使用上述命令行工具或组合能帮您获取目标 Java 应用性能相关的基础信息,但它们存在下列局限:
为此,JDK提供了一些内存泄漏的分析工具,如jconsole、jvisualvm等,用于辅助开发人员定位问题,但是这些工具很多时候并不足以满足快速定位的需求。所以这里我们介绍的工具相对多一些、丰富一些。
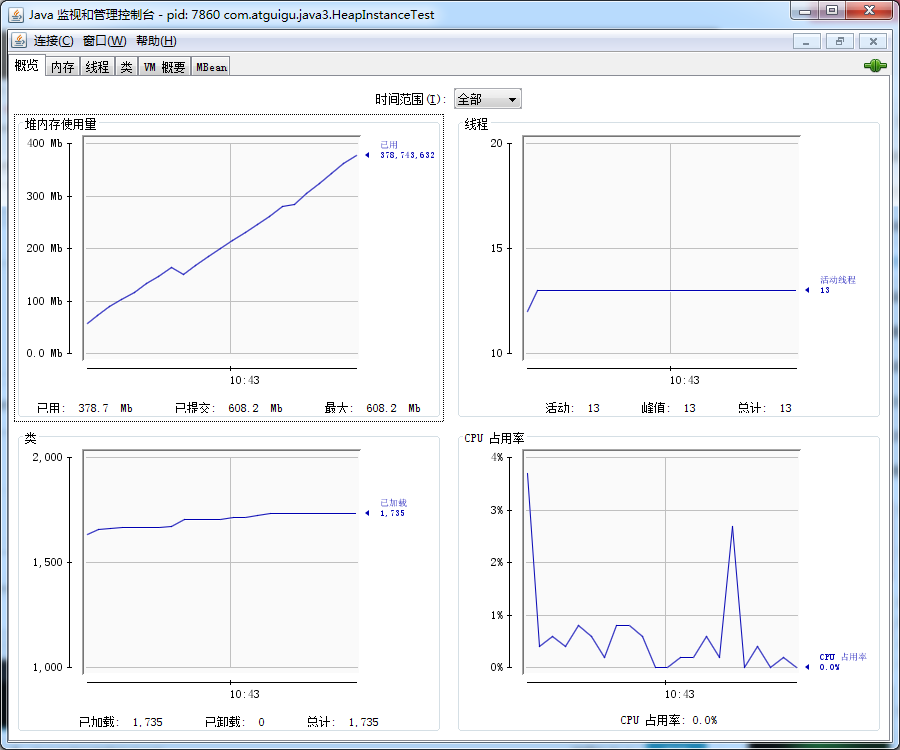
jconsole:JDK自带的可视化监控工具。查看Java应用程序的运行概况、监控堆信息、永久区(或元空间)使用情况、类加载情况等
Visual VM:Visual VM是一个工具,它提供了一个可视界面,用于查看Java虚拟机上运行的基于Java技术的应用程序的详细信息。
JMC:Java Mission Control,内置Java Flight Recorder。能够以极低的性能开销收集Java虚拟机的性能数据。
MAT:MAT(Memory Analyzer Tool)是基于Eclipse的内存分析工具,是一个快速、功能丰富的Java heap分析工具,它可以帮助我们查找内存泄漏和减少内存消耗
JProfiler:商业软件,需要付费。功能强大。
Arthas:Alibaba开源的Java诊断工具。深受开发者喜爱。
Btrace:Java运行时追踪工具。可以在不停机的情况下,跟踪指定的方法调用、构造函数调用和系统内存等信息。
从Java5开始,在JDK中自带的java监控和管理控制台。
用于对JVM中内存、线程和类等的监控,是一个基于JMX(Java Management Extensions)的GUI性监控工具。
官方教程:https://docs.oracle.com/javase/7/docs/technotes/guides/management/jconsole.html
在jdk安装目录中找到jconsole.exe,双击该可执行文件就可以
打开DOS窗口,直接输入jconsole就可以了
使用JConsole连接一个正在本地系统运行的JVM并且执行程序的和运行JConsole的需要是同一个用户。JConsole使用文件系统的授权通过RMI连接器连接到平台的MBean服务器上。
这种从本地连接的监控能力只有Sun的JDK具有。
使用下面的URL通过RMI连接器连接到一个JMX代理,service:jmx:rmi://jndi/rmi://hostName:portNum/jmxrmi。
JConsole为建立连接,需要在环境变量中设置mx.remote.credentials来指定用户名和密码,从而进行授权。
