1 左右为难:MySQL vs MongoDB
1.1 对比一览
| 指标 | MySQL | MongoDB |
|---|---|---|
| 开发语言 | C++,C | C++,C |
| 数据库类型 | SQL | NoSQL(面向文档) |
| Schema | Strict | Dynamic |
| 可扩展性 | 垂直扩展 | 水平扩展 |
| 核心特性 | 全文搜索索引 支持集成复制 触发器 子查询 查询缓存 支持多存储引擎 |
自动分片 本机复制 内存加速 支持嵌套数据模型 辅助索引(Secondary Index) 富查询 多存储引擎 |
| 应用场景 | 表行数据结构 强依赖多行事务 经常更新或修改数据记录 关系型数据集 |
高写负载 不稳定的Schema 数据库预计很大 位置数据 不可靠环境的高可用要求 没有DBA |
| 优势 | 成熟 兼容性 可复制 分片 |
动态模式 可扩展性 以管理 速度 灵活性 |
1.2 从使用看对比
1.2.1 文档数据类型:字段结构更丰富
MongoDB的数据类型非常丰富,BSON/JSON结构,可以表示任意结构的数据。
MySQL的数据类型相对贫瘠,行列结构,层级结构数据需要拆表、联立表示,复杂了数据管理方式。除此之外,业务数据与DB数据需要ORM来完成映射表示,代码复杂度较高。
1.2.2 Schema:让数据更灵活
MongoDB是动态Schema,无需预先定义Collection结构;而MySQL是静态Schema,需要预先定义Table结构。举例来说,如果我们的数据时效性以一个月为限,很少会追溯过期数据,我们更希望将表以时间为划分依据,如Data-201901、Data-201902等,这在MongoDB中可以轻易实现,而如果在MySQL中则要复杂许多,要么动态执行Create Table语句,要么将数据放在一起。在之前写过的Slowlog管理系统中,因为数据量较大,采用MySQL存储数据时,需要定时任务去定期归档数据,代码复杂度搞。
MongoDB是NoStrict Schema,同一Collection的文档结构允许不同;而MySQL是Strict Schema,同一Table的字段结构必须相同。因此,为了实现复杂的数据结构,MySQL常常会将一个业务结构拆成多张表表示,也会通过空字段处理,即有的记录的字段有值,有的是空值。非强制性Schema最大的好处就是支持业务变化、代码重构,尤其是业务不稳定阶段,表(集合)结构经常变化,但又害怕数据丢失,因此只能不断加字段,导致一张表中会有很多无效字段,而在非强制Schema中,每条记录(文档)的结构都可以不一样,因此新变化对老数据无侵害。
