
HashMap是一个哈希表,它是 非线程安全的,且允许key和value为null.
HashMap采用 数组 + 链表 + 红黑树 的形式来存储数据.不保证插入顺序
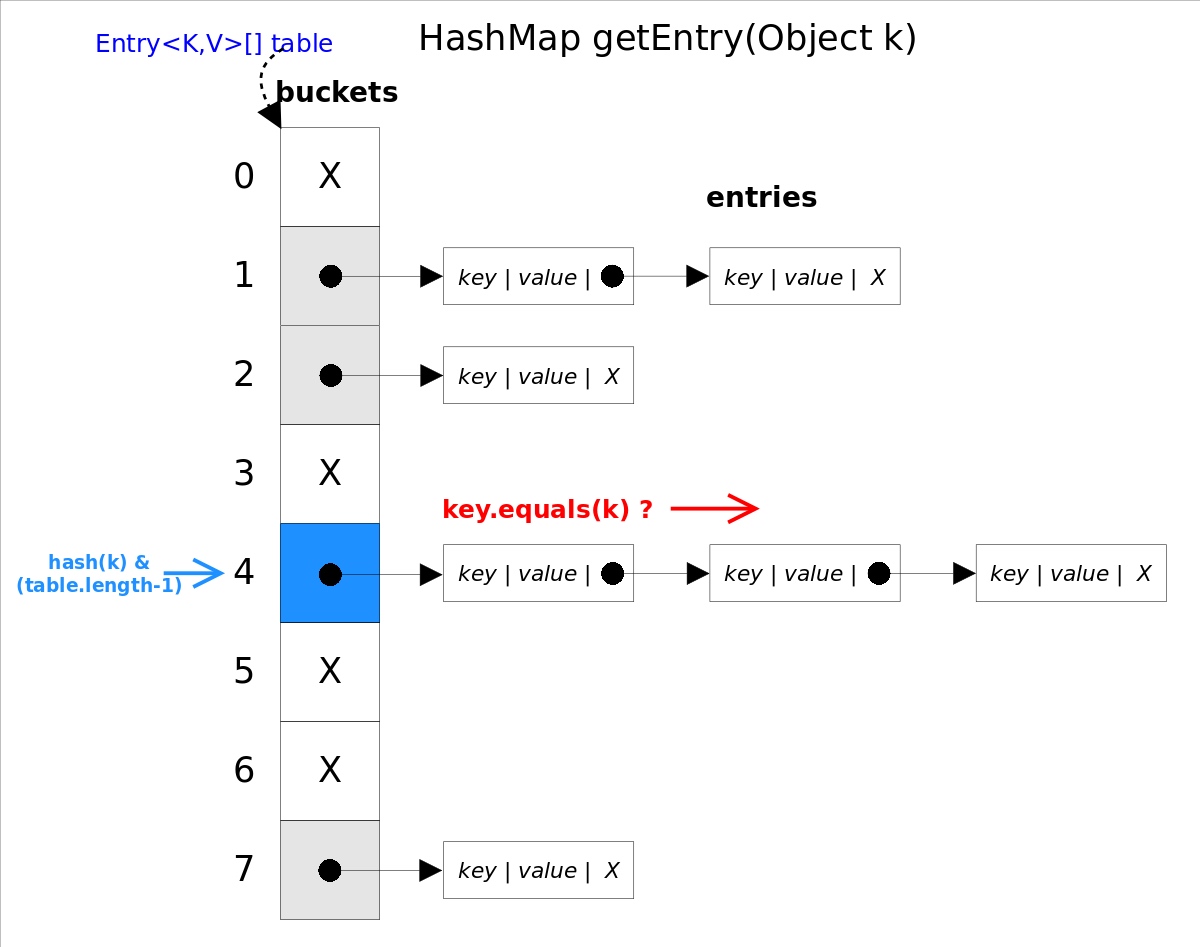
如果有相同的Key,则覆盖
/**
*
* 0: 0.60653066
* 1: 0.30326533
* 2: 0.07581633
* 3: 0.01263606
* 4: 0.00157952
* 5: 0.00015795
* 6: 0.00001316
* 7: 0.00000094
* 8: 0.00000006
**/
HashMap在初始化的时候,如果没有指定 加载因子和容量, 会调用默认的构造函数,将加载因子设为 0.75,容量设为16。当HashMap中的元素个数超过 容量*加载因子时,HashMap会发生扩容。即++size > load factor * capacity ,这个过程发生在放入键值对之后。
每次扩容都会将当前的容量扩大2倍。为什么容量一定要2n其实是因为取余方便。
插入方法上: 1.7采用头插法,1.8采用尾插法。
1.7中hashMap的实现是采用数组+链表的形式,采用头插法容易出现逆序,且在并发情况下会产生环形链表死循环问题
1.8后HashMap则采用数组+链表+红黑树的形式,当链表长度超过8时,则会将链表转成红黑树。且采用尾插法避免了并发情况下发生的死循环问题。但是仍不建议在并发情况下使用HashMap,而是使用ConcurrentHashMap
