://mariadb.com/kb/en/library/xtradbinnodb-server-system-variables/#innodb_file_per_table ON (>= MariaDB 5.5) 两类文件放在数据库独立目录中
数据文件(存储数据和索引):tb_name.ibd
表格式定义:tb_name.frm
其它存储引擎
Performance_Schema:Performance_Schema数据库使用
Memory :将所有数据存储在RAM中,以便在需要快速查找参考和其他类似数据的环境中进行快速访问。适用存放临时数据。引擎以前被称为HEAP引擎
MRG_MyISAM:使MySQL DBA或开发人员能够对一系列相同的MyISAM表进行逻辑分组,并将它们作为一个对象引用。适用于VLDB(Very Large Data Base)环境,如数据仓库
Archive :为存储和检索大量很少参考的存档或安全审核信息,只支持SELECT和INSERT操作;支持行级锁和专用缓存区
Federated联合:用于访问其它远程MySQL服务器一个代理,它通过创建一个到远程MySQL服务器的客户端连接,并将查询传输到远程服务器执行,而后完成数据存取,提供链接单独MySQL服务器的能力,以便从多个物理服务器创建一个逻辑数据库。非常适合分布式或数据集市环境
BDB:可替代InnoDB的事务引擎,支持COMMIT、ROLLBACK和其他事务特性
Cluster/NDB:MySQL的簇式数据库引擎,尤其适合于具有高性能查找要求的应用程序,这类查找需求还要求具有最高的正常工作时间和可用性
CSV:CSV存储引擎使用逗号分隔值格式将数据存储在文本文件中。可以使用CSV引擎以CSV格式导入和导出其他软件和应用程序之间的数据交换
BLACKHOLE :黑洞存储引擎接受但不存储数据,检索总是返回一个空集。该功能可用于分布式数据库设计,数据自动复制,但不是本地存储
example:“stub”引擎,它什么都不做。可以使用此引擎创建表,但不能将数据存储在其中或从中检索。目的是作为例子来说明如何开始编写新的存储引擎
MariaDB支持的其它存储引擎:
OQGraph
SphinxSE
TokuDB
Cassandra
CONNECT
SQUENCE
查看mysql支持的存储引擎
show engines;
查看当前默认的存储引擎
show variables like ‘%storage_engine%‘;
设置默认的存储引擎
vim /etc/my.conf
[mysqld]
default_storage_engine= InnoDB
查看库中所有表使用的存储引擎
show table status from db_name;
查看库中指定表的存储引擎
show table status like ‘ tb_name ‘;
show create table tb_name;
设置表的存储引擎:
CREATE TABLE tb_name(... ) ENGINE=InnoDB;
ALTER TABLE tb_name ENGINE=InnoDB;
InnoDB、MyISAM、CSV、MEMORY
- PerconaDB:默认是XtraDB
- MariaDB:默认是InnoDB
- 其他引擎:TokuDB、MyRocks、Rocksdb
- 特点:压缩比15倍以上,插入数据性能快3-5倍
适应场景:
例如Zabbix监控类的平台、归档库、历史数据存储业务
InnoDB存储引擎特性
MVCC : 多版本并发控制
聚簇索引 : 用来组织存储数据和优化查询,IOT。
支持事务 : 数据安全保证
支持行级锁 : 控制并发
外键
多缓冲区支持
自适应Hash索引: AHI
复制中支持高级特性。
备份恢复: 支持热备。
自动故障恢复:CR Crash Recovery
双写机制:DWB Double Write Buffer
某期学员负责: 运维 + MySQL 工作
环境: zabbix 3.2+centos7.3+mariaDB 5.5 InnoDB引擎,zabbix系统 监控了2000多个节点服务
现象:每隔一段时间zabbix卡的要死,每隔3-4个月,都要重新搭建一遍zabbix,存储空间经常爆满.
问题
zabbix 版本过低。
数据库版本
zabbix数据库500G,存在一个文件里ibdata1,手工删除1个月之前的数据,空间不释放。
优化建议:
数据库版本升级到percona 5.7+ 版本 mariadb 10.x+,zabbix升级更高版本
存储引擎改为tokudb
监控数据按月份进行切割(二次开发:zabbix 数据保留机制功能重写,数据库分表)
关闭binlog和双1
参数调整....
优化结果:
监控状态良好
参考: https://www.jianshu.com/p/898d2e4bd3a7
为什么选用tokudb?
MariaDB 10.0.9原生态支持TokuDB,另外经过测试环境,5.7要比5.5 版本性能 高 2-3倍
TokuDB:insert数据比Innodb快的多,数据压缩比要Innodb高
监控数据按月份进行切割,为了能够truncate每个分区表,立即释放空间
关闭binlog ----->减少无关日志的记录.
参数调整...----->安全性参数关闭,提高性能.
扩展:部署 zabbix新版+ 新版本 tokudb VS 部署 zabbix + 低版本mariadb Tokudb特性:
TokuDB独有的其他功能包括:
高达25倍的数据压缩
快速插入
通过无读复制消除从机延迟
热架构更改
热索引创建 - TokuDB表支持插入、删除和查询,而索引添加到该表时没有停机时间
热列添加、删除、扩展和重命名 — 当 alter table 添加、删除、扩展或重命名列时,TokuDB表支持不停机插入、删除和查询
在线备份
参考内容: https://www.jianshu.com/p/898d2e4bd3a7 https://mariadb.com/kb/en/installing-tokudb/ https://www.percona.com/doc/percona-server/5.7/tokudb/tokudb_installation.html
Additional features unique to TokuDB include:
Up to 25x Data Compression
Fast Inserts
Eliminates Slave Lag with Read Free Replication
Hot Schema Changes
Hot Index Creation - TokuDB tables support insertions, deletions and queries with no down time while indexes are being added to that table
Hot column addition, deletion, expansion, and rename - TokuDB tables support insertions, deletions and queries without down-time when an alter table adds, deletes, expands, or renames columns
On-line Backup
环境: centos 5.8 ,MySQL 5.0版本,MyISAM存储引擎,网站业务(LNMP),数据量50G左右 现象问题: 业务压力大的时候,非常卡;经历过宕机,会有部分数据丢失.