1.2.3 事务管理:MongoDB的短板
事务管理是MongoDB的软肋,目前v4.2版本已经推出了事务功能,但事务操作必须针对已存在的集合(Existing Collection)。
2 MongoDB常见操作
2.1 查看库表
show dbs // 列举MongoDB实例的数据库show collections // 列举当前库下的所有集合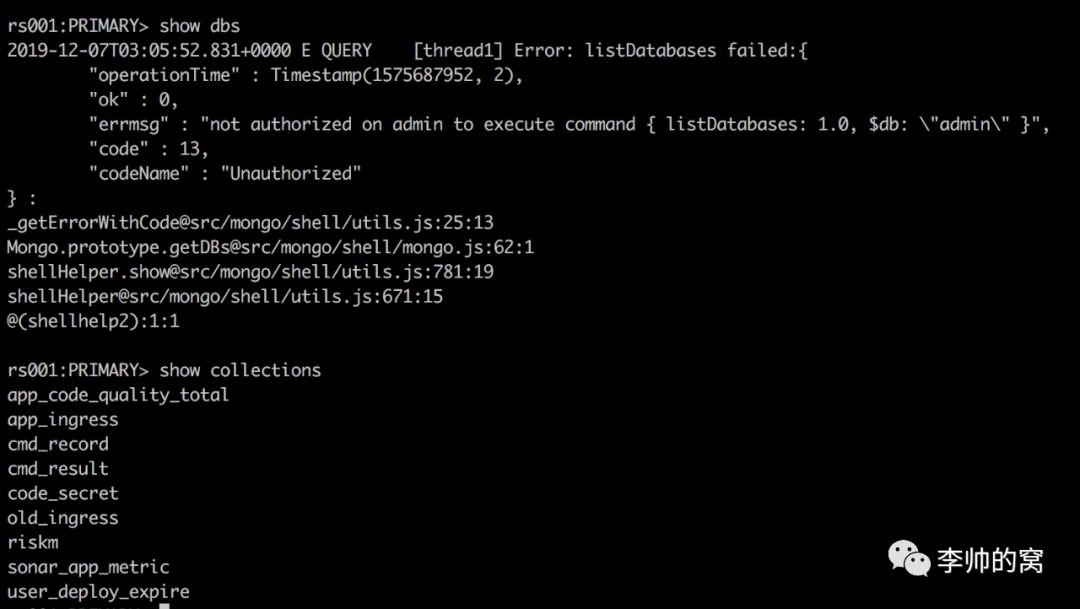
2.2 查看表数据
MongoDB的查询语法比较丰富,既有普通文档的条件查询,还有嵌入文档、数组字段的查询,具体语法可以参见官网https://docs.mongodb.com/manual/tutorial/query-documents/,MongoDB的文档除了讲解说明外,还有交互终端,用户可以自由使用。
无论是何种查询,最终都离不开两个问题:(1)查询条件是什么?(2)查询结果又是什么样子的?
2.2.1 查询表达式(Query Selector)

如上是MongoDB的一些操作符,通过这些操作符和字段、值的联立组合,可以形成复杂的查询条件。
假设,我们要在部署记录集合(deploy_record)中查询用户(sli4)、在12月部署的失败(Failure)和取消(Cancel)的记录:
db.deploy_record.find({user:"sli4", date: {"gte": ISODate("2019-12-01T00:00:00Z), "lt": ISODate("2020-01-01T00:00:00Z) }, status:{$in: ["Failure", "Cancel"]} })很多技术内容,光看文档是无法真正领会的,需要有真实的操作场景,才能碰到自己想不到的问题。本想写一篇概括性、总结文章,可以一页指北,却发现,只能提供概要性说明,具体实践过程,还是要面向文档和Google编程!
2.2.2 投射
投射,就是SQL中的字段选择。MongoDB默认返回符合查询条件文档的全部字段,为了限制MongoDB返回的数据量,可以通过投射表达式选择需要的字段。