使用一个特殊的URL连接JMX代理。一般情况使用自己定制的连接器而不是RMI提供的连接器来连接JMX代理,或者是一个使用JDK1.4的实现了JMX和JMX Rmote的应用。
package com.atguigu.java3;
import java.util.ArrayList;
import java.util.Random;
/**
* -Xms600m -Xmx600m -XX:SurvivorRatio=8
*/
public class HeapInstanceTest {
byte[] buffer = new byte[new Random().nextInt(1024 * 100)];
public static void main(String[] args) {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
ArrayList<HeapInstanceTest> list = new ArrayList<>();
while (true) {
list.add(new HeapInstanceTest());
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
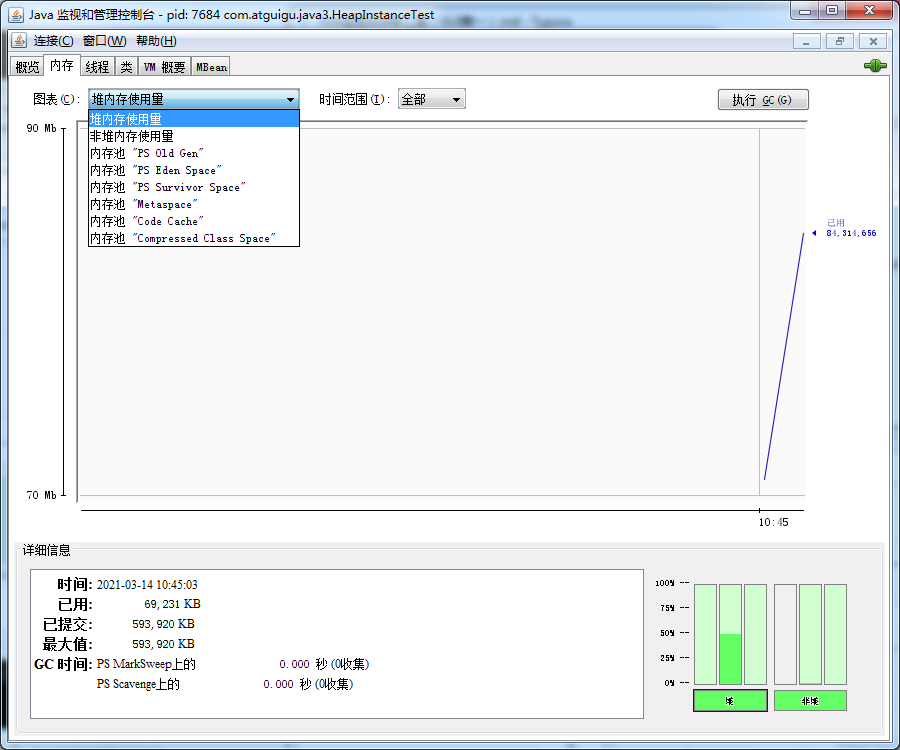
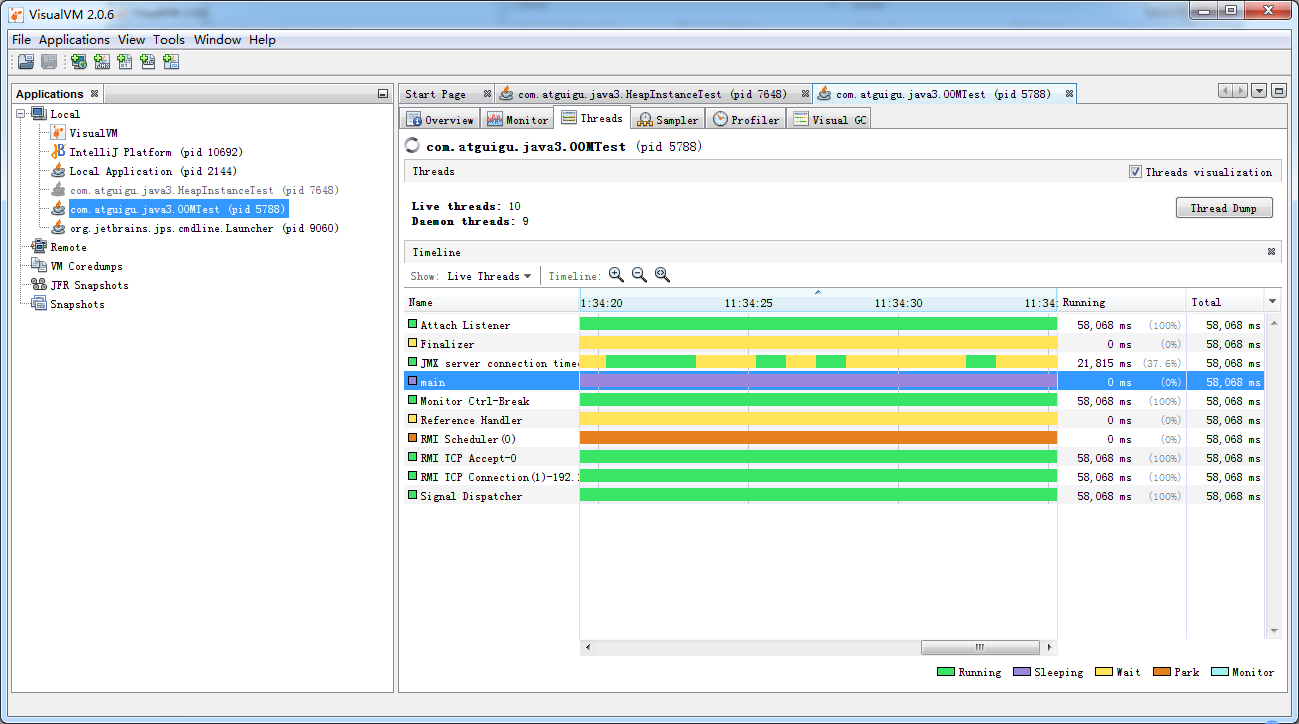
检查堆内存的使用量,能够看不同区的分配情况
线程信息
类加载
VM信息
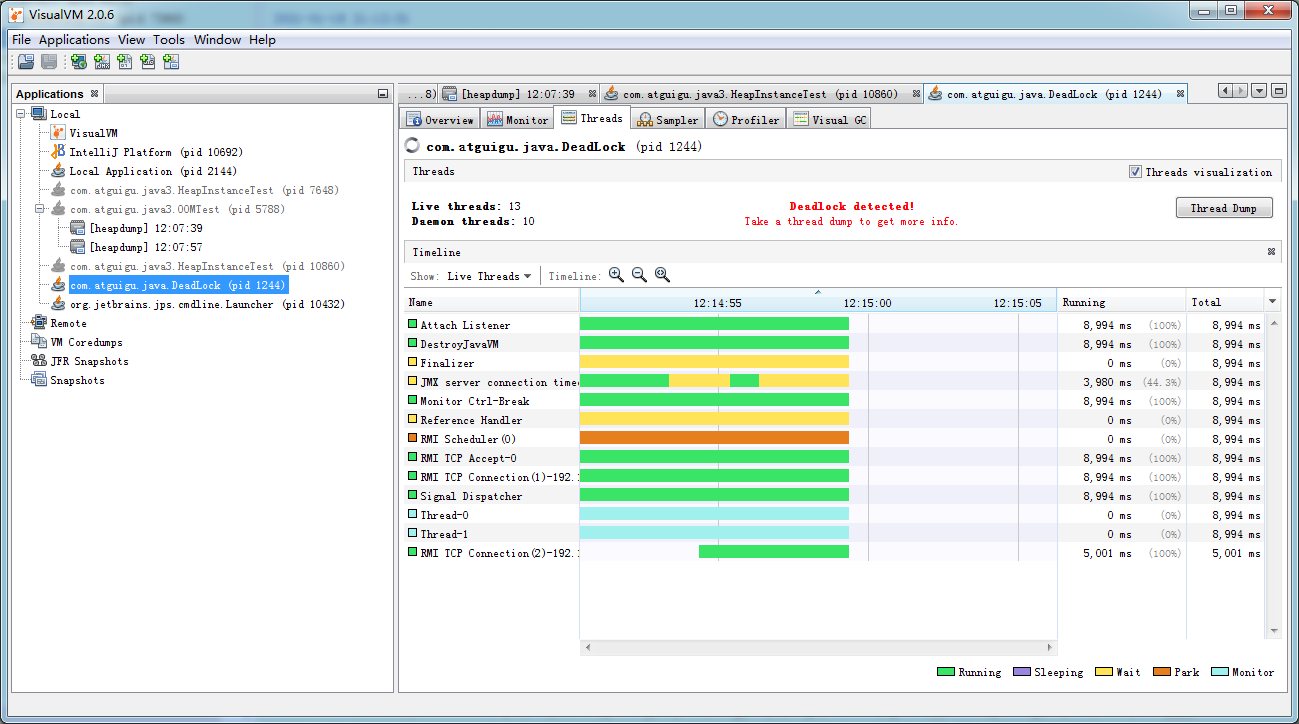
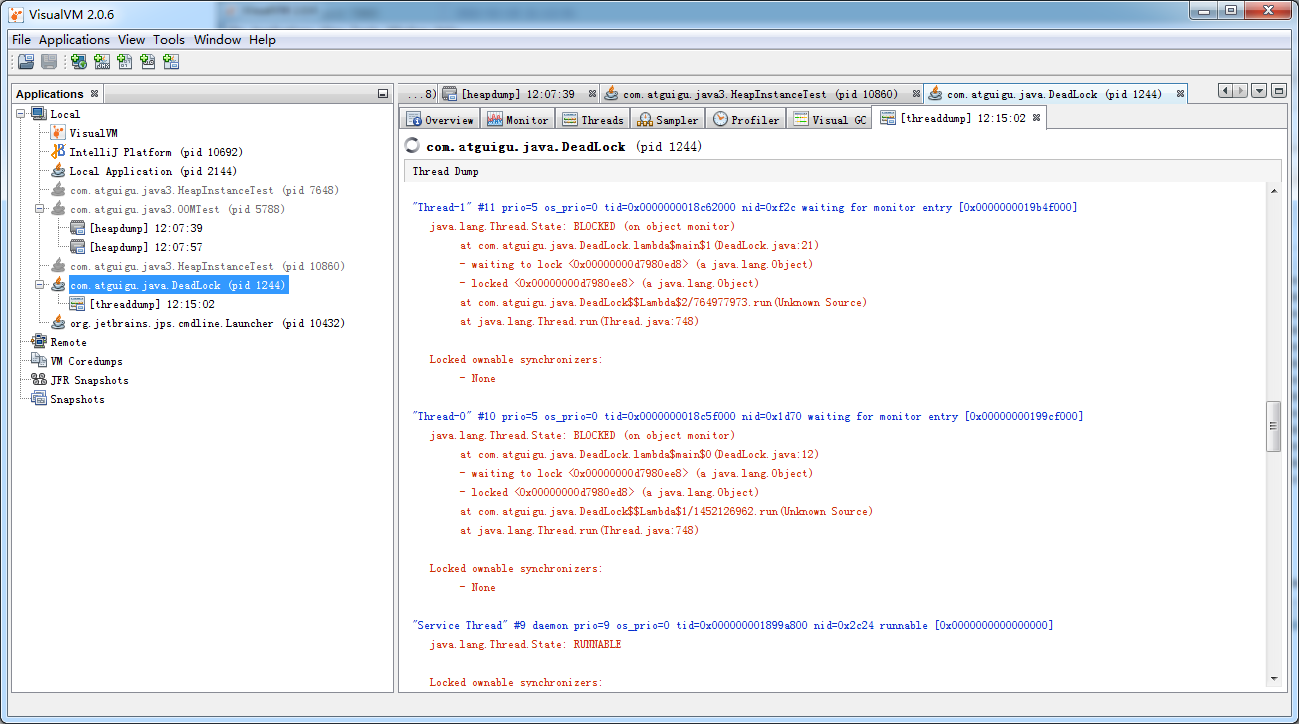
死锁检测
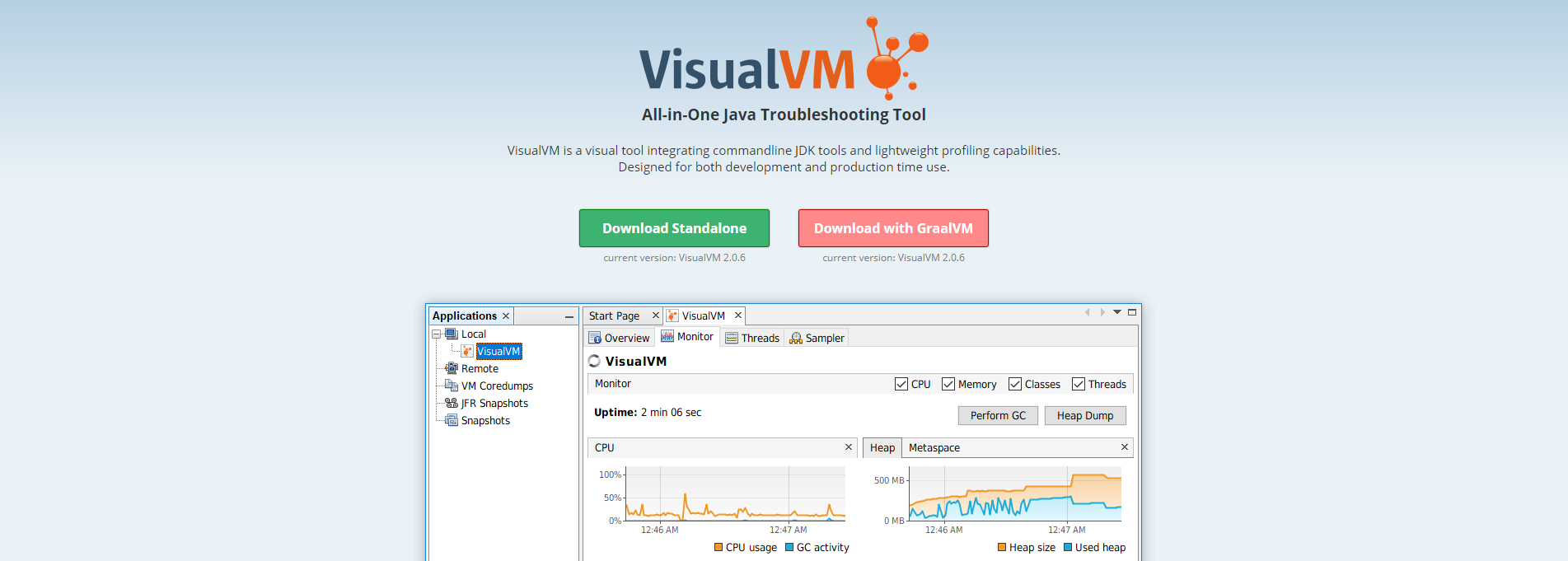
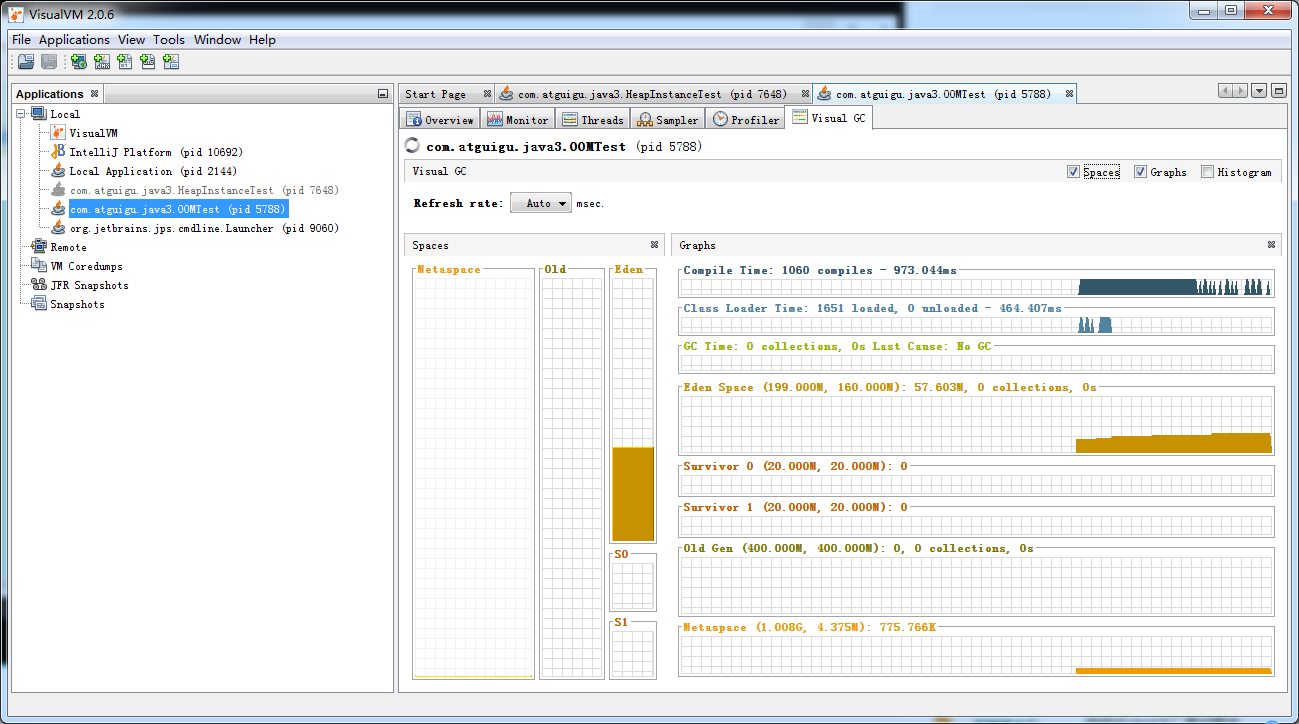
Visual VM是一个功能强大的多合一故障诊断和性能监控的可视化工具。
它集成了多个JDK命令行工具,使用Visual VM可用于显示虚拟机进程及进程的配置和环境信息(jps、jinfo),监视应用程序的CPU、GC、堆、方法区及线程的信息(jstat、jstack)等,甚至代替JConsole
在JDK 6 Update 7以后,Visual VM便作为JDK的一部分发布(VisualVM在JDK/bin目录下),即:它完全免费
此外,Visual VM也可以作为独立的软件安装