问题分析:
1.MyISAM存储引擎表级锁,在高并发时,会有很高锁等待
2.MyISAM存储引擎不支持事务,在断电时,会有可能丢失数据
职责
1.监控锁的情况:有很多的表锁等待
2.存储引擎查看:所有表默认是MyISAM
解决方案:
升级MySQL 5.6.1x版本
升级迁移所有表到新环境,调整存储引擎为InnoDB
开启双1安全参数
重构主从
查看存储引擎 查询支持的存储引擎
mysql> show engines;
查询、设置默认存储引擎
-- 会话级别(仅影响当前会话)
set default_storage_engine=myisam;
-- 全局级别(仅影响新会话)重启失效
set global default_storage_engine=myisam;
-- 写入配置文件,重启永久生效
vim /etc/my.cnf
[mysqld]
default_storage_engine=InnoDB
存储引擎是作用在表上的,也就意味着,不同的表可以有不同的存储引擎类型。
(1) 查看某张表的存储引擎
SHOW create table 表名; use 表名; SHOW TABLE STATUS LIKE ‘countrylanguage‘\G
(2) 查询系统中所有业务表的存储引擎信息
mysql> select table_schema,table_name ,engine from information_schema.tables where table_schema not in (‘sys‘,‘mysql‘,‘information_schema‘,‘performance_schema‘);
(3)创建表设定存储引擎
create table 表名 (id int) engine=innodb charset=utf8mb4;
(4)修改已有表的存储引擎
alter table 库名.表名 engine=innodb;
项目:将所有的非InnoDB引擎的表查询出来,批量修改为InnoDB
查询:
SELECT table_schema, table_name, ENGINE FROM information_schema.tables WHERE table_schema NOT IN (‘sys‘,‘mysql‘,‘information_schema‘,‘performance_schema‘) AND ENGINE !=‘innodb‘;
开启导出文件功能
vim /etc/my.cnf [mysqld] secure-file-priv=/tmp
构建批量修改语句:
SELECT CONCAT("alter table ",table_schema,".",table_name," engine=innodb;")
FROM information_schema.tables
WHERE table_schema NOT IN (‘sys‘,‘mysql‘,‘information_schema‘,‘performance_schema‘)
AND ENGINE !=‘innodb‘ INTO OUTFILE ‘/tmp/a.sql‘;
执行批量修改语句:
source /tmp/a.sql
ibdata1:系统数据字典信息(统计信息),UNDO表空间等数据 ib_logfile0 ~ ib_logfile1: REDO日志文件,事务日志文件。 ibtmp1: 临时表空间磁盘位置,存储临时表 frm:存储表的列信息 ibd:表的数据行和索引
| myisam | InnoDB |
|---|---|
| .frm 数据字典 | .ibd 数据行和索引 |
| .myd 数据行 | .frm 单表数据字典 |
| .myi 索引 | ibdata1 |
介绍:表空间的概念源于Oracle数据库。最初的目的是为了能够很好的做存储的扩容。
共享(系统)表空间
存储方式
ibdata1~ibdataN, 5.5版本默认的表空间类型.
ibdata1共享表空间在各个版本的变化
5.5版本:
系统相关:(全局)数据字典信息(表基本结构信息、状态、系统参数、属性..)、UNDO回滚日志(记录撤销操作)、Double Write Buffer信息、临时表信息、change buffer
用户数据:表数据行、表的索引数据
5.6版本:
共享表空间只存储于系统数据,把用户数据独立了,独立表空间管理。
系统相关:(全局)数据字典信息、UNDO回滚信息、Double Write信息、临时表信息、change buffer
5.7版本:
在5.6基础上,把临时表独立出来,UNDO也可以设定为独立
系统相关:(全局)数据字典信息、UNDO回滚信息、Double Write信息、change buffer
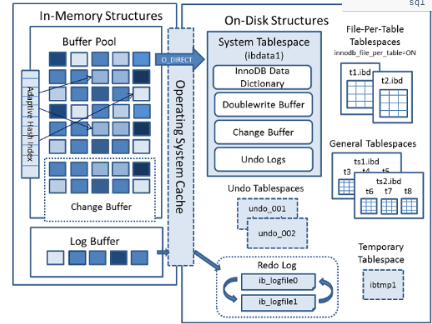
8.0.11~8.0.19版本:
在5.7的基础上将UNDO回滚信息默认独立,数据字典不再集中存储了。
系统相关:Double Write信息、change buffer
8.0.20版本:
https://dev.mysql.com/doc/refman/5.7/en/innodb-architecture.html
在之前版本基础上,独立 Double Write信息 系统相关:change buffer
总结:
对于InnoDB表来讲,例如 city表
city.ibd
city.frm
ibdata1
只是通过cp备份ibd和frm文件无法实现,数据表的恢复
innoda_file_per_table=1,1代表独立表空间,5.6版默认模式;0代表共享表空间,5.6之前的默认模式
5.6版之前表空间没有独立出来,存放在ibdata1文件中。设为1后创建的表会在data目录中生成表名.ibd文件,
设置为0后创建的表不会生成该文件,会把.ibd中的内容存放到ibdata1文件中。
# 存储引擎配置:
default_storage_engine=innodb(5.6的默认引擎)
# 配置共享表空间文件个数和大小(即ibdata1文件,该文件成为共享表空间):
参考:https://www.cnblogs.com/quzq/p/12833135.html
innodb_data_file_path=ibdata1:512M:ibdata2:512M:autoextend
该配置通常在初始化之前配好,会生成两个文件
# 双一标准的其中一个(默认是1)
innodb_flush_log_at_trx_commit=1,用于控制redo log buffer中数据写入磁盘redo log文件的。
值1代表什么呢?(redo log buffer,data buffer poll, undo log buffer都是存在于mysql内存中的)
mysql启动后会向操作系统申请专用的内存空间,配置为1代表在commit命令后会立即把redo log buffer
递交到操作系统内存中,然后由操作系统再立即写入到磁盘的redo log文件中。
值0代表每秒执行一次把redo log buffer递交到操作系统内存,操作系统内存也每秒往redo log中写入一次。
因为是每秒一次,如果在1秒内发生大量的事务递交,突然宕机,会造成1秒间隔内发生的事务数据丢失
值2代表每次commit后立即把redo log buffer数据递交到操作系统内存,然后操作系统每秒往redo log中写入一次
缺点和0一样,只不过能好一点,如果只是mysql服务宕机的话,提交到操作系统内存的事务还不会丢失。
补充:无论哪个值,redo log buffer递交到操作系统内存的日志都会包含所有,无论该事务是否commit.
# 双一表中的另一个
sync_binlog=1 每次事务递交都立即把二进制日志刷写到磁盘。
双一标准都是用来控制mysql内存数据刷写到磁盘的频率,一个用来控制redo log, 一个用来控制二进制日志的
二进制日志相关参考:https://www.cnblogs.com/quzq/p/12866410.html
# 控制mysql内存中logs到磁盘的过程
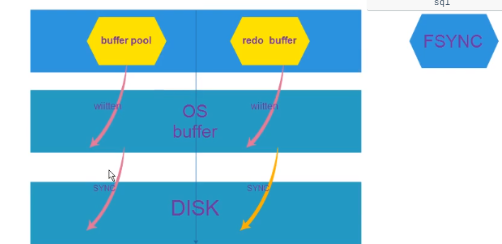
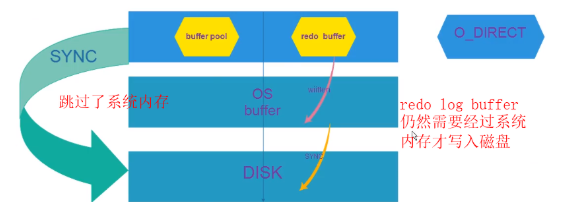
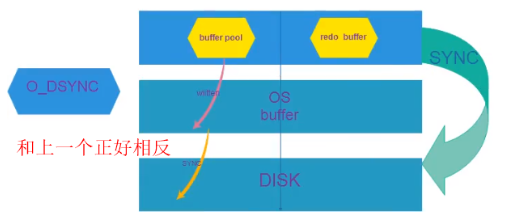
innodb_flush_method=o_direct或fsync或o_dsync, 控制的是redo log buffer和data buffer pool,过程如下:
默认使用的是fsync模式,建议使用o_direct模式
#结合上两个参数给出个建议配置如下:
1.最高安全模式:
innodb_flush_log_at_trx_commit=1
innodb_flush_method=o_direct
2.最高性能模式(安全不是特别重要场景):
innodb_flush_log_at_trx_commit=0
innodb_flush_method=fsync
# 三个和redo日志设置有关的参数:
1.innodb_log_buffer_size=16777216, 设置redo log buffer内存区的大小
2.innodb_log_file_size=50331648, 设置redo log的两个文件大小
3.innodb_log_files_in_group=3,控制redo log的文件数,默认是0和1两个文件
# 脏页刷写策略:
innodb_max_dirty_pages_pct=75, 75为百分比,控制data buffer pool中脏页数据占比达到75%时自动触发CKPT
和WAL机制把data buffer pool中的信息刷写到ibd文件中,当然日志也是优先于数据写入到redo log中的。
补充:哪些场景会触发脏页数据写入ibd文件(CKPT)呢?