db.collection.find({查询条件},{投射表达式})投射表达式,就是为指定字段设定是否返回标识,1标识返回,0标识不返回。如部署记录(deploy_record)只返回应用(app)、状态(status):
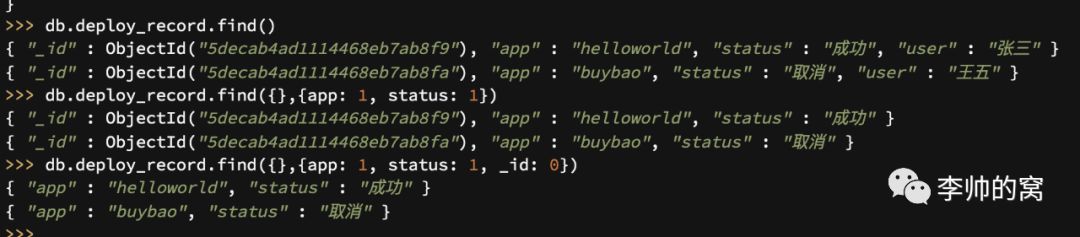
注意:MongoDB默认是返回主键(_id),因此如果不需要主键时,需要显示指定_id:0。
2.2.3 聚合
Aggregation operations process data records and return computed results.聚合操作通过数据分组、针对分组数据执行一系列操作、最终生成单一计算结果值。聚合提供Pipeline、MapReduce、Methods三种方式。聚合操作可以简化应用层的业务逻辑,在数据层提取需要的数据值。
因为聚合比较重要,也很复杂,我们将在下面另起一个模块讲解说明。
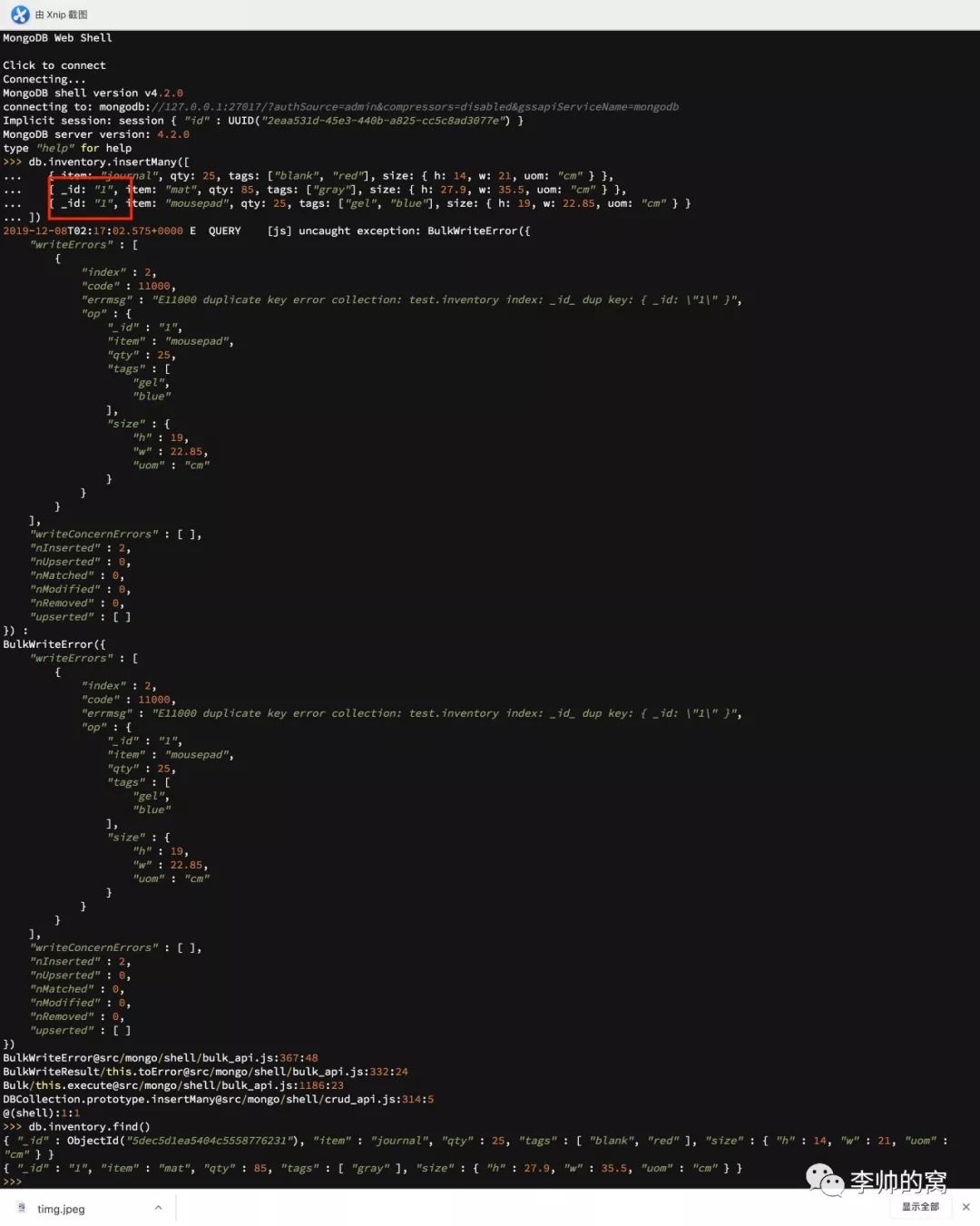
2.3 创建数据:insert
db.collection.insertOne() // 插入单一文档db.collection.insertMany() // 插入多个文档db.collection.insert() // 插入一个或多个文档MongoDB的数据插入行为有三点内容需要明确:
如果插入数据时,集合尚未存在,insert操作会触发集合创建。
mongodb中每个文档都是以_id作为主键,如果插入的文档中没有指定_id,mongodb会默认分配唯一ID。
无论插入一个还是多个文档,mongodb都是以单一文档为原子性维度,即插入过程中如遇错误,只影响正在插入的文档,不影响已经成功的文档,不会回退至插入操作前的状态。
2.4 修改操作
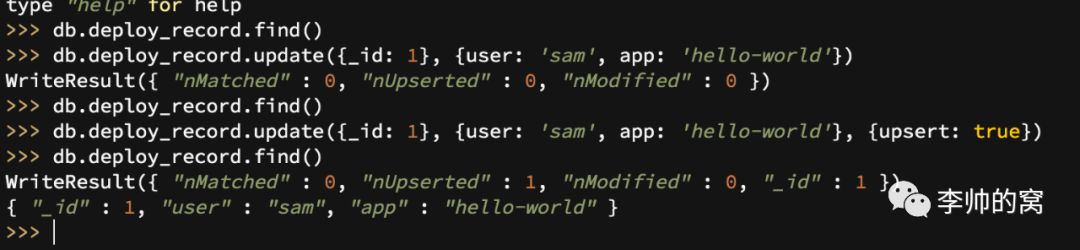
// 修改操作的命令格式{ <update operator> : { <field1>:<value1>, ... }, <update operator> : { <field1>:<value1>, ... }, ...}2.4.1 修改还是替换

上图的两个操作,一个是替换,一个是字段更新,在没有$set更新操作符时,是以新值替代旧值;而有$set时则只针对指定字段更新。
