分析任何源码之前都要先用一遍,HashMap也不例外。
import java.util.HashMap;
public class Demo {
public static void main(String[] args) {
HashMap<Integer, String> hashMap = new HashMap<>();
hashMap.put(1, "Cracker13");
System.out.println(hashMap.get(1));
}
}
这个段简单的代码,实现了HashMap存、取两个操作。HashMap的结构特点是以键值对的形式。
接下来我们就开始分析源码。
1.进入put方法
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
引入:我们可以看到这里有五个参数,第一个参数对key的值进行了一次计算,第二个参数就是key,第三个参数value,后面2个先不管。
猜想:这里的hash(key)是不是在进行一个下标位置的计算?
思考:key, value进行存储的话,使用的数据结构是什么?HashMap使用的数据结构?
这里我们想到常用的数据结构为ArrayList和LinkedList,即数组和链表
(1)ArrayList底层实现为数组,查询效率比较快(get)
ArrayList的数据结构:

(2)LinkedList底层实现为双向链表,增加和删除比较快(add,delete)
LinkedList的数据结构:

猜想:HashMap能不能引入一个查询效率快,且增加和删除元素效率高的数据结构?
能不能结合ArrayList和LinkedList的优势,所以我们能推出HashMap源码底层的数据结构可能是采用的是数组+链表的形式。
(3)HashMap数据结构(存储键值对)
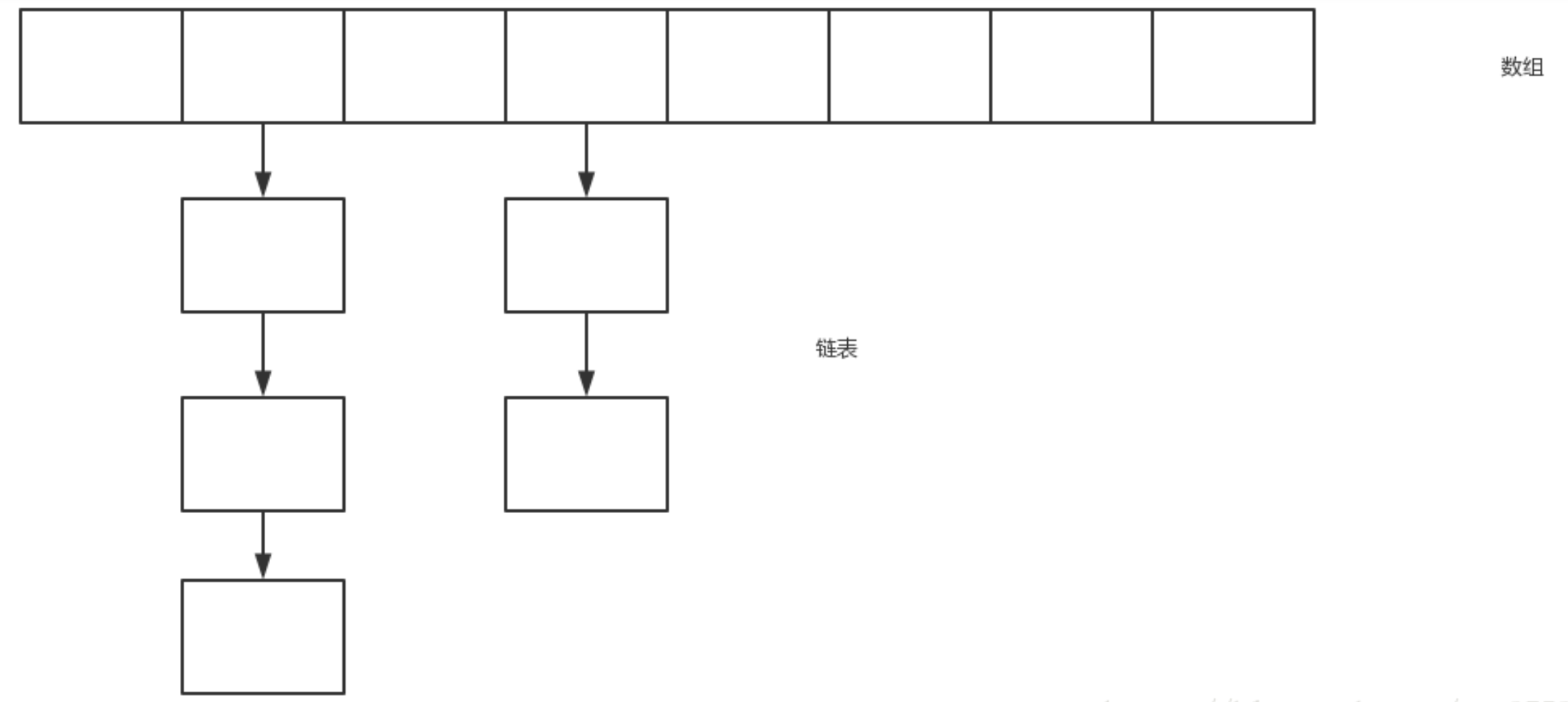
那么接下来我们就来猜一猜HashMap中到底有些什么东西
HashMap结合数组和链表的优势,采用数组+链表的存储结构
(1)推测HashMap中存储的基本单元
思考:HashMap源码中key,value的存储单元是什么?
1.Java是一门面向对象的语言,能不能用一个对象(Node)来存储key,value?
class Node {
private Object key;
private Object value;
}
2.因为HashMap数据结构为数组+链表,所以Node中应该有一个指针指向下一个节点
class Node {
private Object key;
private Object value;
private Node next; //用来指向链表的下一个节点
}
3.因为key和value的类型为已知的,可以传进HashMap,所以key和value前定义为Object不合适,应该用泛型(K,V)来表示key,value的类型
class Node<K,V> {
private K key;
private V value;
private Node<K,V> next;
}
HashMap源码中Node的表示:

