我用的系统是ubuntu20.04,因为想学习大数据方面的东西,首先接触的就是hadoop,我选择的书籍是林大贵老师的python3+Hadoop+spark,今晚折腾了一晚上,终于把hadoop单机折腾了跑通了。这个文章记录了入坑的详细细节
下面是目录步骤:
(1)到官网下载jdk最新版
http://www.oracle.com/technetwork/java/javase/downloads/index.html,(另一种方案是选择从apt安装,如果机器上没有java,在终端键入java就会提示安装,这时ubuntu很人性的一个细节)
(2)将下载的压缩包文件拷贝到/usr/loacal/,解压缩,建立链接,更改目录所有者。
(3)配置环境变量
(1)安装SSH
(2)安装rsync
(3)生成SSH Key
(4)将产生的key放到许可证文件中
(1)下载Hadoop2.6.4,并安装到Ubuntu中。http://archive.apache.org/dist/hadoop/core/hadoop-2.6.4/
(2)Hadoop常用目录说明
(1)设置每次用户登陆时必须要设置的环境变量。
(2)使环境变量生效
(1)设置hadoop-env.sh
(2)设置core-site.xml
(3)设置YARN-site.xml
(4)设置mapred-site.xml
(5)设置hdfs-site.xml
(1)创建namenode数据存储目录
(2)创建datanode数据存储目录
(3) 将HDFS进行格式化
启动Hadoop
java环境的准备
安装配置完成后下面命令可以查看java的版本:
Java –version
由于我之前配置过java环境,但是配置时候遇到一个问题,忘了java’的安装路径,后来找到这个命令,可以查看java的安装路径:
Java -verbase
命令可以显示系统中java的环境,如图:
这个很重要,因为在后面的配置时候用得到。
1)、安装ssh:
sudo apt-get install ssh
2)、安装rsync
sudo apt-get install rsync
Ps:这两个东西我觉得除了裸机应该都会有用到,易班都有
3)、产生ssh密钥
这一步很重要!
因为当我一切准备就绪启动服务时候,发现要求输入密码!又回过头重新做
首先运行
ssh localhost
如果还要输入密码的话,那就是你ssh没有配置好。这里要说一下的是ssh7.0之后就关闭了dsa的密码验证方式,如果你的秘钥是通过dsa生成的话,需要改用rsa来生成秘钥
ssh-keygen -t rsa -P ‘‘ -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
这里记录一下,>>的作用是将上一个指令的结果输出到指定文件,如果不存在,会新建文件,如果文件是已有的,会跟写到文件的末尾
再次运行
ssh localhost
如果不需要输入密码,说明ssh配置好了。后面就可以正常运行start-all.sh文件了
访问hadoop官网,浏览历史版本。复制2.6.4版本的链接,然后回终端,
使用命令wget获取安装包:
wget
https://archive.apache.org/dist/hadoop/common/hadoop-2.6.4/hadoop-2.6.4.tar.gz
然后解包,移动到usr/local/hadoop目录下:
cd /usr/local
sudo cp ~/下载/hadoop-2.6.4.tar.gz ./
sudo tar -xvzf hadoop-2.6.4.tar.gz
sudo ln -s hadoop-2.6.4 hadoop
把hadoop目录的归属权授予当前用户:
sudo chown -R wy:wy hadoop
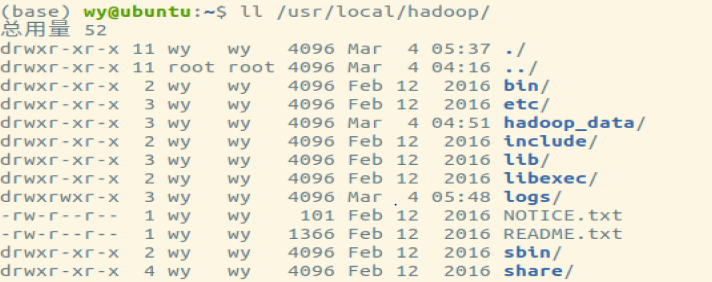
Hadoop目录结构如下:
目录说明如下:
(2)Hadoop常用目录说明
| 目录 | 说明 |
|---|---|
| bin/ | 各项运行文件,包括Hadoop,HDFS,YARN等 |
| sbin/ | 各项shell运行文件,包括start-all.sh、stop-all.sh |
| etc/ | etc/hadoop子目录包含Hadoop配置文件,例如:hadoop-env.sh、core-site.xml、YARN-site.xml |
| lib/ | Hadoop函数库 |
| logs/ | 系统日志,可以查看系统运行情况,运行有问题时可从日志找出错误原因 |
(1)设置每次用户登陆时必须要设置的环境变量。