首页:https://visualvm.github.io/index.html
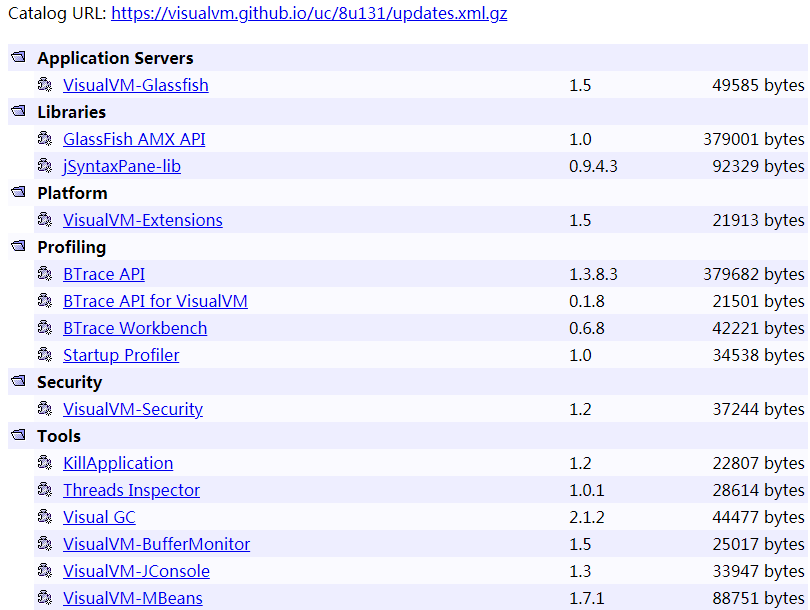
Visual VM的一大特点是支持插件扩展,并且插件安装非常方便。我们既可以通过离线下载插件文件*.nbm,然后在Plugin对话框的已下载页面下,添加已下载的插件。也可以在可用插件页面下,在线安装插件。(这里建议安装上:VisualGC)
插件地址:https://visualvm.github.io/pluginscenters.html
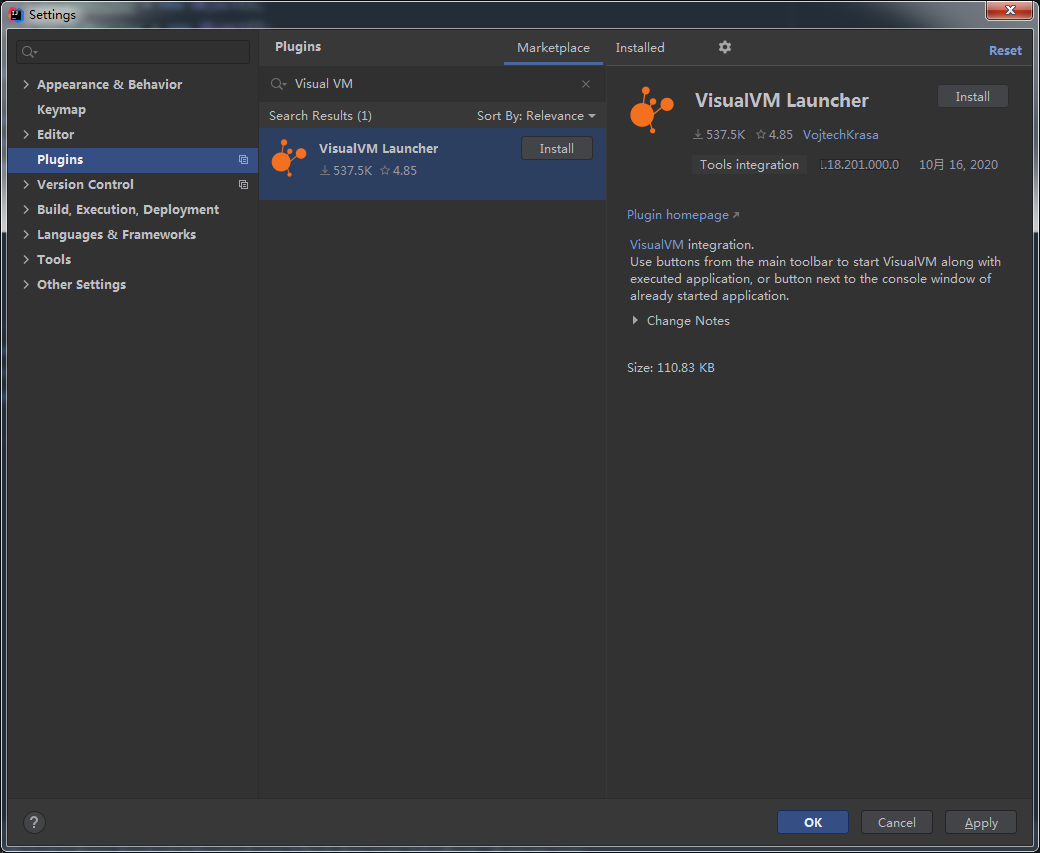
Preferences→Plugins→搜索VisualVM Launcher,安装重启即可。

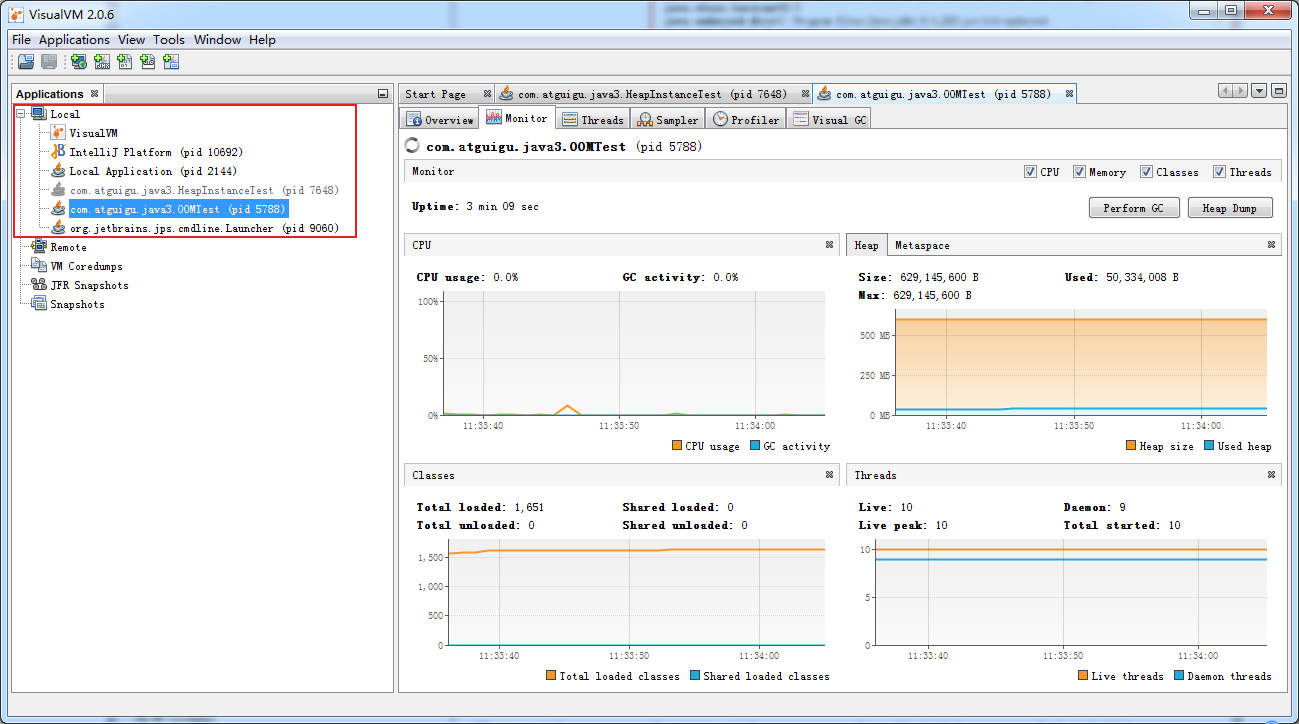
监控本地Java进程的CPU、类、线程等
package com.atguigu.java3;
import java.util.ArrayList;
import java.util.Random;
public class OOMTest {
public static void main(String[] args) {
ArrayList<Picture> list = new ArrayList<>();
while (true) {
try {
Thread.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
list.add(new Picture(new Random().nextInt(10 * 50)));
}
}
}
class Picture {
private byte[] pixels;
public Picture(int length) {
this.pixels = new byte[length];
}
}
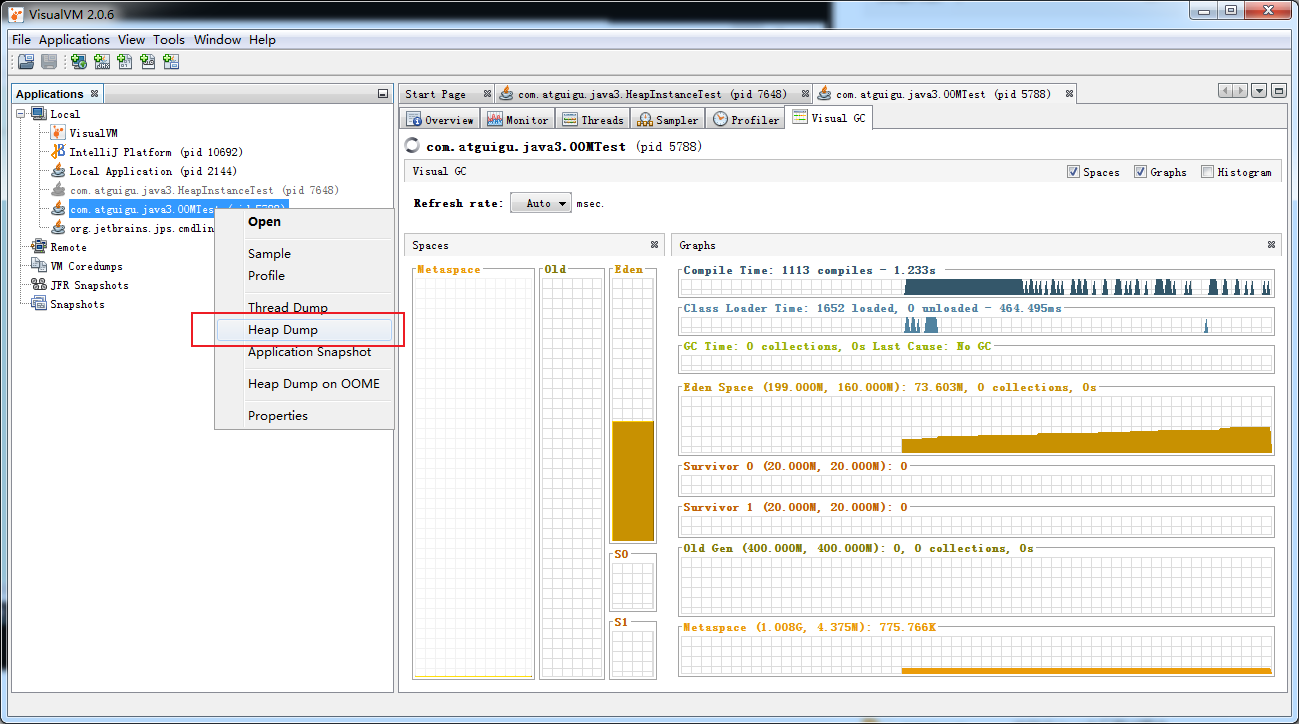
方式1:
方式二:
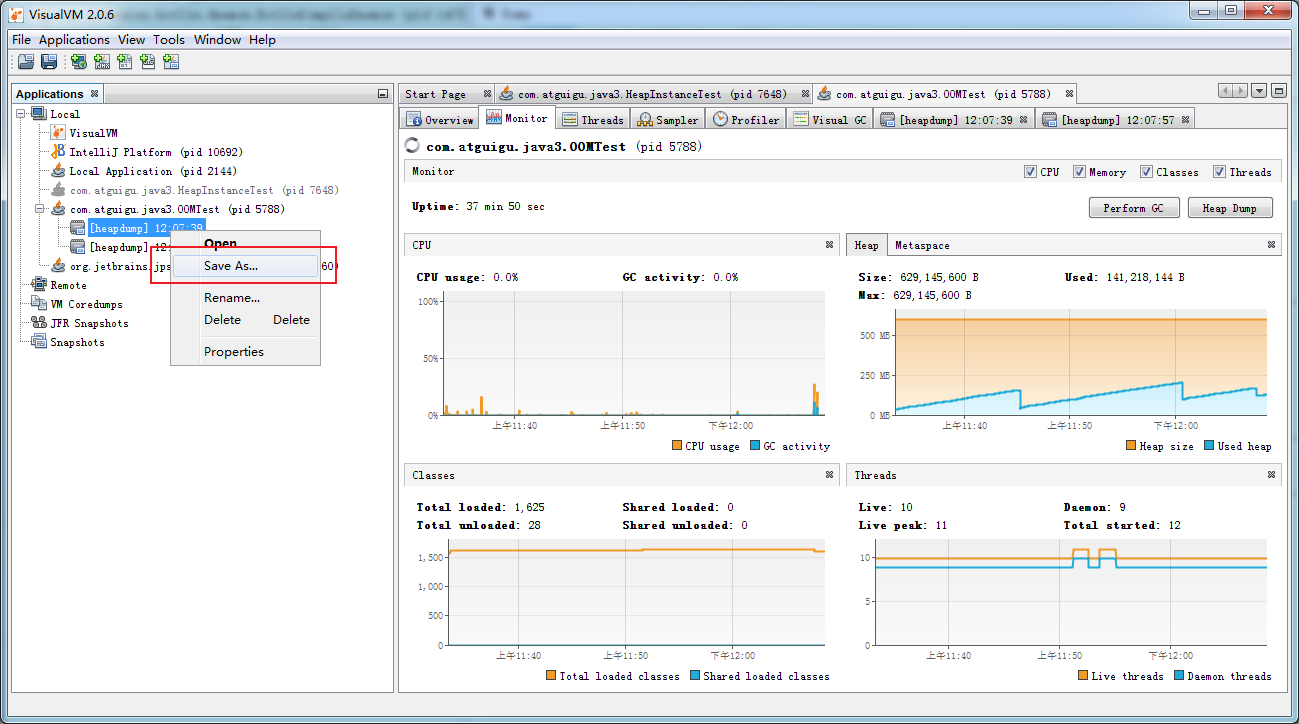
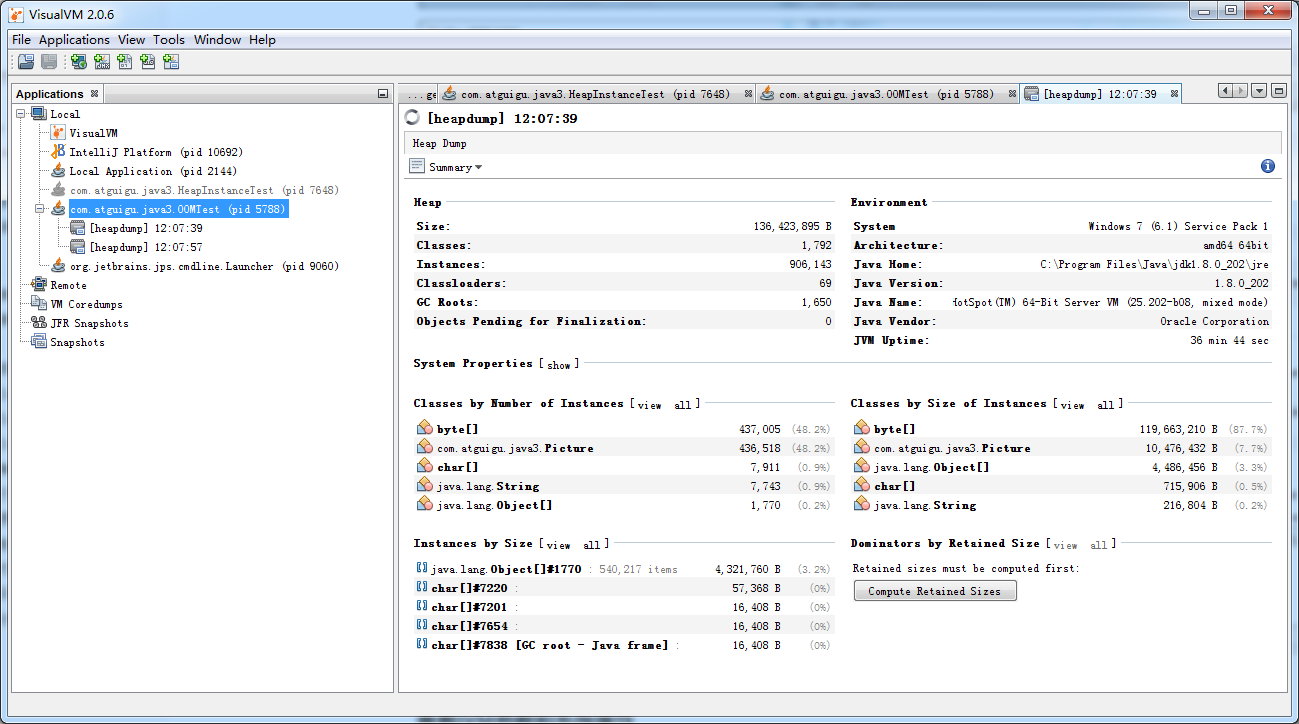
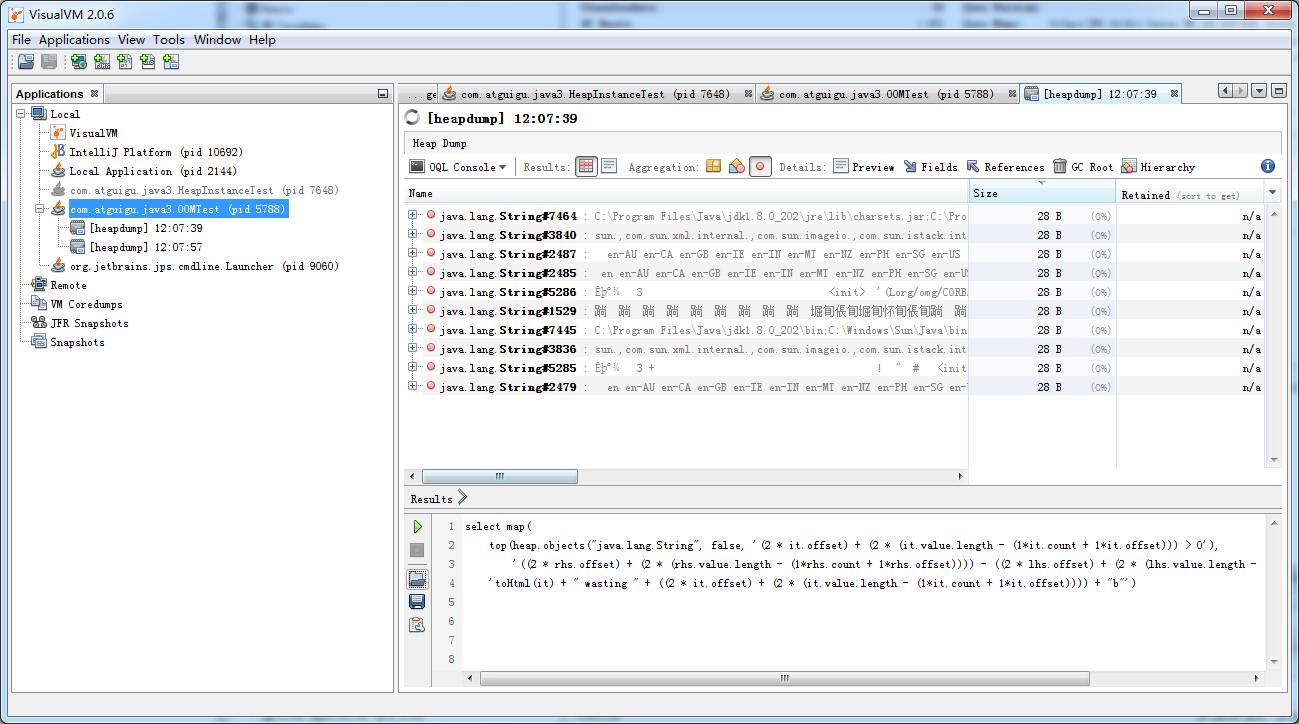
OQL查询
死锁检测
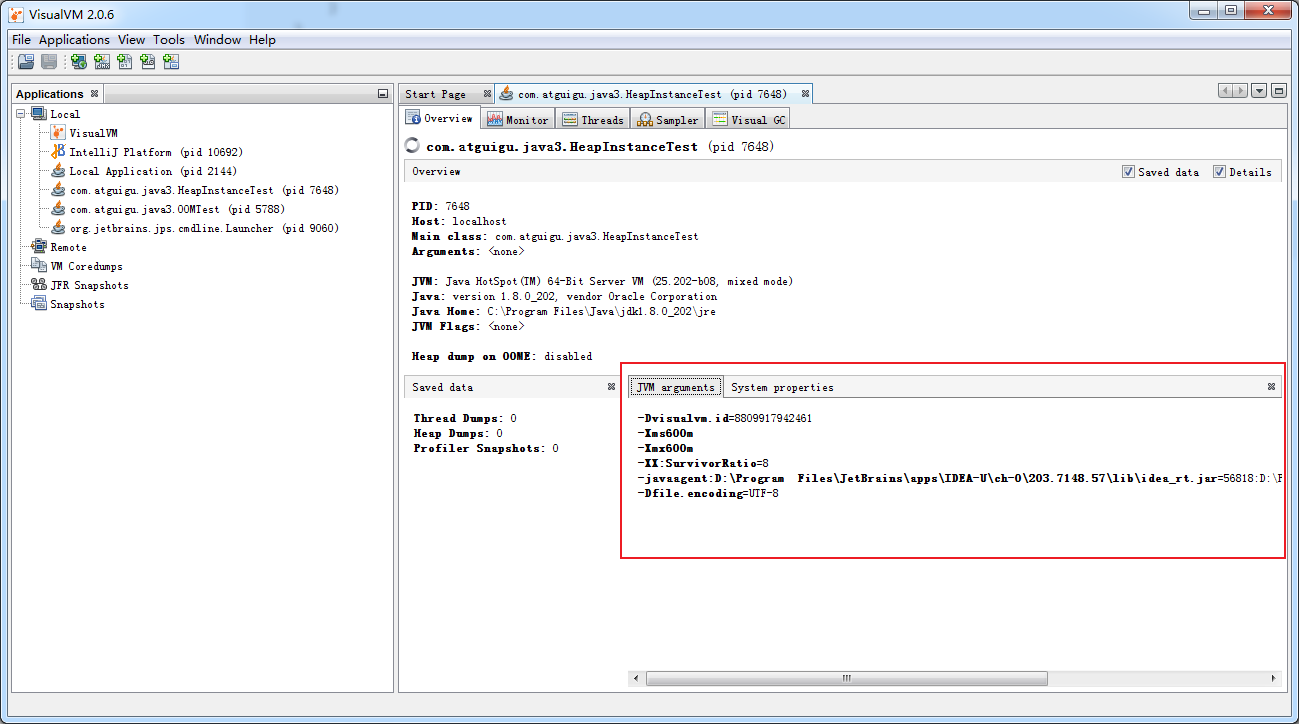
JVM参数
系统属性
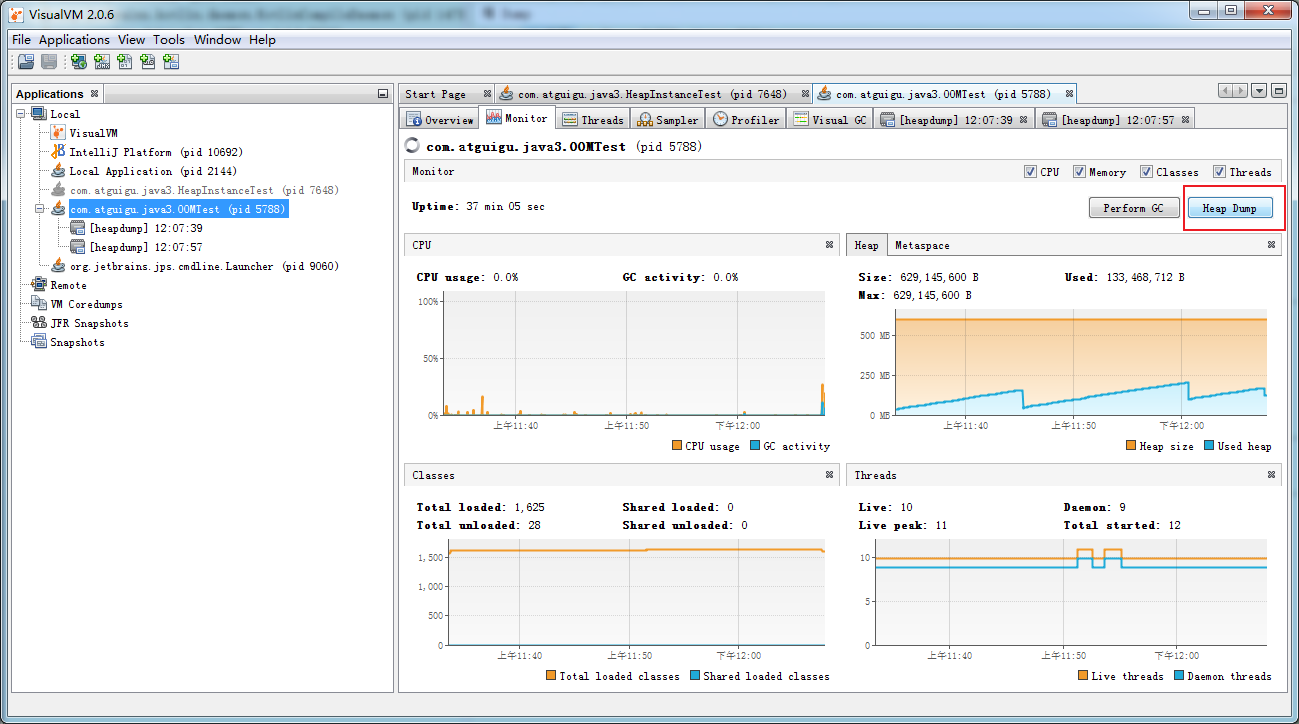