CSR机制。 参考:https://www.cnblogs.com/quzq/p/12839958.html
redo文件满了。通常redo log中的信息当脏页数据写回ibd后,redo log中的日志就没用了,可以被覆盖写掉。
mysql> select @@innodb_data_file_path;
+-------------------------+
| @@innodb_data_file_path |
+-------------------------+
| ibdata1:12M:autoextend |
+-------------------------+
1 row in set (0.00 sec)
mysql> select @@innodb_autoextend_increment;
+-------------------------------+
| @@innodb_autoextend_increment |
+-------------------------------+
| 64 |
+-------------------------------+
1 row in set (0.00 sec)
参数用途:ibdata1文件,默认初始大小12M,不够用会自动扩展,默认每次扩展64M扩容
① 初始化后设置共享表空间,重启生效。
vim /etc/my.cnf
[mysqld]
innodb_data_file_path=ibdata1:12M;ibdata2:64M;ibdata3:64M:autoextend
注意:ibdata1必须和当前文件时间大小一致
错误处理:
ibdata1设置值和当前文件实际大小不一致,重启数据库报错,查看日志文件
tail -10 /data/3306/data/db01.err | grep ERROR
... ...
[ERROR] InnoDB: The innodb_system data file ‘./ibdata1‘ is of a different size 4864 pages (rounded down to MB) than the 768 pages specified in the .cnf file!
... ...
实际大小:4864*16K/1024=76M
my.cnf文件设置大小:768*16K/1024=12M
查看ibdata1实际大小
[root@db01 ~]# ls -lh /data/3306/data/ibdata1
-rw-r----- 1 mysql mysql 76M May 6 17:11 ibdata1
② 初始化前设置共享表空间(生产建议)
5.7 中建议:设置共享表空间2-3个,大小建议1G或者4G,最后一个定制为自动扩展。
8.0 中建议:设置1-2个就ok,大小建议1G或者4G,最后一个定制为自动扩展。
独立表空间从5.6开始,默认表空间不再使用共享表空间,替换为独立表空间。
主要存储的是用户数据
存储特点为:一个表一个ibd文件,存储数据行和索引信息
基本表结构元数据存储:
xxx.frm
最终结论:
元数据 数据行+索引
mysql表数据 =(ibdataX+frm)+ibd(段、区、页)
DDL DML+DQL
?
MySQL的存储引擎日志:
Redo Log: ib_logfile0 ib_logfile1,重做日志
Undo Log: ibdata1 ibdata2(存储在共享表空间中),回滚日志
临时表:ibtmp1,在做join union操作产生临时数据,用完就自动
独立表空间设置 -- 查看控制参数
select
硬件及软件环境:
联想服务器(IBM)
磁盘500G 没有raid
centos 6.8
mysql 5.6.33 innodb引擎 独立表空间
备份没有,日志也没开
?
开发用户专用库:
jira(bug追踪) 、 confluence(内部知识库) ------>LNMT
故障描述:
断电了,启动完成后“/” 只读
fsck 重启,系统成功启动,mysql启动不了。
结果:confulence库在 , jira库不见了
求助:
这种情况怎么恢复?
我问:
有备份没
求助:
连二进制日志都没有,没有备份,没有主从
我说:
没招了,jira需要硬盘恢复了。
求助:
1、jira问题拉倒中关村了
2、能不能暂时把confulence库先打开用着
将生产库confulence,拷贝到1:1虚拟机上/var/lib/mysql,直接访问时访问不了的
?
问:有没有工具能直接读取ibd
我说:我查查,最后发现没有
我想出一个办法来:
表空间迁移:
create table xxx alter table confulence.t1 discard tablespace; alter table confulence.t1 import tablespace; 虚拟机测试可行。
处理问题思路:
confulence库中一共有107张表。
1、创建107和和原来一模一样的表。
他有2016年的历史库,我让他去他同时电脑上 mysqldump备份confulence库
mysqldump -uroot -ppassw0rd -B confulence --no-data >test.sql
拿到你的测试库,进行恢复
到这步为止,表结构有了。
2、表空间删除。
select concat(‘alter table ‘,table_schema,‘.‘table_name,‘ discard tablespace;‘) from information_schema.tables where table_schema=‘confluence‘ into outfile ‘/tmp/discad.sql‘;
source /tmp/discard.sql
执行过程中发现,有20-30个表无法成功。主外键关系
很绝望,一个表一个表分析表结构,很痛苦。
set foreign_key_checks=0 跳过外键检查。
把有问题的表表空间也删掉了。
3、拷贝生产中confulence库下的所有表的ibd文件拷贝到准备好的环境中
select concat(‘alter table ‘,table_schema,‘.‘table_name,‘ import tablespace;‘) from information_schema.tables where table_schema=‘confluence‘ into outfile ‘/tmp/discad.sql‘;
4、验证数据
表都可以访问了,数据挽回到了出现问题时刻的状态
课后练习作业:
案例2 : MySQL 5.7 中误删除了ibdata1文件,导致数据无法启动,如何恢复t100w,假设一共100张表,表结构无法通过show create table 获得。
提示:万一是自研数据库,怎么办?又没备份,那怎么办?
mysql工具包,mysqlfrm 读取frm文件获得表结构。
./mysqlfrm /data/3306/data/test/t100w.frm --diagnostic
select concat(‘alter table ‘,table_schema,‘.‘table_name,‘ discard tablespace;‘) from information_schema.tables where table_schema=‘confluence‘ into outfile ‘/tmp/discad.sql‘;
source /tmp/discard.sql
#删除ib_logfile0
#删除ib_logfile1
不要删除ibdata1 ibdata2 ibdata3
获取表结构8.0之前
可以使用
cd /opt
wget https://downloads.mysql.com/archives/get/p/30/file/mysql-utilities-1.6.5.tar.gz
tar -xvzf mysql-utilities-1.6.5.tar.gz
python /opt/mysql-utilities-1.6.5/setup.py build
python /opt/mysql-utilities-1.6.5/setup.py install
# 获取独立表空间的表结构
mysqlfrm --diagnostic 表名.frm | grep -v "^#" > /tmp/db_table.sql
注意:.frm文件中没有外键约束和自增长序列的信息
删除表空间前可以设置跳过外键检查来规避问题
set foreign_key_checks=0
8.0之后
可以使用
参考文章:
把 表名.ibd 中的表结构以json的格式输出到 dbsdi.json文件
ibd2sdi --dump-file=dbsdi.json 表名.ibd
注意:当存在中文注释时,解析出来的注释可能是乱码的,而且大概率会触发ibd2sdi的bug(中文乱码导致json格式错误,比如缺少引号)。
此时可以使用vscode打开dbsdi.json,vscode会高亮json文件格式正确的部分,手动修复不正确的格式,保存。
使用
CentOS 使用yum安装
通用命令
ibd2sdi 表名.ibd |jq ‘.[]?|.[]?|.dd_object?|({table:.name?},(.columns?|.[]?|{name:.name,type:.column_type_utf8}))‘ > dbsdi-jq.json
Windows 下载可执行文件安装
Powershell调用jq解析json文件
Get-Content -Path dbsdi.json |jq ‘.[]?|.[]?|.dd_object?|({table:.name?},(.columns?|.[]?|{name:.name,type:.column_type_utf8}))‘ > dbsdi-jq.json
撤销表空间存储撤消日志,用来回滚事务。
撤销表空间查看配置参数 -- 打开独立undo模式,并设置undo的个数,建议3-5个,8.0弃用
SELECT @@innodb_undo_tablespaces;
-- undo日志的大小,默认1G
SELECT @@innodb_max_undo_log_size;
-- 开启undo自动回收的机制(undo_purge)
SELECT @@innodb_undo_log_truncate;
-- 触发自动回收的条件,单位是检测次数
SELECT @@innodb_purge_rseg_truncate_frequency;
-- undo文件存储路径
SELECT @@innodb_undo_directory;
撤销表空间配置
默认存储在共享表空间中(ibdataN),生产中必须手工独立出来,否则影响高并发效率。
只能在初始化时配置undo个数,并且是固定的。
# 1.创建目录
[root@db01 ~]# mkdir /data/3357/{data,etc,socket,log,pid,undologs} -pv
[root@db01 ~]# chown -R mysql. /data/*
?