结论:猜测Node表示和源码表示结果出入不大
(2)数组这种数据结构在HashMap中该怎么表示?
平常基本类型用Int,String等类型表示。数组用Int[],String[]来表示,那么在HashMap中应该有一个来表示Node<K,V>[] table来表示数组
HashMap源码中表示Node数组:transient代表不可序列化

结论:HashMap中确实有一个Node<K,V>[] table来表示数组
(3)数组要不要有一个大小呢?
初始大小和上限大小?
猜测HashMap中可能有与default_size和max_size类似变量来表示数组的初始大小和上限大小
HashMap源码:DEFAULT_INITIAL_CAPACITY表示默认容量,MAXIMUM_CAPACITY表示最大容量

(4)大小的一个解决方案
假如初始大小为16,如果数组的大小不够用了,或者达到某个值了,是不是应该进行数组扩容呢?
猜想:HashMap中应该有一个扩容的resize方法
HashMap源码:

(5)扩容是不是应该有一个依据?是在数组使用完才扩容还是当数组使用到达一个阈值的时候就扩容?
猜想:扩容时依据数组已经使用容量大于阈值时扩容,如果是大于数组的长度才扩容,这显然是不理想的,效率很慢(这里的阈值小于数组的长度)。
比如数组长度为16,那么数组大小已经达到12的时候就应该扩容,而不是等数组长度达到16时才扩容。
此时应该有一个size来表示数组的使用大小,还有一个小于1的数来乘以数组长度得到数组扩容时的阈值。
HashMap源码:

默认负载因子<1(DEFAULT_LOAD_FACTOR表示默认的负载因子)

数组已使用大小size
size++判断是否到达扩容的阈值,threshold = DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR

(6)链表长度过长效率会下降,HashMap是否也应该有一个阈值来控制链表的长度?大于阈值时是不是该将链表转换为其他数据结构呢?
猜想:HashMap应该有一个阈值来控制链表的长度,当链表长度大于阈值时将链表转换为二叉树或者B 树等数据结构,提高效率。JDK1.8中HashMap采用的是链表转转红黑树,因为红黑树相比于二叉树在失衡的时候旋转的时间复杂度为O(1)
HashMap源码:用TREEIFY_THRESHOLD来控制链表的长度

链表转红黑树:使用treeifyBin方法来将链表转换为红黑树

(6)新来的Node节点到底存在哪里?
猜想:存哪里应该有一个约束,这个约束应该是经过我们计算得来的(现在只知道key和value),那么我们可以用key进行一个计算,计算出这个Node到底存在哪里。那么计算的函数呢?是使用Md5(key)还是Base64?Java中万物皆对象,所有类都是Object的子类,我们可以利用hashcode()方法计算返回一个int值,key.hashcode()就知道存在数组的哪个位置了。但是key.hashcode算出来的int值容易越界,所以应该经过hash函数得到我们的理想值(key.hashcode()%length)得到小于数组的int值
HashMap源码:

static int indexFor(int h, int length) {
return h & (length - 1); //JDK1.8中没有此方法,但实现原理一样,通过位与运算达到取模的作用
}
3.源码分析
(1)put()方法
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
(2)putVal()方法
省略
(3)hash()方法
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
因为我们要知道key,value这个对象到底存在hashMap的哪里。
充分的将int类型的32位数全部应用起来,该数的高16位与低16位做一个^抑或运算,得到的一个二进制的值就知道key,value这个对象存到哪了。
但是你怎么知道它不会越界呢?

再去putval()方法中
如果(tab=table==null)的话,就执行resize()方法,对我们的数组进行初始化大小,n就是默认数组的大小。
n的默认大小是16也就是10000
那n-1就是 01111 与hash值去进行与运算,就可以确保这个数组大小最大也只能是15,所以不会越界
数组的散列性就大了,碰撞概率就低了
数组大小一定要是2的N次幂

如果这个地方没有值,那就将该对象存储到这里
如果这个地方有值,那就用链表的方式往下存储,红黑树扩展。
https://www.bilibili.com/video/BV1cW411g7RH?t=5636
原文:https://www.cnblogs.com/cracker13/p/14492043.html