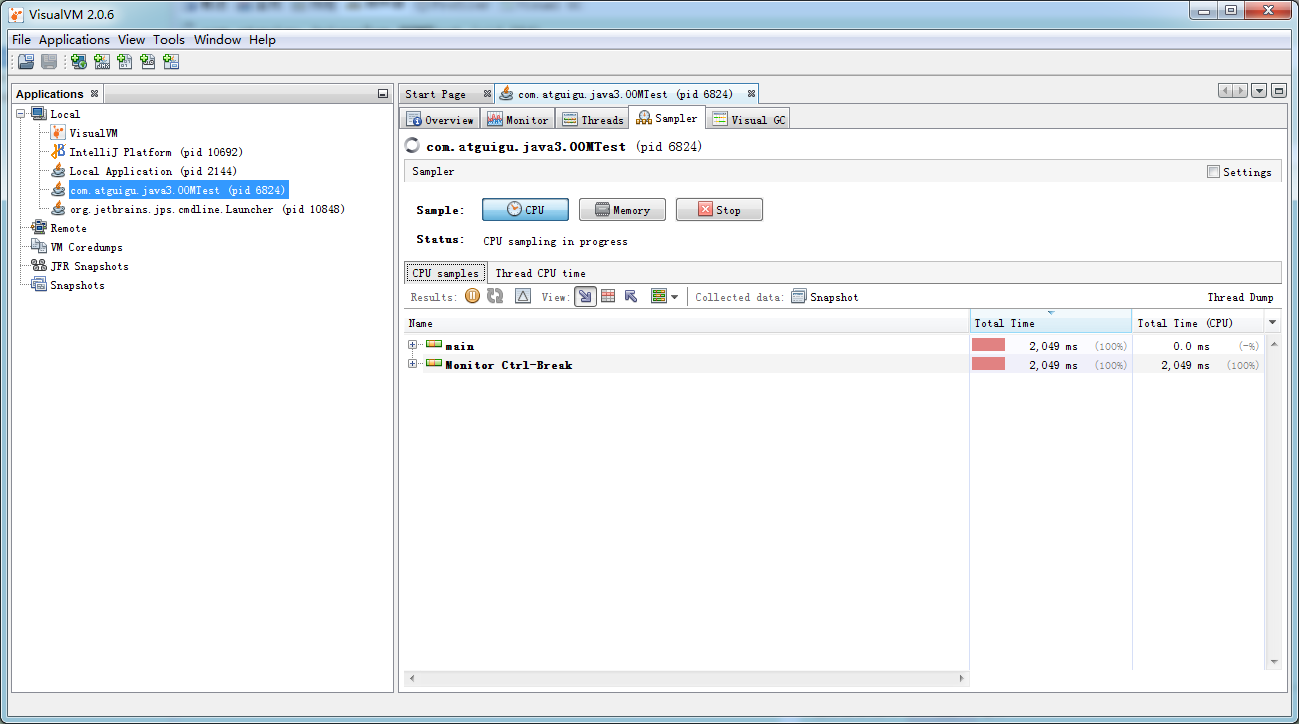
CPU采样,可以看到对CPU占用比较长的方法
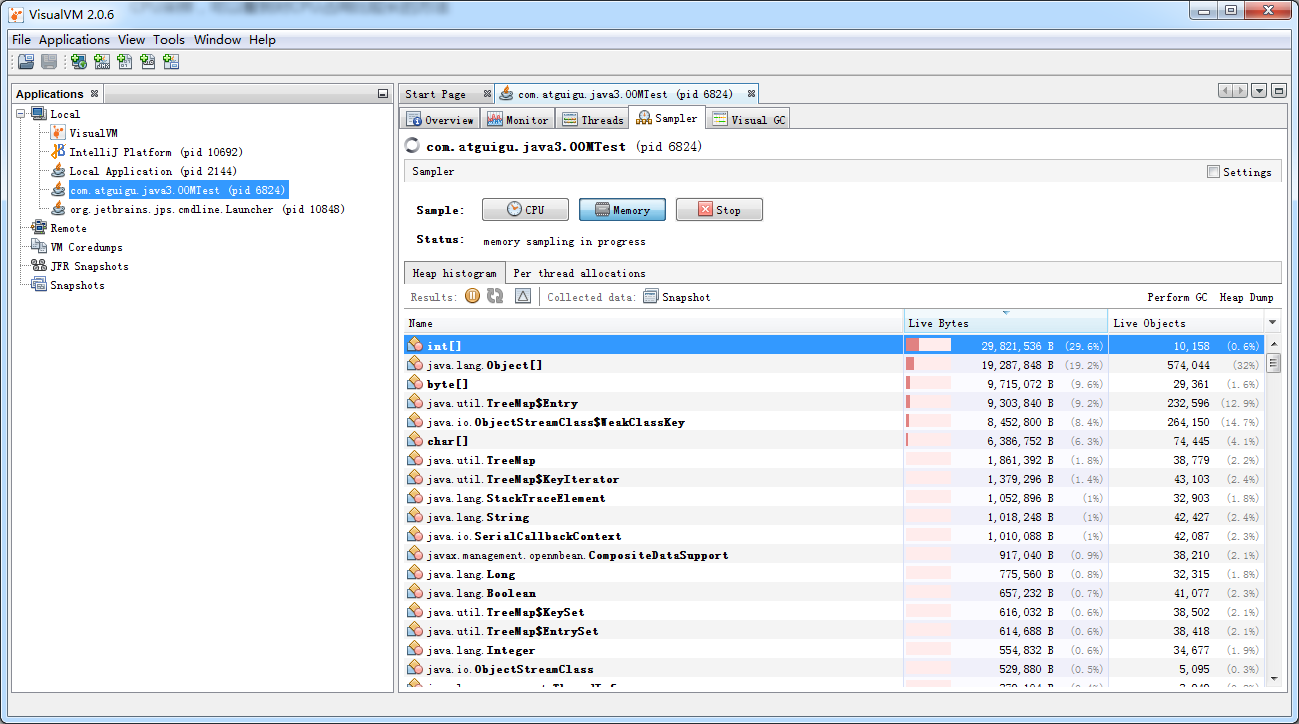
内存采样,可以看到哪些结构的实例数和占用的字节数
MAT(Memory Analyzer Tool)工具是一款功能强大的Java堆内存分析器。可以用于查找内存泄漏以及查看内存消耗情况。
MAT是基于Eclipse开发的,不仅可以单独使用,还可以作为插件的形式嵌入在Eclipse中使用。是一款免费的性能分析工具,使用起来非常方便。大家可以在https://www.eclipse.org/mat/downloads.php下载并使用MAT。
只要确保机器上装有JDK并配置好相关的环境变量,MAT可正常启动。
还可以在Eclipse中以插件的方式安装:
MAT可以分析heap dump文件。在进行内存分析时,只要获得了反映当前设备内存映像的hprof文件,通过MAT打开就可以直观地看到当前的内存信息。
一般说来,这些内存信息包含:
说明1 缺点:
不是万能工具,它并不能处理所有类型的存储文件。但是比较主流的厂家和格式,例如Sun、HP、SAP所用的HPROF二进制存储文文件,以及IBM的PD堆存储文件等都能良好的解析
说明2:
最吸引是能内存泄露报表,方便定位问题和分析问题。虽然MAT有如此强大的功能,但是内存分析没有简单到一键完成的的程度,很多内存问题还是需要从MAT展现给我们信息当中通过经验直觉来判断i才能能发现。
方法一:通过前一章介绍的jmap工具生成,可以生成任意一个java进程的dump文件;
方法二:通过配置JVM参数生成。
对比:考虑到生产环境中几乎不可能在线对其进行分析,大都是采用离线分析,因此使用jmap+MAT工具是最常见的组合。
方法三:使用VisualVM可以导出堆dump文件
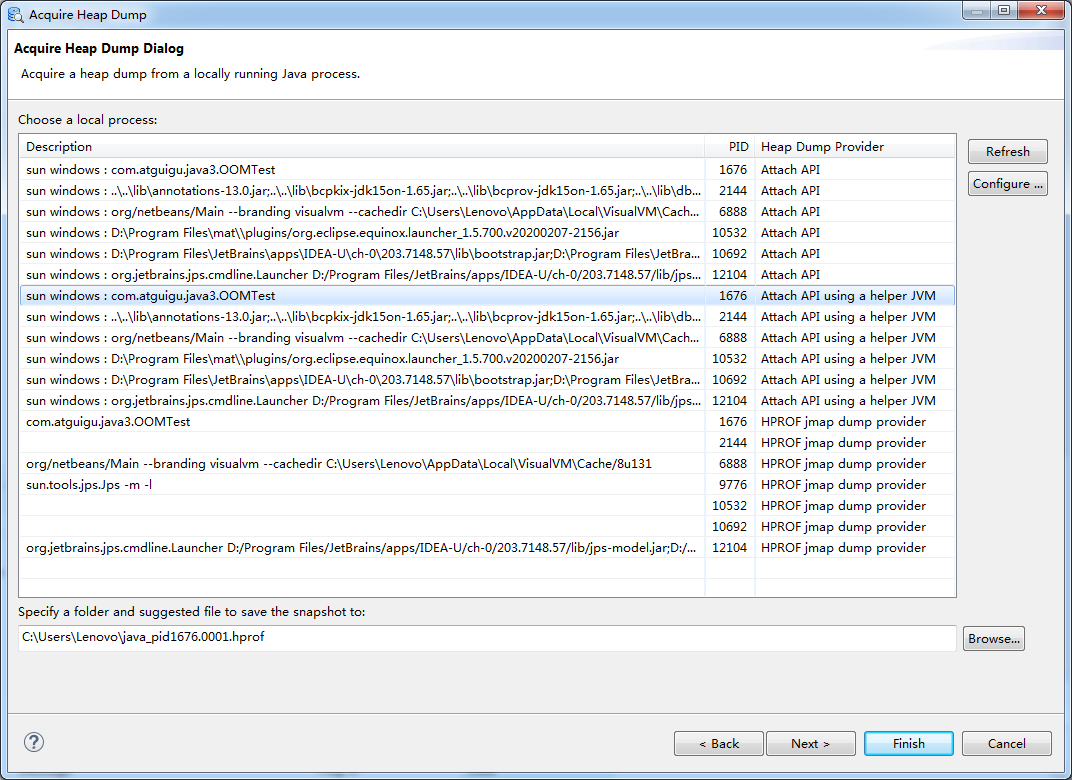
方法四:使用MAT既可以打开一个已有的堆快照,也可以通过MAT直接从活动Java程序中导出堆快照。该功能将借助jps列出当前正在运行的Java进程,以供选择并获取快照。
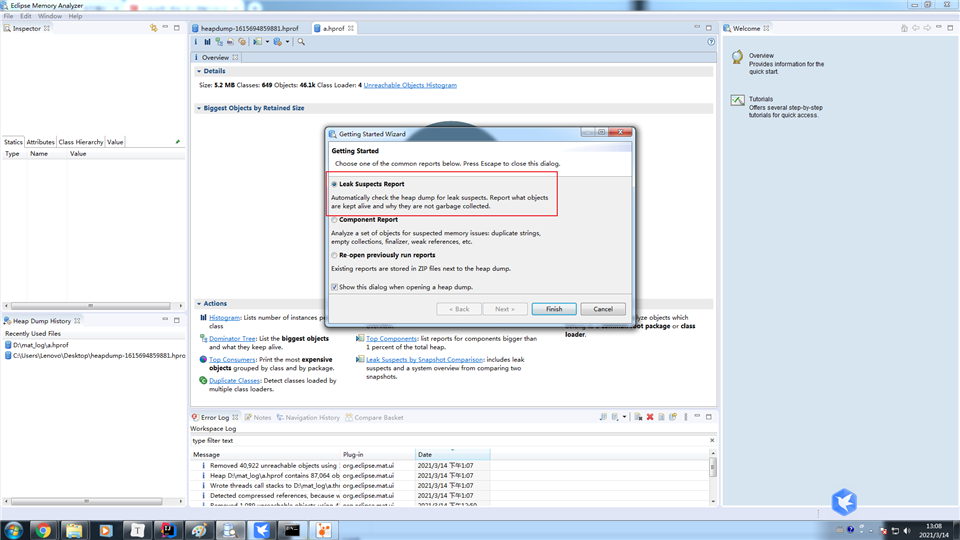
选择Leak Suspects Report
在dump文件目录下回发现一个a_Leak_Suspects.zip
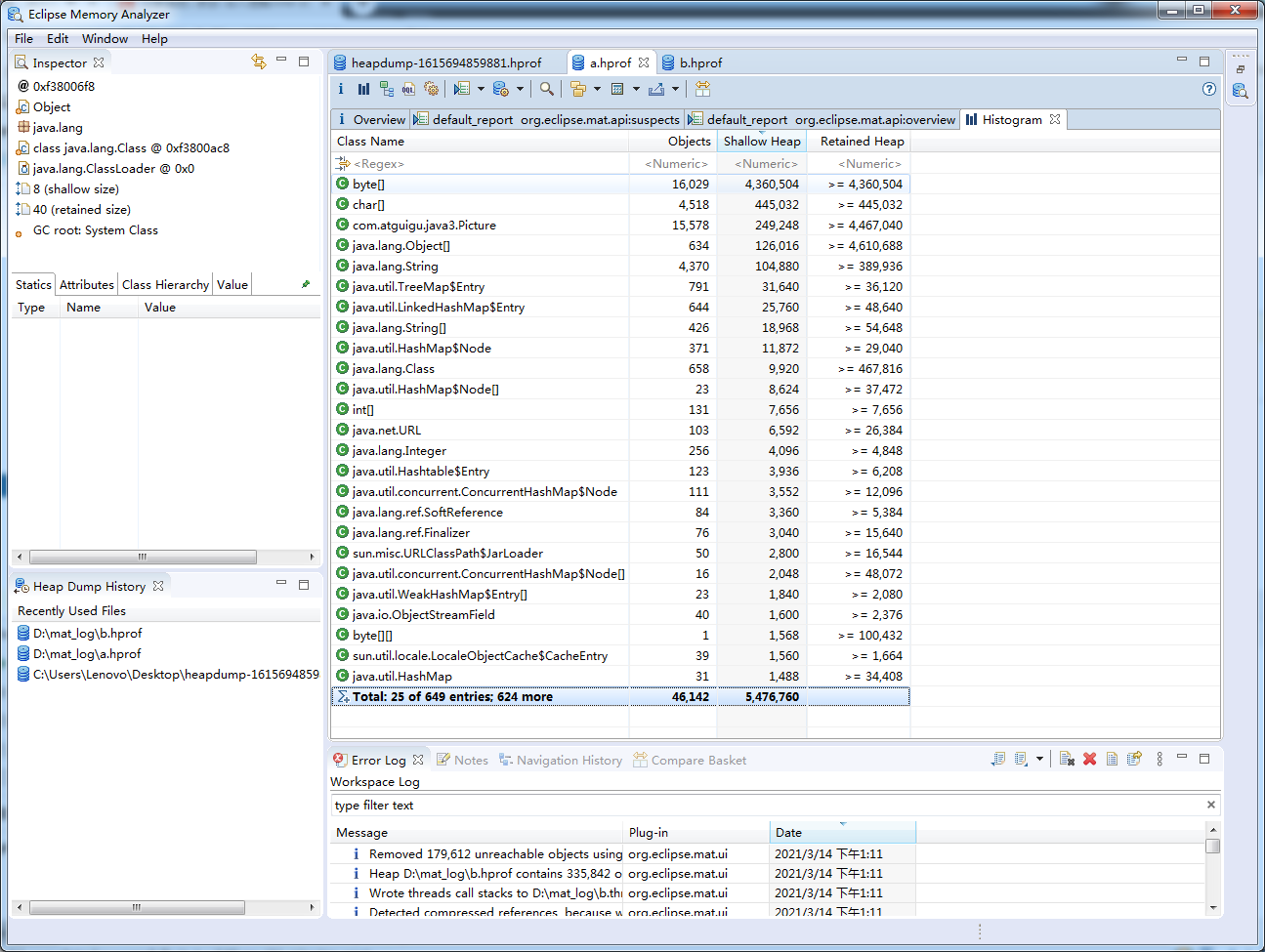
展示了各个类的实例数目以及这些实例的Shallow heap或者Retained heap的总和