# 2.添加参数
[root@db01 ~]# vim /data/3357/my.cnf
[mysqld]
innodb_undo_tablespaces=3
innodb_max_undo_log_size=128M
innodb_undo_log_truncate=ON
innodb_purge_rseg_truncate_frequency=32
innodb_undo_directory=/data/3357/undologs
# 3.初始化数据库
[root@db01 ~]# /usr/local/mysql57/bin/mysqld --defaults-file=/data/3357/my.cnf
--initialize-insecure --user=mysql --basedir=/usr/local/mysql57 --datadir=/data/3357/data
# 4.启动数据库
[root@db01 ~]# /etc/init.d/mysqld start
# 5.查看结果
[root@db01 ~]# ll /data/3357/undologs/
-rw-r----- 1 mysql mysql 10485760 May 11 15:39 /data/3357/undologs/undo001
-rw-r----- 1 mysql mysql 10485760 May 11 15:39 /data/3357/undologs/undo002
-rw-r----- 1 mysql mysql 10485760 May 11 15:39 /data/3357/undologs/undo003
默认就是独立的(undo_001-undo_002),可以随时配置,innodb_undo_tablespaces选项已过时。
-- 查询所有表空间文件
SELECT TABLESPACE_NAME, FILE_NAME FROM INFORMATION_SCHEMA.FILES;
?
-- 查询undo表空间
SELECT TABLESPACE_NAME, FILE_NAME FROM INFORMATION_SCHEMA.FILES WHERE FILE_TYPE LIKE ‘UNDO LOG‘;
?
-- 添加undo表空间
CREATE UNDO TABLESPACE tablespace_name ADD DATAFILE ‘file_name.ibu‘;
?
-- 删除undo表空间
-- 必须为空,先标记为非活动状态,再删除
ALTER UNDO TABLESPACE tablespace_name SET INACTIVE;
DROP UNDO TABLESPACE tablespace_name;
?
-- 监视undo表空间的状态
SELECT NAME, STATE FROM INFORMATION_SCHEMA.INNODB_TABLESPACES WHERE NAME LIKE ‘tablespace_name‘;
undo 表空间管理 SELECT @@innodb_undo_tablespaces; ---->3-5个 #打开独立undo模式,并设置undo的个数。
SELECT @@innodb_max_undo_log_size; #undo日志的大小,默认1G。
SELECT @@innodb_undo_log_truncate; #开启undo自动回收的机制(undo_purge)。
SELECT @@innodb_purge_rseg_truncate_frequency; #触发自动回收的条件,单位是检测次数。
#如果进行undo独立存储到其他文件系统
a. 关闭数据库: [root@db01 data]# systemctl start mysqld3357 b.设定路径参数 innodb_undo_directory=/data/3357/undologs c. 创建目录,并拷贝文件 [root@db01 data]# systemctl stop mysqld3357 mkdir -p /data/3357/undologs chown -R mysql. /data/* cp -a /data/3357/data/undo* /data/3357/undologs
https://dev.mysql.com/doc/refman/8.0/en/innodb-undo-tablespaces.html
临时表空间(ibtmp1)用于存储临时表。建议数据初始化之前设定好,一般2-3个,大小512M-1G。
临时表空间查看配置参数
mysql> select @@innodb_temp_data_file_path;
+------------------------------+
| @@innodb_temp_data_file_path |
+------------------------------+
| ibtmp1:12M:autoextend |
+------------------------------+
配置文件设置,重启生效
[root@db01 ~]# vim /etc/my.cnf
[mysqld]
innodb_temp_data_file_path=ibtmp1:12M;ibtmp2:128M:autoextend:max:500M
分为会话临时表空间和全局临时表空间
会话临时表空间(temp_N.ibt)用于存储临时表。
位置参数
mysql> select @@innodb_temp_tablespaces_dir;
+-------------------------------+
| @@innodb_temp_tablespaces_dir |
+-------------------------------+
| ./#innodb_temp/ |
+-------------------------------+
全局临时表空间(ibtmp1)用于存储对用户创建的临时表进行更改的回滚段。
配置同5.7版本的临时表空间
存储在数据路径下(ib_logfile0,ib_logfile1,...),轮序覆盖记录日志。
刷新策略:commit提交后,刷新当前事务的 redo buffer 到磁盘,还会顺便将一部分 redo buffer 中没有提交的事务日志也刷新到磁盘。
WAL(write ahead log):保证 Redo Log 优先于数据写入磁盘。
查询配置参数
mysql> show variables like ‘%innodb_log_file%‘;
+---------------------------+----------+
| Variable_name | Value |
+---------------------------+----------+
| innodb_log_file_size | 50331648 |
| innodb_log_files_in_group | 2 |
+---------------------------+----------+
设置
生产建议: 设置3-5组,512M-4G
配置文件添加参数,重启生效
[root@db01 ~]# vim /etc/my.cnf
[mysqld]
innodb_log_file_size=100M
innodb_log_files_in_group=3
在rolback时,将数据恢复到修改之前的状态。
在实现CSR时,回滚到redo当中记录的未提交的时候。
5.7版本,存储在共享表空间中 (ibdata1~ibdataN)
8.0版本
对常规表执行操作的事务的撤消日志存储在撤消表空间中(undo_001-undo_002)。 对临时表执行操作的事务的撤消日志存储在全局临时表空间中(ibtmp1)。
每个撤消表空间和全局临时表空间分别支持最多128个回滚段。
配置回滚段的数量
select @@innodb_rollback_segments;
如果在页面写入过程中,发生操作系统,存储子系统或mysqld进程的意外退出,则InnoDB可以在崩溃恢复期间从doublewrite缓冲区中找到页面的良好副本。
8.0.19前默认位于ibdataN中,8.0.20后就独立出来位于#*.dblwr。
用来缓冲和缓存“热”(经常查询或修改)数据页,减少物理IO。MySQL 5.7默认启用。
当关闭数据库的时候,缓冲和缓存会失效。5.7版本后,MySQL正常关闭时,会将内存的热数据存放(流方式)至ib_buffer_pool。下次重启直接读取ib_buffer_pool加载到内存中。
查询配置参数
指定在关闭MySQL服务器时是否记录InnoDB
select @@innodb_buffer_pool_dump_at_shutdown;
select @@innodb_buffer_pool_load_at_startup;
①
-- 查看缓存池大小,默认128M
mysql> select @@innodb_buffer_pool_size;