jdk 1.7中,当扩容完成后,会把数据从老的hash表中迁移到新的hash表中,高并发下,同时有两个或以上线程执行这段代码,会发生链表死循环。具体流程如下:
旧表因容量为2太小发生扩容,新建一个新的哈希表,大小为4
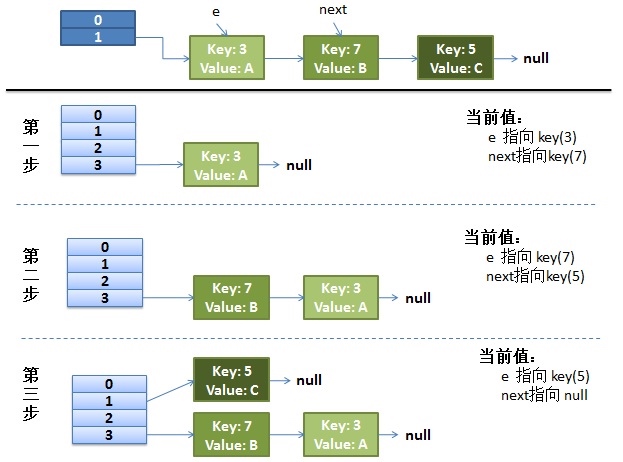
旧表数据向新表逐个迁移
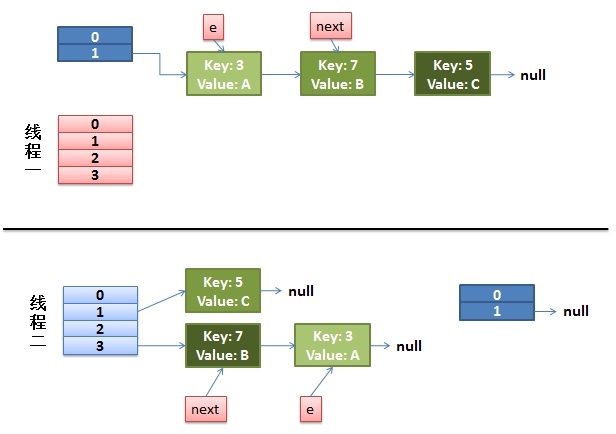
线程1卡在获取旧哈希表的链表上.此时线程1的e指向键值对3,next指向键值对7
而线程2已经完成了整个的数据再分配
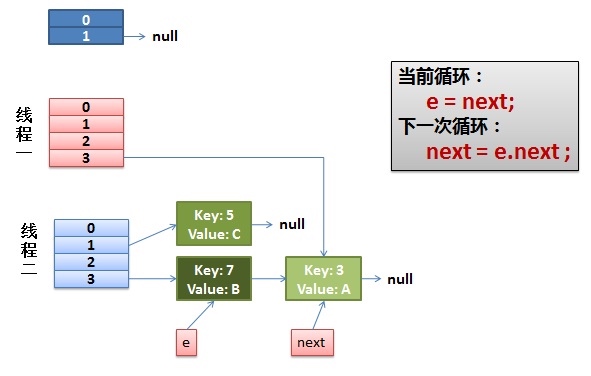
线程1回来继续执行
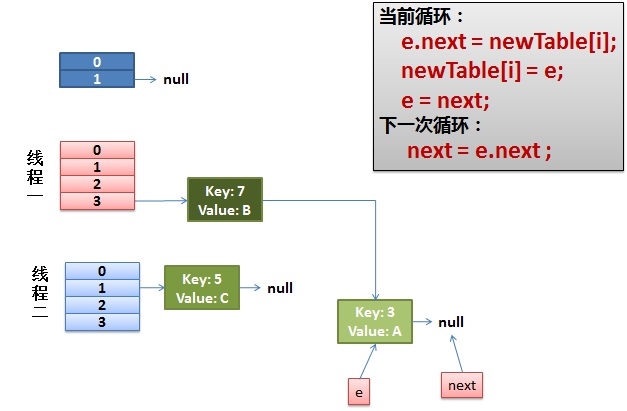
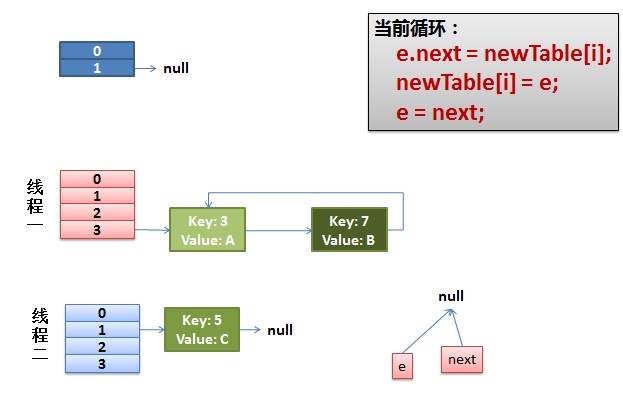
void transfer(Entry[] newTable)
{
Entry[] src = table;
int newCapacity = newTable.length;
//下面这段代码的意思是:
// 从OldTable里摘一个元素出来,然后放到NewTable中
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;// <--假设线程一执行到这里就被调度挂起了
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
原文:https://www.cnblogs.com/LeeBoom/p/hashmap-xiang-jie.html