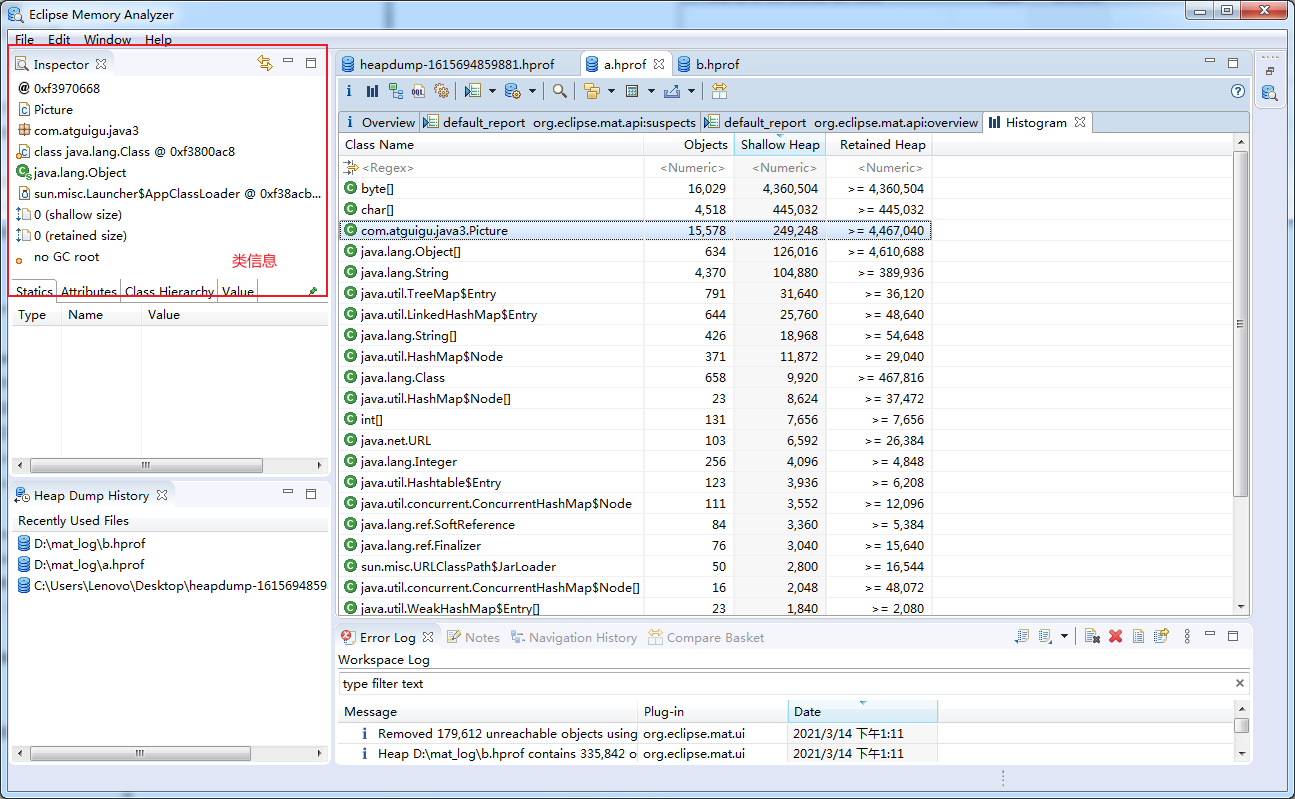
在左边可以看到某一个类的信息
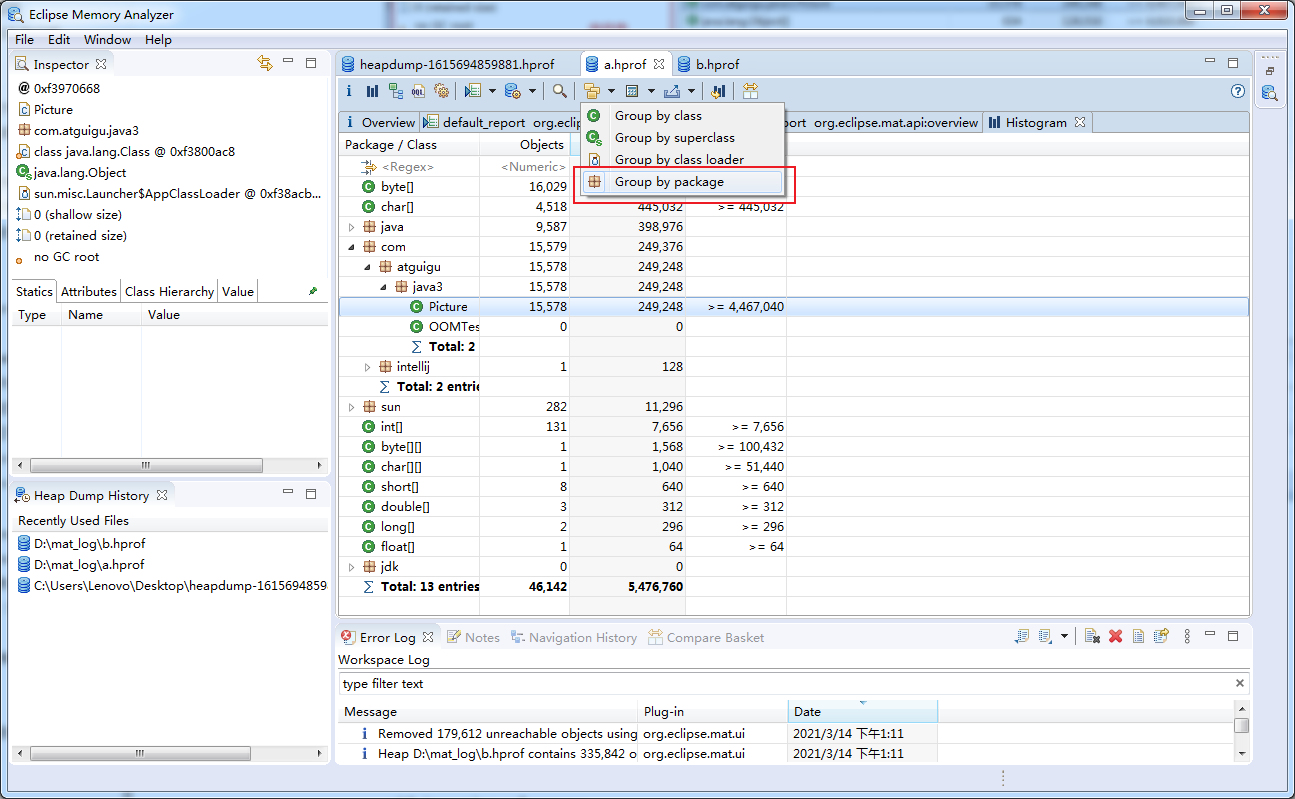
可以根据包名group by
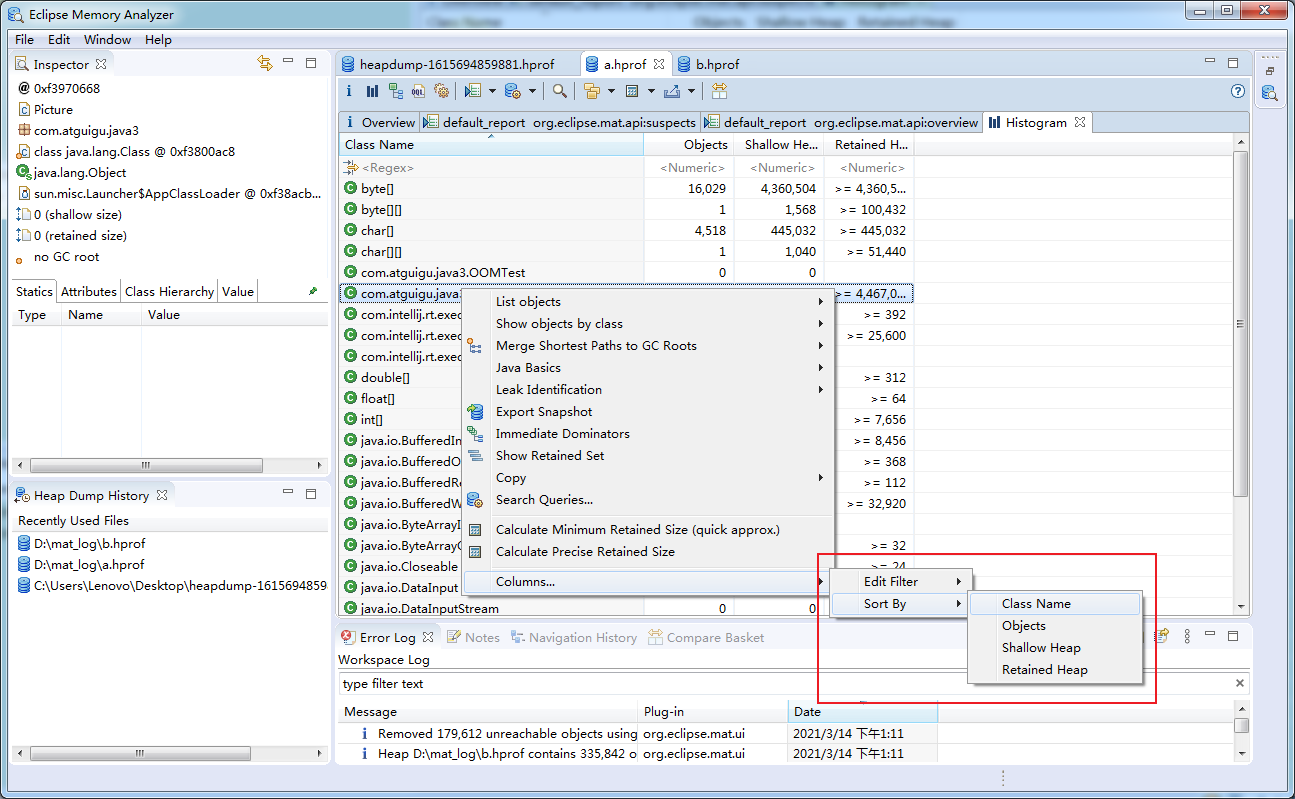
可以排序
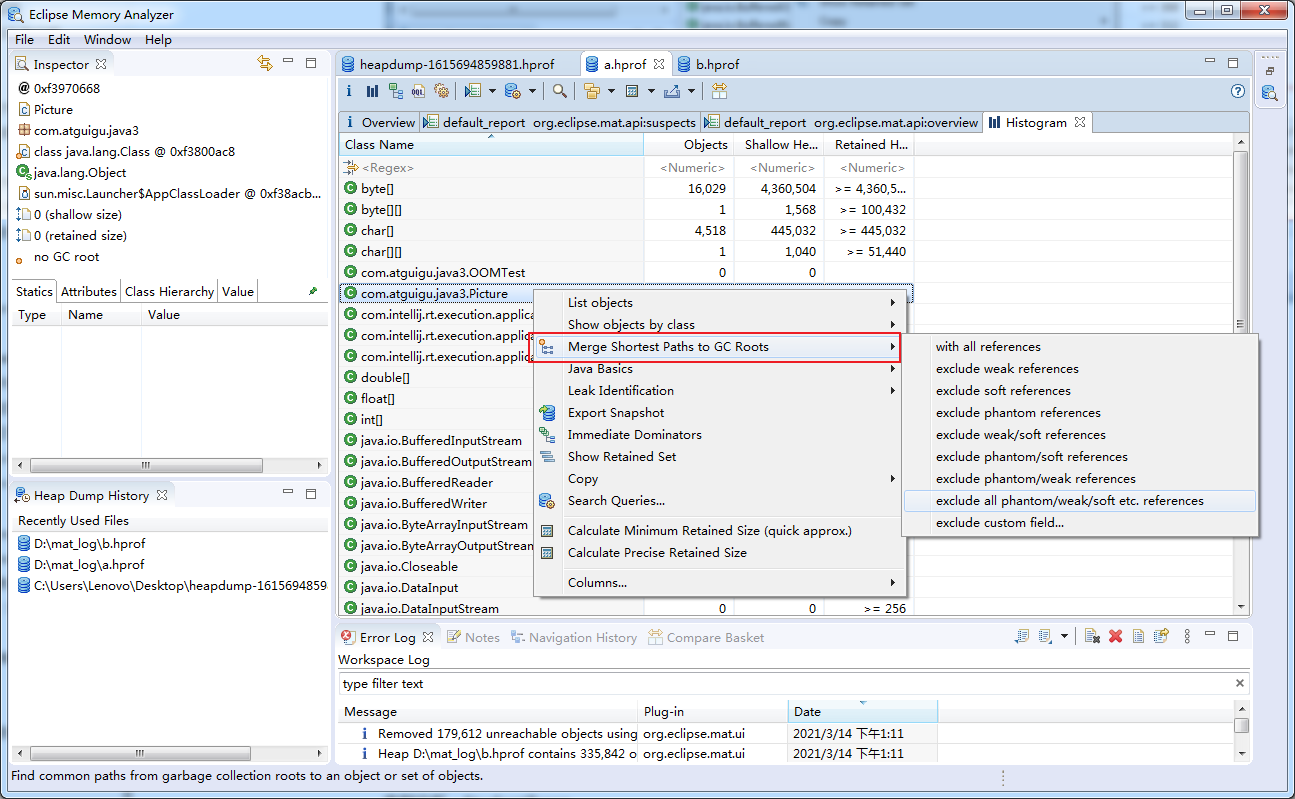
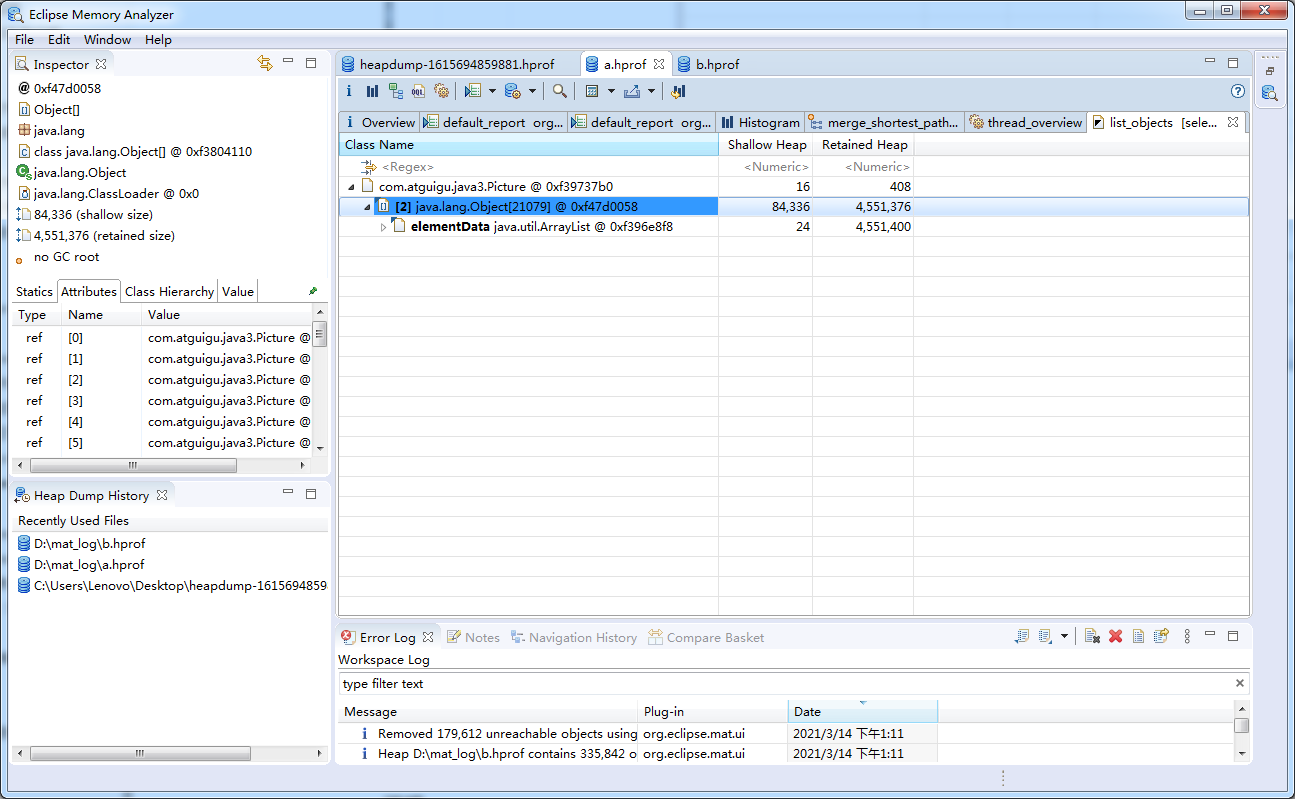
查看引用,可以看到被一个ArrayList引用
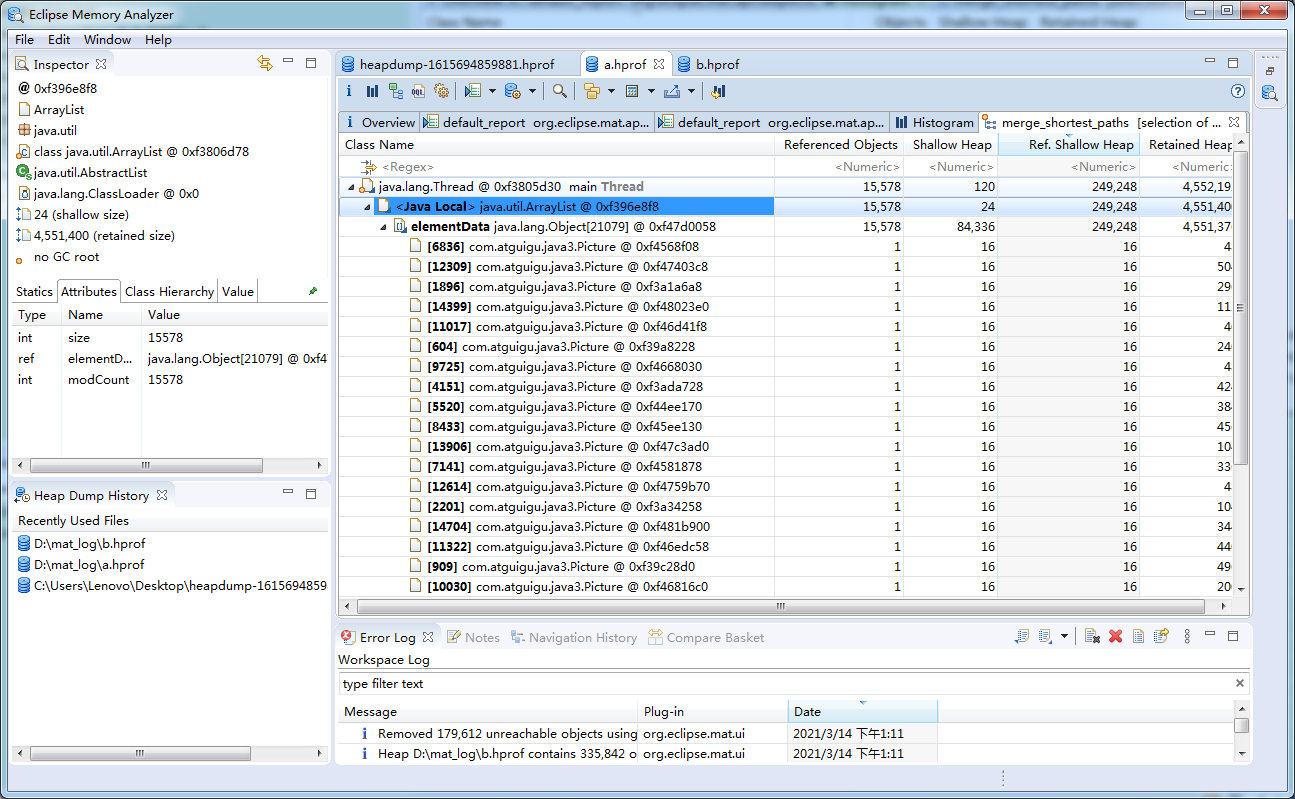
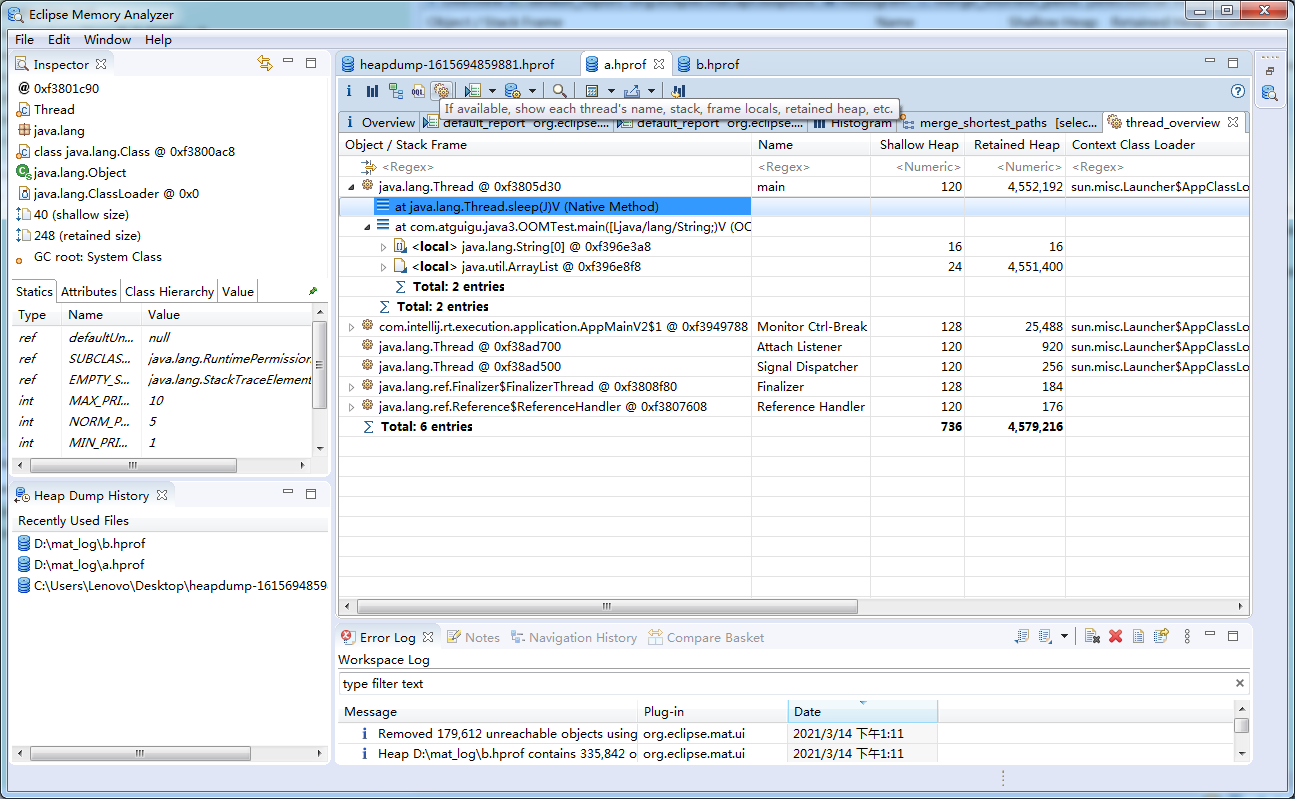
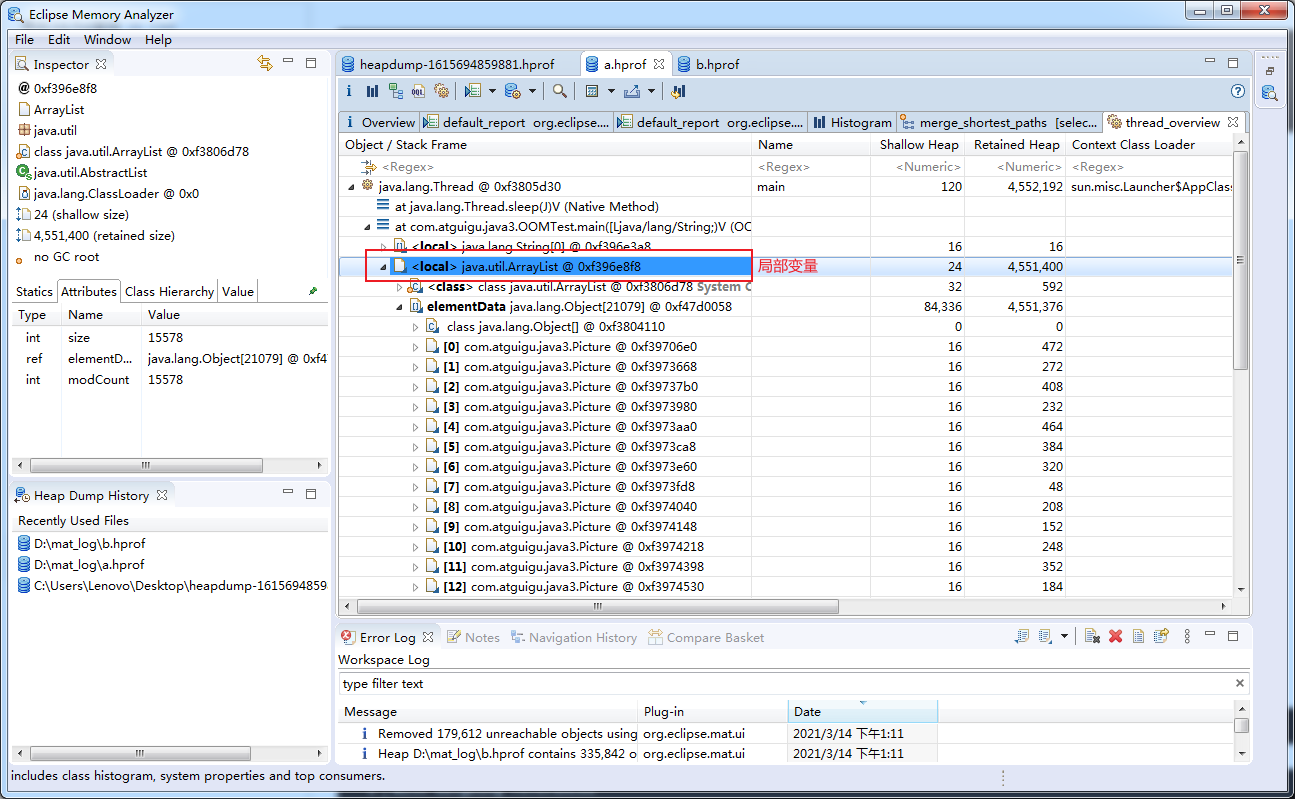
该局部变量引用了谁
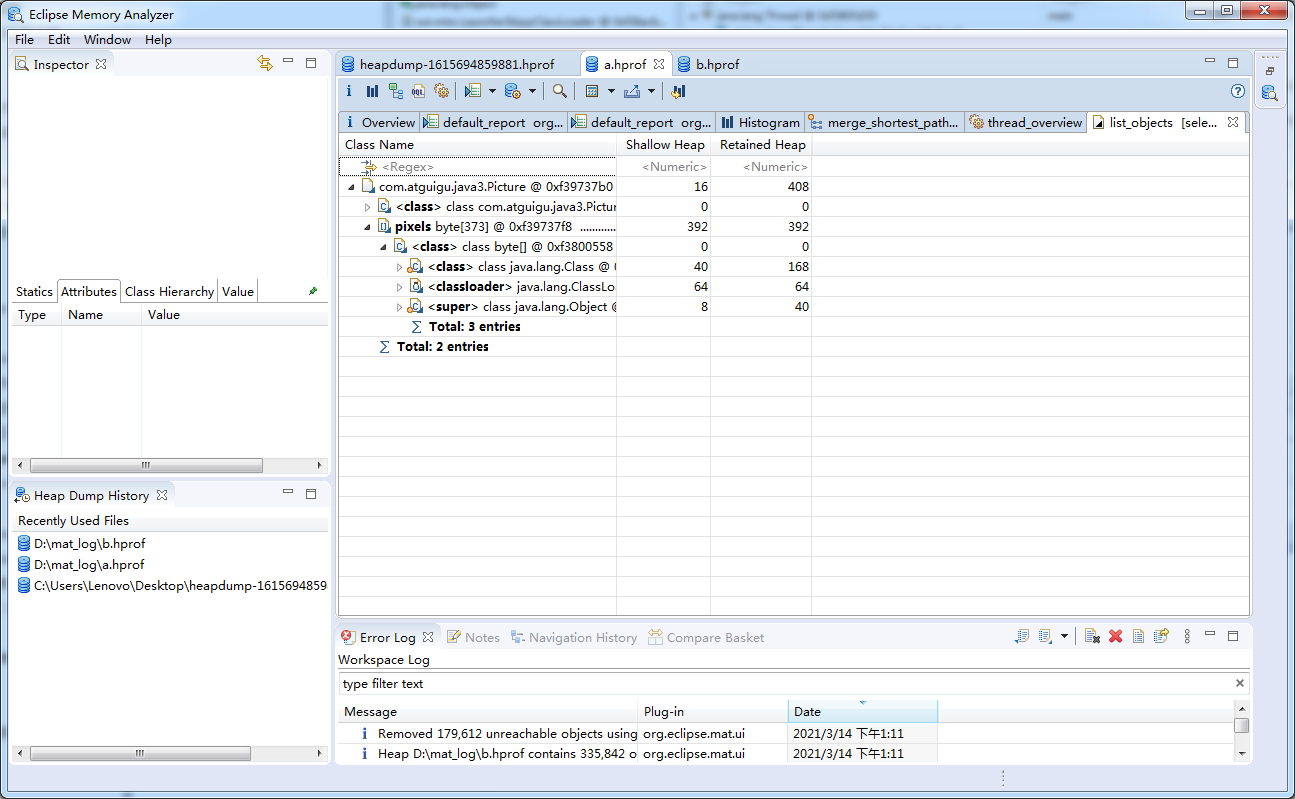
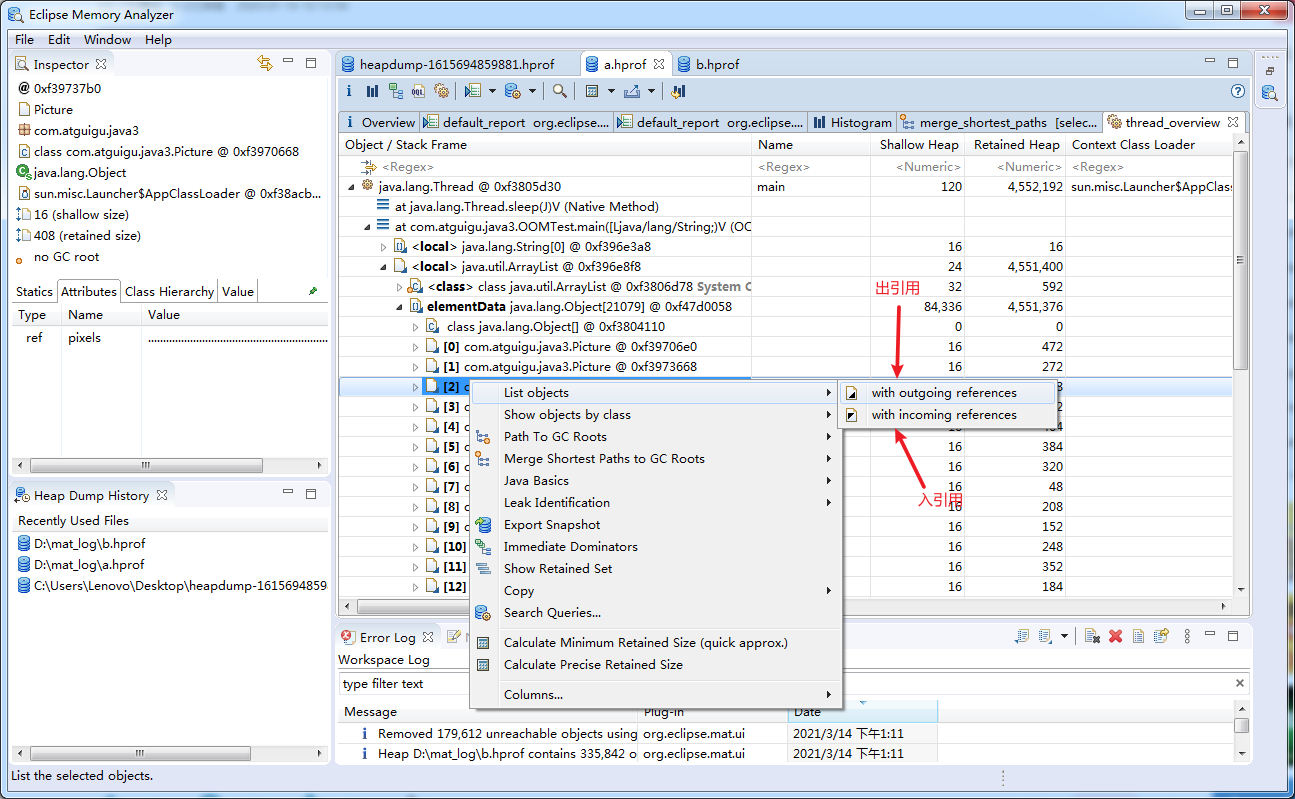
谁引用了我
浅堆(Shallow Heap)是指一个对象所消耗的内存。在32位系统中,一个对象引用会占据4个字节,一个int类型会占据4个字节,long型变量会占据8个字节,每个对象头需要占用8个字节。根据堆快照格式不同,对象的大小可能会同8字节进行对齐。
以String为例:2个int值共占8字节,对象引用占用4字节,对象头8字节,合计20字节,向8字节对齐,故占24字节。(jdk7中)

这24字节为String对象的浅堆大小。它与String的value实际取值无关,无论字符串长度如何,浅堆大小始终是24字节。
对象A的保留集指当对象A被垃圾回收后,可以被释放的所有的对象集合(包括对象A本身),即对象A的保留集可以被认为是只能通过对象A被直接或间接访问到的所有对象的集合。通俗地说,就是指仅被对象A所持有的对象的集合。
深堆是指对象的保留集中所有的对象的浅堆大小之和。
注意:浅堆指对象本身占用的内存,不包括其内部引用对象的大小。一个对象的深堆指只能通过该对象访问到的(直接或间接)所有对象的浅堆之和,即对象被回收后,可以释放的真实空间。
当前深堆大小 = 当前对象的浅堆大小 + 对象中所包含对象的深堆大小
另外一个常用的概念是对象的实际大小。这里,对象的实际大小定义为一个对象所能触及的所有对象的浅堆大小之和,也就是通常意义上我们说的对象大小。与深堆相比,似乎这个在日常开发中更为直观和被人接受,但实际上,这个概念和垃圾回收无关。