+---------------------------+
| @@innodb_buffer_pool_size |
+---------------------------+
| 134217728 |
+---------------------------+
生产建议:物理内存的:50-80%
全局设置: 重新连接mysql生效。
set global innodb_buffer_pool_size=268435456;
永久设置:配置文件添加参数,重启mysql生效
vim /etc/my.cnf [mysqld] innodb_buffer_pool_size=256M
②
-- 查询缓冲池实例数量,默认1,最大为64
mysql> select @@innodb_buffer_pool_instances;
+--------------------------------+
| @@innodb_buffer_pool_instances |
+--------------------------------+
| 1 |
+--------------------------------+
注意:仅当您将innodb_buffer_pool_size大小设置为1GB或更大时,此选项才生效,是所有缓冲池实例大小之和。
为了获得最佳效率,请组合 innodb_buffer_pool_instances 和innodb_buffer_pool_size使得每个缓冲池实例是至少为1GB。
用于保存要写入磁盘上的日志文件(Redo Log)的数据。
查询配置参数
select @@innodb_log_buffer_size;
默认大小:16M ? 生产建议:innodb_log_file_size的1-N倍 永久设置:配置文件添加参数,重启mysql生效
vim /etc/my.cnf
[mysqld]
innodb_log_buffer_size=33554432
源端:3306/test/t100w -----> 目标端:3307/test/t100w
锁定源端t100w表
mysql> flush tables test.t100w with read lock ; mysql> show create table test.t100w; CREATE TABLE t100w ( id int(11) DEFAULT NULL, num int(11) DEFAULT NULL, k1 char(2) DEFAULT NULL, k2 char(4) DEFAULT NULL, dt timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; 目标端创建test库和t100w空表 [root@db01 ~]# systemctl start mysqld3307 [root@db01 ~]# mysql -S /tmp/mysql3307.sock mysql> create database test charset=utf8mb4; CREATE TABLE t100w ( id int(11) DEFAULT NULL, num int(11) DEFAULT NULL, k1 char(2) DEFAULT NULL, k2 char(4) DEFAULT NULL, dt timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; 单独删除空的表空间文件 mysql> alter table test.t100w discard tablespace; 拷贝源端ibd文件到目标端目录,并设置权限 [root@db01 test]# cp -a /data/3306/data/test/t100w.ibd /data/3307/data/test/ [root@db01 test]# chown -R mysql.mysql /data/* 导入表空间 mysql> alter table test.t100w import tablespace; mysql> select count(*) from test.t100w; +----------+ | count(*) | +----------+ | 1000000 | 解锁源端数据表 mysql> unlock tables;
#重做日志 (redo log)
ib_logfile0~N 48M , 轮询使用
# 日志缓冲区
redo log buffer : redo内存区域
# 表空间数据文件
ibd : 存储数据行和索引
# 数据缓冲区
InnoDB buffer pool : 缓冲区池,数据和索引的缓冲
# 日志序列号
LSN
磁盘数据页(ibd文件的page),redo log文件(ib_logfile),Innodb_buffer_pool中的数据页,redo buffer
MySQL 每次数据库启动,都会比较磁盘数据页和redolog的LSN,必须要求两者LSN一致数据库才能正常启动
#WAL : Write Ahead Log
Redo日志优先于数据页写到磁盘。
# 脏页: Dirty Page
内存脏页,内存中发生了修改,没写入到磁盘之前,我们把内存页称之为脏页.
# CheckPoint
CKPT:检查点,就是将脏页刷新到磁盘的动作
#DB_TRX_ID(6字节) 事务ID号
InnoDB会为每一个事务生成一个事务号,伴随着整个事务生命周期.
#DB_ROLL_PTR(7字节) 回滚指针
rollback 时,会使用 undo 日志回滚已修改的数据。DB_ROLL_PTR指向了此次事务的回滚位置点,用来找到undo日志信息。
事务工作流程原理
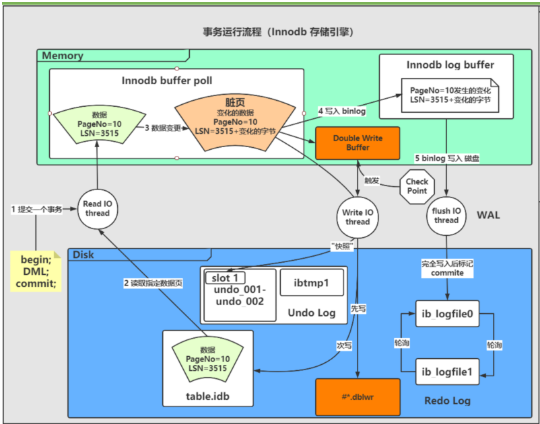
事务举例:
begin;
update t1 set A=2 where A=1;
commit;
#redo log 重做日志如何应用
1.用户发起update事务语句,将磁盘数据页(page100,A=1,LSN=1000)加载到内存(buffer_pool)缓冲区。
2.在内存中发生数据页修改(A=1改成A=2),形成脏页,更改中数据页的变化,记录到redo buffer中,加入1000个字节日志。LSN=1000+1000=2000。
3. 当commit语句执行时,基于WAL机制,等到redo buffer中的日志完全落盘到ib_logfileN中,commit正式完成。
4. ib_logfileN中记录了一条日志。内容:page100数据页变化+LSN=2000。
##情景: 当此时,redo落地了,数据页没有落地,宕机了。
5. MySQL CR(自动故障恢复)工作模式,启动数据库时,自动检查redo的LSN和数据页LSN。
6. 如果发现redoLSN数据页的LSN,加载原始数据页+变化redo指定内存。使用redo重构脏页(前滚)。
7. 如果确认此次事务已经提交(commit标签),立即触发CKPT动作,将脏页刷写到磁盘上。
? MySQL有一种机制,批量刷写redo的机制。会在A事务commit时,顺便将redo buffer中的未提交的redo日志也一并刷到磁盘。
? 为了区分不同状态的redo,日志记录时,会标记是否COMMIT。
redo保证了ACID哪些特性?
主要是D的特性,另外A、C也有间接关联。
undo log 回滚日志如何应用?
1. 事务发生数据页修改之前,会申请一个undo事务操作,保存事务回滚日志(逆向操作的逻辑日志)。
2. undo写完之后,事务修改数据页头部(会记录DB_TRX_ID+DB_ROLL_PTR),这个信息也会被记录的redo。
情景1:
当执行rollback命令时。根据数据页的DB_TRX_ID+DB_ROLL_PTR信息,找到undo日志,进行回滚。
情景2:
begin;
update t1 set A=2 where A=1;
宕机。
假设: undo 有 , redo没有
启动数据库时,检查redo和数据页的LSN号码。发现是一致的。
所以不需要进行redo的前滚,此时也不需要回滚。undo信息直接被标记为可覆盖状态。
假设:undo 有,redo也有(没有commit标签。)
3. MySQL CR(自动故障恢复)工作模式,启动数据库时,自动检查redo的LSN和数据页LSN。
4. 如果发现redoLSN数据页的LSN ,加载原始数据页+变化redo指定内存。使用redo重构脏页(前滚)。
5. 如果确认此次事务没有commit标记,立即触发回滚操作,根据DB_TRX_ID+DB_ROLL_PTR信息,找到und回滚日志,实现回滚。
以上流程被称之为InnoDB的核心特性:自动故障恢复(Crash Recovery)。先前滚再回滚,先应用redo再应用undo。
undo在ACID中保证了啥?
主要保证事务的A的特性,同时C和I的特性也有关系。
事务中的C特性怎么保证?