export JAVA\_HOME=/usr/bin/jvm/java\_open\_11
export HADOOP\_HOME=/usr/local/hadoop
export PATH=\$PATH:\$HADOOP\_HOME/bin
export PATH=\$PATH:\$HADOOP\_HOME/sbin
export HADOOP\_MAPRED\_HOME=\$HADOOP\_HOME
export HADOOP\_COMMON\_HOME=\$HADOOP\_HOME
export HADOOP\_HDFS\_HOME=\$HDOOP\_HOME
export YARN\_HOME=\$HADOOP\_HOME
export HADOOP\_COMMON\_LIB\_NATIVE\_DIR=\$HADOOP\_HOME/lib/native
export HADOOP\_OPTS="-Djava.library.path=\$HADOOP\_HOME/lib"
export JAVA\_LIBRARY\_PATH=\$HADOOP\_HOME/lib/native:\$JAVA\_LIBRARY\_PATH
(2)使环境变量生效
source \~/.bashrc
1
- Hadoop配置文件的设置
在Hadoop的/usr/local/hadoop/etc/hadoop目录下有很多配置设置文件,通过编辑这些文件来启用基本或是更高级的功能。
(1)设置hadoop-env.sh
hadoop-env.sh是Hadoop的配置文件,在这里必须设置Java的安装路径。
修改JAVA_HOME设置
export JAVA_HOME=/usr/local/java
1
(2)设置core-site.xml
在core-site.xml中,必须设置HDFS的默认名称,当我们使用命令或程序要存取HDFS时,可使用此名称。
设置HDFS默认名称
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
(3)设置YARN-site.xml
YARN-site.xml文件中包含有MapReduce2(YARN)相关的配置设置
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
(4)设置mapred-site.xml
mapred-site.xml用于设置监控Map与Reduce程序的JobTracker任务分配情况以及TaskTracker任务运行情况。
拷贝一份mapreduce框
cp mapred-site.xml.template mapred-site.xml
1
设置mapreduce框架为yarn
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(5)设置hdfs-site.xml
hdfs-site.xml用于设置HDFS分布式文件系统。
分别设置blocks副本备份数量,设置NameNode数据存储目录,设置DataNode数据存储目录。
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/hdfs/datanode</value>
</property>
</configuration>
- 创建并格式化HDFS目录
HDFS目录是存储HDFS文件的地方,在启动Hadoop之前必须先创建并格式化HDFS目录。
(1)创建namenode数据存储目录
mkdir -p /usr/local/hadoop/hadoop_data/hdfs/namenode
1
(2)创建datanode数据存储目录
mkdir -p /usr/local/hadoop/hadoop_data/hdfs/datanode
1
(3) 将HDFS进行格式化
hadoop namenode -format
1
此条命令会删除所有的数据
- 启动Hadoop
全部设置完成就可以开始启动Hadoop,并查看Hadoop相关进程是否已经启动
同时启动HDFS和MapReduce框架Yarn
start-all.sh
如下图:
使用jps查看已经启动的进程
jps
如下图:
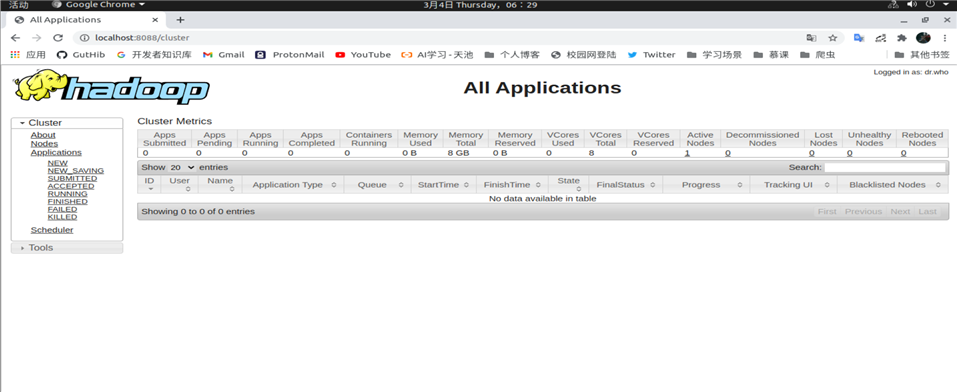
成功后打开本地url:
Localhost:8088
如下图:
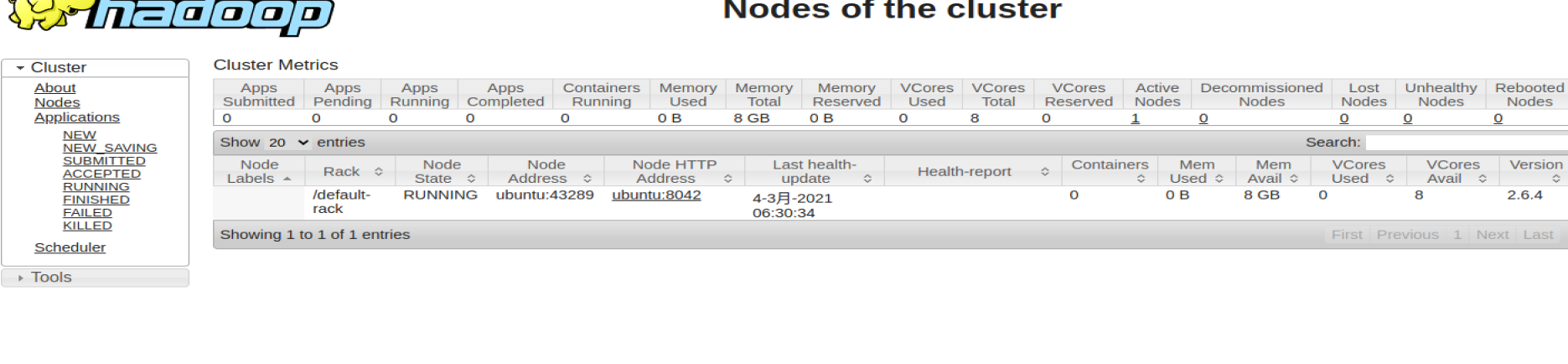
点击Nodes就可以看到当前运行的节点,因为现在只配置类一台主机,所有也就只有一个节点,如下图:
原文:https://www.cnblogs.com/wheaesong/p/14486409.html