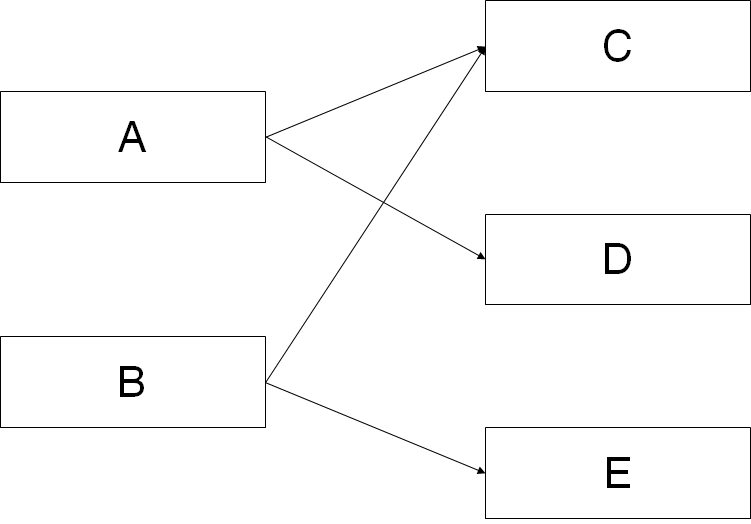
下图显示了一个简单的对象引用关系图,对象A引用了C和D,对象B引用了C和E。那么对象A的浅堆大小只是A本身,不含C和D,而A的实际大小为A、C、D三者之和。而A的深堆大小为A与D之和,由于对象C还可以通过对象B访问到,因此不在对象A的深堆范围内。
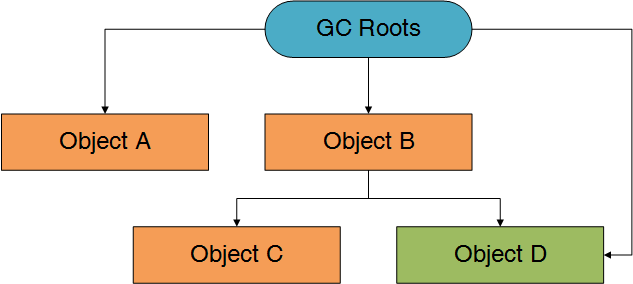
上图中,GC Roots直接引用了A和B两个对象
A对象的Retained Size=A对象的Shallow Size
B对象的Retained Size=B对象的Shallow Size + C对象的Shallow Size
这里不包括D对象,因为D对象被GC Roots直接引用。
如果GC Roots不引用D对象呢?
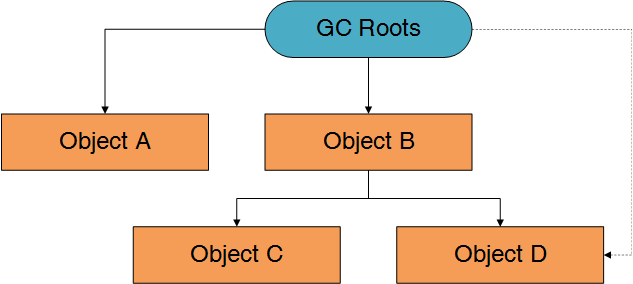
B对象的Retained Size=B对象的Shallow Size + C对象的Shallow Size + D对象的Shallow Size
package com.atguigu.java3;
import java.util.ArrayList;
import java.util.List;
/**
* 有一个学生浏览网页的记录程序,它将记录 每个学生访问过的网站地址
* 它由三个部分组成:Student、WebPage和StudentTrace三个类
* <p>
* -XX:+HeapDumpBeforeFullGC -XX:HeapDumpPath=d:\mat_log\student.hprof
*/
public class StudentTrace {
static List<WebPage> webpages = new ArrayList<>();
public static void createWebPages() {
for (int i = 0; i < 100; i++) {
WebPage wp = new WebPage();
wp.setUrl("http://www." + i + ".com");
wp.setContent(Integer.toString(i));
webpages.add(wp);
}
}
public static void main(String[] args) {
createWebPages();
Student st3 = new Student(3, "Tom");
Student st5 = new Student(5, "Jerry");