InnoDB crash recovery:数据库意外宕机时刻,通过redo前滚+undo回滚保证数据的最终一致。
InnoDB doublewrite buffer: 默认存储在ibdataN中。解决数据页写入不完整
mysqld process crash in the middle of a page write, InnoDB can find a good copy of the page from the doublewrite buffer during crash recovery.
DWB一共2M。分两次,每次1M写入
作用:
缓冲和缓存,用来做“热”(经常查询或修改)数据页,减少物理IO。
当关闭数据库的时候,缓冲和缓存会失效。
5.7版本中,MySQL正常关闭时,会将内存的热数据存放(流方式)至ib_buffer_pool。下次重启直接读取ib_buffer_pool加载到内存中。
mysql> select @@innodb_buffer_pool_dump_at_shutdown;
mysql> select @@innodb_buffer_pool_load_at_startup;
作用: MySQL,最小IO单元page(16KB),OS中最小的IO单元是block(4KB) 为了防止出现以下问题:
mysqld process exit in the middle of a page write, InnoDB can find a good copy of the page from the doublewrite buffer during crash recovery.
#mysqld进程退出在页面写入中间过程中,InnoDB可以在崩溃恢复期间从双写缓冲区找到一个好的页面副本。
作用:
用来缓冲、缓存,MySQL的数据页和索引页。MySQL中最大的、最重要的内存区域。
管理:
查询
mysql> select @@innodb_buffer_pool_size;
默认大小: 128M
生产建议: 物理内存的:50-80%。
OOM,全称“Out Of Memory”,
在线设置(256M):
mysql> select 256*1024*1024;
+---------------+
| 256*1024*1024 |
+---------------+
| 268435456 |
+---------------+
mysql> set global innodb_buffer_pool_size=268435456;
重新登录mysql生效。
永久设置:
vim /etc/my.cnf
#添加参数
innodb_buffer_pool_size=256M
重启生效
作用: 用来缓冲 redo log日志信息。 管理 :
查询:
mysql> select @@innodb_log_buffer_size;
默认大小:16M
生产建议:和innodb_log_file_size有关,1-N倍
设置方式 :
vim /etc/my.cnf
innodb_log_buffer_size=33554432
重启生效:
[root@db01 data]# /etc/init.d/mysqld restart
介绍
事务:Transaction (交易)。 伴随着交易类的业务出现的概念(工作模式)
交易?
物换物,等价交换。
货币换物,等价交换。
虚拟货币换物(虚拟物品),等价交换。
现实生活中怎么保证交易“和谐” ,法律、道德等规则约束。
数据库中为了保证线上交易的“和谐”,加入了“事务”工作机制。
A: 原子性 (atomicity)
一个事物是一个完整整体,不可再分。
一个事务生命周期中的DML语句,要么全成功要么全失败,不可以出现中间状态。
begin;
DML1;
DML2;
DML3;
commit;
C:一致性 (consistency)
事务发生前,中,后,数据都最终保持一致。
只要提交成功的事务,数据保证最终一致。
CR + double write
I:隔离性 (isolation)
事务操作数据行的时候,不会受到其他时候的影响。
D: 持久性 (durability)
一但事务提交,保证永久生效,落盘。
# 开启事务
begin;
# 提交事务
commit;
# 回滚事务
rollback;
注意:事务生命周期中,只能使用DML语句(select、update、delete、insert)
1、检查autocommit是否为关闭状态
select @@autocommit;
或者:
show variables like ‘autocommit‘;
2、开启事务,并结束事务
begin delete from student where name=‘alexsb‘; update student set name=‘alexsb‘ where name=‘alex‘; rollback; begin delete from student where name=‘alexsb‘; update student set name=‘alexsb‘ where name=‘alex‘; commit;
mysql> use world mysql> begin; mysql> delete from city where id=1; mysql> update city set countrycode=‘CHN‘ where id=2; mysql> commit; mysql> begin; mysql> select * from city limit 10; mysql> update city set countrycode=‘AFG‘ where id=2; mysql> delete from city where id=3; mysql> rollback; MySQL的自动提交机制(autocommit) 参数: mysql> select @@autocommit; +--------------+ | @@autocommit | +--------------+ | 1 | +--------------+
作用:
在没有显示的使用begin语句的时候,执行DML,会在DML前自动添加begin,并在DML执行后自动添加commit。
建议: 频繁事务业务场景中,关闭autocommit,或者每次事务执行时都是显示的begin和commit;
mysql> set global autocommit=0;
退出会话,重新连接配置生效。
[root@db01 ~]# vim /etc/my.cnf
autocommit=0
重启生效。
不进行begin操作,逐条提交。
begin;
DML1;
DML2;
DML3;
commit;
begin
a
b
SET AUTOCOMMIT = 1
导致提交的非事务语句:
DDL语句: (ALTER、CREATE 和 DROP)
DCL语句: (GRANT、REVOKE 和 SET PASSWORD)
锁定语句:(LOCK TABLES 和 UNLOCK TABLES)
导致隐式提交的语句示例:
TRUNCATE TABLE
LOAD DATA INFILE
SELECT FOR UPDATE
会话窗口被关闭。
数据库关闭 。
出现事务冲突(死锁)。
作用
实现事务工作期间的“读”的隔离
读? ----》 数据页的读
级别类型
mysql> select @@transaction_isolation;
READ-UNCOMMITTED 读未提交 优点:可以读取到事务未提交的数据。事务并发度最高。
缺点:隔离性差,会出现脏读(当前内存读),不可重复读,幻读问题
READ-COMMITTED 读已提交(可以用) 优点:防止脏读,防止不可重复读
缺点:不可重复读,幻读
REPEATABLE-READ 可重复读(默认) 优点:防止脏读,防止不可重复读
缺点:事务并发度一般,幻读问题
SERIALIZABLE 串行读 优点:隔离性最好
缺点:事务没有并发
默认级别是RR级别,互联网业务的大部分场景RC级别。
RC 可以减轻GAP+NextLock锁的问题,一般在为了读一致性会在正常select后添加for update语句.但是,请记住执行完一定要commit否则容易出现所等待比较严重.
RC 可以减轻GAP+NextLock锁的问题,一般在为了读一致性会在正常select后添加for update语句.但是,请记住执行完一定要commit否则容易出现所等待比较严重.
例如:
[world]>select * from city where id=999 for update;
[world]>commit;
RR 利用的是undo的快照技术+GAP(间隙锁)+NextLock(下键锁)
select @@transaction_isolation;
set global transaction_isolation=‘READ-UNCOMMITTED‘;
set global transaction_isolation=‘READ-COMMITTED‘;
set global transaction_isolation=‘REPEATABLE-READ‘;
set global transaction_isolation=‘SERIALIZABLE‘;
vim /etc/my.cnf
[mysqld]
transaction_isolation=‘READ-COMMITTED‘;
-- 创建测试库 create database test; -- 创建测试表 create table test.t1 ( id int not null primary key auto_increment , a int not null , b varchar(20) not null, c varchar(20) not null )charset=utf8mb4 engine=innodb; ? begin; insert into test.t1(a,b,c) values (1,‘a‘,‘aa‘), (2,‘c‘,‘ab‘), (3,‘d‘,‘ae‘), (4,‘e‘,‘ag‘), (5,‘f‘,‘at‘); commit; -- 关闭自动提交 set global autocommit=0; -- 打开两个会话窗口: -- sessionA: -- sessionB:
一些概念
redo log ---> 重做日志 ib_logfile0~1 50M , 轮询使用
redo log buffer ---> redo内存区域
ibd ----> 存储 数据行和索引
buffer pool --->缓冲区池,数据和索引的缓冲
LSN : 日志序列号
磁盘数据页,redo文件,buffer pool,redo buffer
MySQL 每次数据库启动,都会比较磁盘数据页和redolog的LSN,必须要求两者LSN一致数据库才能正常启动
WAL : write ahead log 日志优先写的方式实现持久化
脏页: 内存脏页,内存中发生了修改,没写入到磁盘之前,我们把内存页称之为脏页.