db.deploy_record.update({_id: 1}, {user: "王五"})db.deploy_record.update({_id: 1}, {$set: {user: "王五"}})2.4.2 更新操作注意事项
_id字段不可更改
upsert操作:当upsert为true时,如果没有匹配的文档可供修改,会将更新文档作为新文档插入集合。
2.4.3 还有更多操作符,具体使用结合文档和场景
https://docs.mongodb.com/manual/reference/operator/update/
2.5 删除操作
db.collection.delete({查询表达式})3. MongoDB的高级操作--聚合
3.1 Pipeline
3.2 MapReduce
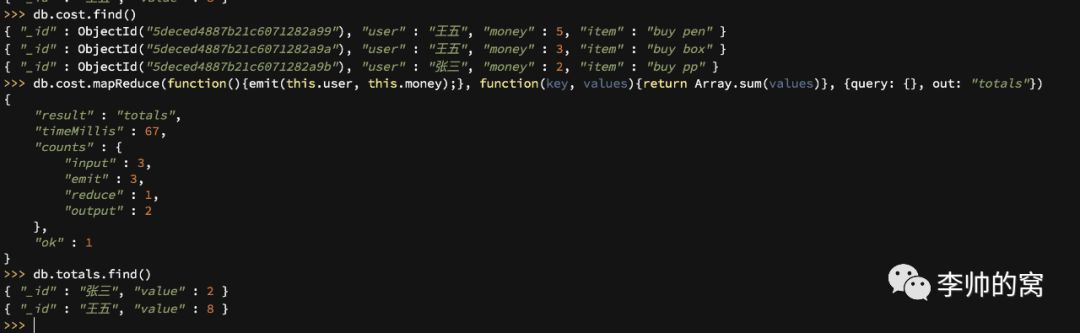
MapReduce是大数据处理模型,通过map和reduce两个阶段获取理想的数据结果:
Map:通过map函数提取一组kv对,每个key都有多个value,准确的说是key-values。
Reduce:通过reduce函数,以key为组,分组计算求得结果。
在MongoDB中,MapReduce的命令格式如下:除了提供map、reduce函数外,还需要指定数据的筛选条件(query)和数据结果的保存集合(out)
{ function map(){}, function reduce(key, values){}, { query: {查询表达式}, out: 输出集合 }}
很多PHPer在进阶的时候总会遇到一些问题和瓶颈,业务代码写多了没有方向感,不知道该从那里入手去提升,对此我整理了一些资料,包括但不限于:分布式架构、高可扩展、高性能、高并发、服务器性能调优、TP6,laravel,YII2,Redis,Swoole、Swoft、Kafka、Mysql优化、shell脚本、Docker、微服务、高并发、Nginx等多个知识点高级进阶干货需要的可以免费分享给大家。进入网址领取资料https://docs.qq.com/doc/DWkZTQVZCbUN0VUxL
转载至https://my.oschina.net/u/4621641/blog/4517354
https://my.oschina.net/u/4621641/blog/4517354
原文:https://www.cnblogs.com/sixstarphp/p/14529402.html