CKPT:Checkpoint,检查点,就是将脏页刷写到磁盘的动作
TXID: 事务号,InnoDB会为每一个事务生成一个事务号,伴随着整个事务.
脏读又称无效数据的读出,当前内存读,可以读取到别人未提交的数据。
例如:事务T1修改某一值,未提交,但是事务T2却能读取该值,此后T1因为某种原因撤销对该值的修改,这就导致了T2所读取到的数据是无效的。注意,脏读一般是针对于update操作。
-- RU级别下不可重读现象演示:
-- 第一步:设置隔离级别,重新连接数据库 mysql> set global transaction_isolation=‘READ-UNCOMMITTED‘; mysql> exit -- 第二步:检查隔离级别 -- sessionA: mysql> select @@transaction_isolation; +-------------------------+ | @@transaction_isolation | +-------------------------+ | READ-UNCOMMITTED | +-------------------------+ -- sessionB: mysql> select @@transaction_isolation; +-------------------------+ | @@transaction_isolation | +-------------------------+ | READ-UNCOMMITTED | +-------------------------+ -- 第三步:开启事务 -- sessionA: mysql> begin; -- sessionB: mysql> begin; -- 第四步:查看当前表数据 -- sessionA: mysql> select * from test.t1 where id=2; +----+---+---+----+ | id | a | b | c | +----+---+---+----+ | 2 | 2 | c | ab | +----+---+---+----+ -- sessionB: mysql> select * from test.t1 where id=2; +----+---+---+----+ | id | a | b | c | +----+---+---+----+ | 2 | 2 | c | ab | +----+---+---+----+ -- 第五步: -- sessionA: 执行DML语句 mysql> update test.t1 set a=8 where id=2; -- 第六步: -- sessionB:查看当前表数据发现数据变化,脏读 mysql> select * from test.t1 where id=2; +----+---+---+----+ | id | a | b | c | +----+---+---+----+ | 2 | 8 | c | ab | +----+---+---+----+ -- 第七步: -- sessionA: 回滚 mysql> rollback; -- 第八步: -- sessionB:查看当前表数据发现数据变化,不可重复读 mysql> select * from test.t1 where id=2; +----+---+---+----+ | id | a | b | c | +----+---+---+----+ | 2 | 2 | c | ab | +----+---+---+----+
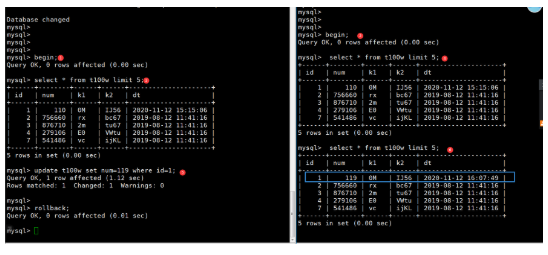
不可重复读,指一个事务范围内两个相同的查询却返回了不同数据。
这是由于查询时系统中其他事务修改的提交而引起的。比如事务T1读取某一数据,事务T2读取并修改了该数据,T1为了对读取值进行检验而再次读取该数据,便得到了不同的结果。
-- RC级别下不可重读现象演示:
-- 第一步:设置隔离级别,重新连接数据库 mysql> set global transaction_isolation=‘READ-COMMITTED‘; mysql> exit -- 第二步:检查隔离级别 -- sessionA: mysql> select @@transaction_isolation; +-------------------------+ | @@transaction_isolation | +-------------------------+ | READ-COMMITTED | +-------------------------+ -- sessionB: mysql> select @@transaction_isolation; +-------------------------+ | @@transaction_isolation | +-------------------------+ | READ-COMMITTED | +-------------------------+ -- 第三步:开启事务 -- sessionA: mysql> begin; -- sessionB: mysql> begin; -- 第四步:查看当前表数据 -- sessionA: mysql> select * from test.t1 where id=1; +----+---+---+----+ | id | a | b | c | +----+---+---+----+ | 1 | 1 | a | aa | +----+---+---+----+ -- sessionB: mysql> select * from test.t1 where id=1; +----+---+---+----+ | id | a | b | c | +----+---+---+----+ | 1 | 1 | a | aa | +----+---+---+----+ -- 第五步: -- sessionA: 执行DML语句并提交事务 mysql> update test.t1 set a=6 where id=1; mysql> commit; -- 第六步: -- sessionB:查看当前表数据发现数据变化 mysql> select * from test.t1 where id=1; +----+---+---+----+ | id | a | b | c | +----+---+---+----+ | 1 | 6 | a | aa | +----+---+---+----+
例如:第一个事务对一个表中的数据进行了修改,比如这种修改涉及到表中的“全部数据行”。同时,第二个事务也修改这个表中的数据,这种修改是向表中插入“一行新数据”。那么,就会发生操作第一个事务的用户发现表中还存在没有修改的数据行,就好象发生了幻觉一样。
一般解决幻读的方法是增加范围锁RangeS,锁定检索范围为只读,这样就避免了幻读。
-- RC级别下幻读现象演示: -- 第一步:设置隔离级别,重新连接数据库 mysql> set global transaction_isolation=‘READ-COMMITTED‘; mysql> exit -- 第二步:检查隔离级别 -- sessionA: mysql> select @@transaction_isolation; +-------------------------+ | @@transaction_isolation | +-------------------------+ | READ-COMMITTED | +-------------------------+ -- sessionB: mysql> select @@transaction_isolation; +-------------------------+ | @@transaction_isolation | +-------------------------+ | READ-COMMITTED | +-------------------------+ -- 第三步:开启事务 -- sessionA: mysql> begin; -- sessionB: mysql> begin; -- 第四步:查看当前表数据 -- sessionA: mysql> select * from test.t1; +----+---+---+----+ | id | a | b | c | +----+---+---+----+ | 1 | 6 | a | aa | | 2 | 2 | c | ab | | 3 | 3 | d | ae | | 4 | 4 | e | ag | | 5 | 5 | f | at | +----+---+---+----+ -- sessionB: mysql> select * from test.t1; +----+---+---+----+ | id | a | b | c | +----+---+---+----+ | 1 | 6 | a | aa | | 2 | 2 | c | ab | | 3 | 3 | d | ae | | 4 | 4 | e | ag | | 5 | 5 | f | at | +----+---+---+----+ -- 第五步: -- sessionA:执行DML语句,全部数据行修改 mysql> update test.t1 set a=10 where a<10; -- 第六步: -- sessionB:执行DML语句,插入一行数据,提交事务 mysql> insert into test.t1(a,b,c) values (1,‘z‘,‘az‘); mysql> commit; -- 第七步: -- sessionA:提交事务 mysql> commit; -- 第八步: -- sessionA:查看当前表数据,好像发生了幻觉 mysql> select * from test.t1; +----+----+---+----+ | id | a | b | c | +----+----+---+----+ | 1 | 10 | a | aa | | 2 | 10 | c | ab | | 3 | 10 | d | ae | | 4 | 10 | e | ag | | 5 | 10 | f | at | | 6 | 1 | z | az | +----+----+---+----+
名词介绍
重做日志(redo log)
磁盘 ib_logfile0~N innodb_log_file_size
innodb_log_files_in_group
内存 innodb_log_buffer innodb_log_buffer_size
表数据
磁盘 独立表空间 xxxibd segment extents pages 内存 innodb_buffer_pool innodb_buffer_pool_size 日志序列号LSN 一个顺序递增的数字 记录数据页变化的版本 redo日志的变化量(字节) 哪些对象有LSN redo buffer Log sequence number 180973874 redo log Log flushed up to 180973874 数据页 Last checkpoint at 180973874 查询方式 show engine innodb status \G write ahead log(WAL) 日志先行 commit提交事务时,保证日志先写磁盘,数据后写 脏页:Dirty Page 在内存中修改的数据页,没写到磁盘的叫做脏页 检查点:CheckPoint 将脏页刷新到磁盘的动作 DB_ROLL_TR 回滚指针 存储在数据页头部
重做日志 (redo log)
ib_logfile0~N 48M , 轮询使用
日志缓冲区 redo log buffer : redo内存区域
ibd: 存储数据行和索引
InnoDB buffer pool : 缓冲区池,数据和索引的缓冲
LSN
磁盘数据页(ibd文件的page),redo log文件(ib_logfile),Innodb_buffer_pool中的数据页,redo buffer
MySQL 每次数据库启动,都会比较磁盘数据页和redolog的LSN,必须要求两者LSN一致数据库才能正常启动
#WAL : Write Ahead Log
Redo日志优先于数据页写到磁盘。
内存脏页,内存中发生了修改,没写入到磁盘之前,我们把内存页称之为脏页.
CKPT:检查点,就是将脏页刷新到磁盘的动作
#DB_TRX_ID(6字节) 事务ID号
InnoDB会为每一个事务生成一个事务号,伴随着整个事务生命周期.
#DB_ROLL_PTR(7字节) 回滚指针
rollback 时,会使用 undo 日志回滚已修改的数据。DB_ROLL_PTR指向了此次事务的回滚位置点,用来找到undo日志信息。
事务工作流程原理
事务举例:
begin;
update t1 set A=2 where A=1;
commit;
#redo log 重做日志如何应用
用户发起update事务语句,将磁盘数据页(page100,A=1,LSN=1000)加载到内存(buffer_pool)缓冲区。
在内存中发生数据页修改(A=1改成A=2),形成脏页,更改中数据页的变化,记录到redo buffer中,加入1000个字节日志。LSN=1000+1000=2000。
当commit语句执行时,基于WAL机制,等到redo buffer中的日志完全落盘到ib_logfileN中,commit正式完成。
ib_logfileN中记录了一条日志。内容:page100数据页变化+LSN=2000。
##情景: 当此时,redo落地了,数据页没有落地,宕机了。
MySQL CR(自动故障恢复)工作模式,启动数据库时,自动检查redo的LSN和数据页LSN。
如果发现redoLSN>数据页的LSN ,加载原始数据页+变化redo指定内存。使用redo重构脏页(前滚)。
如果确认此次事务已经提交(commit标签),立即触发CKPT动作,将脏页刷写到磁盘上。
MySQL有一种机制,批量刷写redo的机制。会在A事务commit时,顺便将redo buffer中的未提交的redo日志也一并刷到磁盘。
为了区分不同状态的redo,日志记录时,会标记是否COMMIT。
主要是D的特性,另外A、C也有间接关联。
1.事务发生数据页修改之前,会申请一个undo事务操作,保存事务回滚日志(逆向操作的逻辑日志)。
2.undo写完之后,事务修改数据页头部(会记录DB_TRX_ID+DB_ROLL_PTR),这个信息也会被记录的redo。
情景1:
当执行rollback命令时。根据数据页的DB_TRX_ID+DB_ROLL_PTR信息,找到undo日志,进行回滚。
情景2:
begin;
update t1 set A=2 where A=1;
宕机。
假设: undo 有 , redo没有
启动数据库时,检查redo和数据页的LSN号码。发现是一致的。
所以不需要进行redo的前滚,此时也不需要回滚。undo信息直接被标记为可覆盖状态。
假设:undo 有,redo也有(没有commit标签。)
3.MySQL CR(自动故障恢复)工作模式,启动数据库时,自动检查redo的LSN和数据页LSN。
4.如果发现redoLSN>数据页的LSN ,加载原始数据页+变化redo指定内存。使用redo重构脏页(前滚)。
5.如果确认此次事务没有commit标记,立即触发回滚操作,根据DB_TRX_ID+DB_ROLL_PTR信息,找到und回滚日志,实现回滚。
以上流程被称之为InnoDB的核心特性:自动故障恢复(Crash Recovery)。先前滚再回滚,先应用redo再应用undo。
主要保证事务的A的特性,同时C和I的特性也有关系。 事务中的C特性怎么保证?
InnoDB crash recovery:数据库意外宕机时刻,通过redo前滚+undo回滚保证数据的最终一致。
InnoDB doublewrite buffer: 默认存储在ibdataN中。解决数据页写入不完整
mysqld process crash in the middle of a page write, InnoDB can find a good copy of the page from the doublewrite buffer during crash recovery.
DWB一共2M。分两次,每次1M写入
事务中的I的特性怎么保证?
隔离级别:读隔离性 RU: 脏读 、 不可重复读 、幻读
RC: 不可重复读、幻读
RR:有可能会出现幻读。
SR(SE):事务串行工作。
锁机制:写的隔离作用:保护并发访问资源。
保护的资源分类:
latch(闩锁):rwlock、mutex,主要保护内存资源
MDL: Metadata_lock,元数据(DDL操作)
table_lock: 表级别
lock table t1 read ;
mysqldump、XBK(PBK):备份非InnoDB数据时,触发FTWRL全局锁表(Global)。
行锁升级为表锁。
row lock:InnoDB 默认锁粒度,加锁方式都是在索引加锁的。
record lock:记录锁,在聚簇索引锁定。RC级别只有record lock。
gap lock:间隙锁,在辅助索引间隙加锁。RR级别存在。防止幻读。
next lock:下一键锁,GAP+Record。 RR级别存在。防止幻读。 (,]
如何监控行锁问题?
mysql> select * from sys.innodb_lock_waits\G
IS: select * from t1 lock in shared mode;
S : 读锁。
IX: 意向排他锁。表上添加的。 select * from t1 for update;
X : 排他锁,写锁。
乐观锁: 乐观。
悲观锁: 悲观。
每个事务操作都要经历两个阶段:
读: 乐观锁。
MVCC利用乐观锁机制,实现非锁定读取。
read view:RV,版本号集合。
trx1 :
begin;
dml1 ---> 在做第一个查询的时候,当前事务,获取系统最新的:RV1 版本快照。
dml2 ---> 生成 RV2 版本快照。
select 查询 RV2 快照数据
commit; ----> RV2 快照数据 ----》系统最新快照。
RC
trx1: Rv1 Rv2 commit;
trx2 RVV1 RVV1 RV2
RR
trx1 : 第一个查询时, 生成global consitence snapshot RV-CS1(10:00) ,一直伴随着事务生命周期结束。
trx2 : 第一个查询时,生成global consitence snapshot RV-CS2(10:01) ,一直伴随着事务生命周期结束。
快照技术由undo log来提供。
写: 悲观锁 X
总结:
1.MVCC采用乐观锁机制,实现非锁定读取。
2.在RC级别下,事务中可以立即读取到其他事务commit过的readview
3.在RR级别下,事务中从第一次查询开始,生成一个一致性readview,直到事务结束。
原文:https://www.cnblogs.com/strugger-0316/p/14471870.html