Student st7 = new Student(7, "Lily");
for (int i = 0; i < webpages.size(); i++) {
if (i % st3.getId() == 0)
st3.visit(webpages.get(i));
if (i % st5.getId() == 0)
st5.visit(webpages.get(i));
if (i % st7.getId() == 0)
st7.visit(webpages.get(i));
}
webpages.clear();
System.gc();
}
}
class Student {
private int id;
private String name;
private List<WebPage> history = new ArrayList<>();
public Student() {
}
public Student(int id, String name) {
super();
this.id = id;
this.name = name;
}
public Student(int id, String name, List<WebPage> history) {
this.id = id;
this.name = name;
this.history = history;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public List<WebPage> getHistory() {
return history;
}
public void setHistory(List<WebPage> history) {
this.history = history;
}
public void visit(WebPage wp) {
if (wp != null) {
history.add(wp);
}
}
@Override
public String toString() {
return "Student{" +
"id=" + id +
", name=‘" + name + ‘\‘‘ +
", history=" + history +
‘}‘;
}
}
class WebPage {
private String url;
private String content;
public WebPage() {
}
public WebPage(String url, String content) {
this.url = url;
this.content = content;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
@Override
public String toString() {
return "WebPage{" +
"url=‘" + url + ‘\‘‘ +
", content=‘" + content + ‘\‘‘ +
‘}‘;
}
}
浅堆都是24(id—4,name—4,引用—4,对象头8)
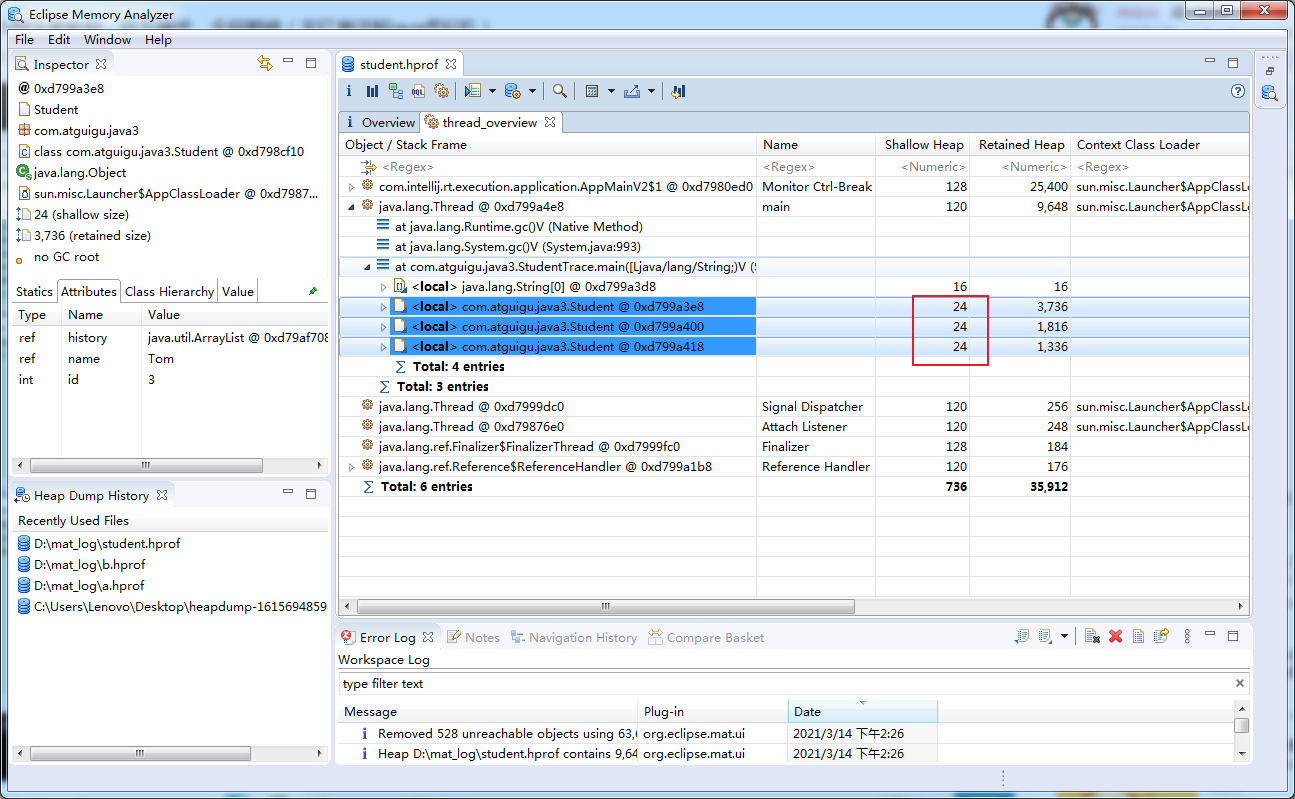
对Lily分析
考虑Lily同学:
15个webpage
每个对应152个字节15*152=2280字节→即为elementData的实际大小
关心的是elementData的深堆1288是如何计算出来的?
能被7整除,且能被3整除,以及能被7整除,且能被5整除的数值有:0, 21, 42, 63, 84, 35, 70 共7个数。
7 * 152 = 1064字节
2280 - 1064 + 72 = 1288字节!
这72个字节是什么?
15个elementData的元素 * 4字节 = 60字节
60 + 8个对象头的字节数 + 4字节 = 72字节
支配树的概念源自图论。
MAT提供了一个称为支配树(Dominator Tree)的对象图。支配树体现了对象实例间的支配关系。在对象引用图中,所有指向对象B的路径都经过对象A,则认为对象A支配对象B。如果对象A是离对象B最近的一个支配对象,则认为对象A为对象B的直接支配者。支配树是基于对象间的引用图所建立的,它有以下基本性质:
如下图所示:左图表示对象引用图,右图表示左图所对应的支配树。对象A和B由根对象直接支配,由于在到对象C的路径中,可以经过A,也可以经过B,因此对象C的直接支配者也是根对象。对象F与对象D相互引用,因为到对象F的所有路径必然经过对象D。因此,对象D是对象F的直接支配者。而到对象D的所有路径中,必然经过对象C,即使是从对象F到对象D的引用,从根节点出发,也是经过对象C的,所以,对象D的直接支配者为对象C。
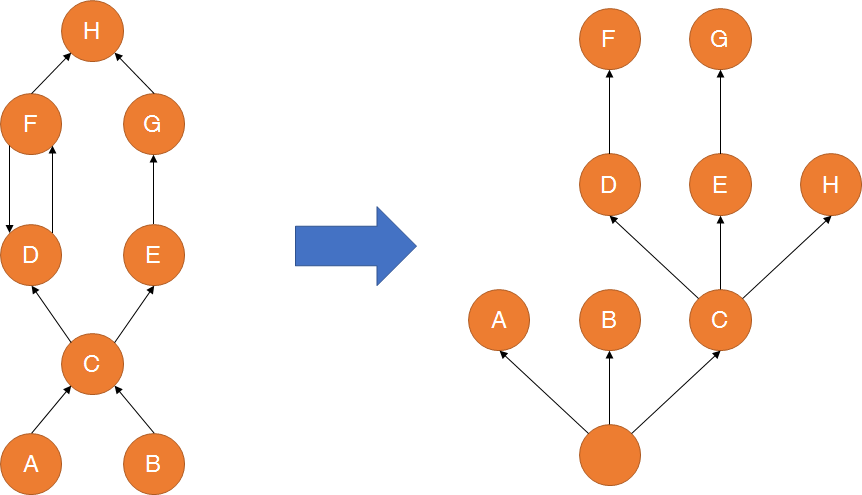
同理,对象E支配对象G。到达对象H的可以通过对象D,也可以通过对象E,因此对象D和E都不能支配对象H,而经过对象C既可以到达D也可以到达E,因此对象C为对象H的直接支配者。
在MAT中,单击工具栏上的对象支配树按钮,可以打开对象支配树视图。
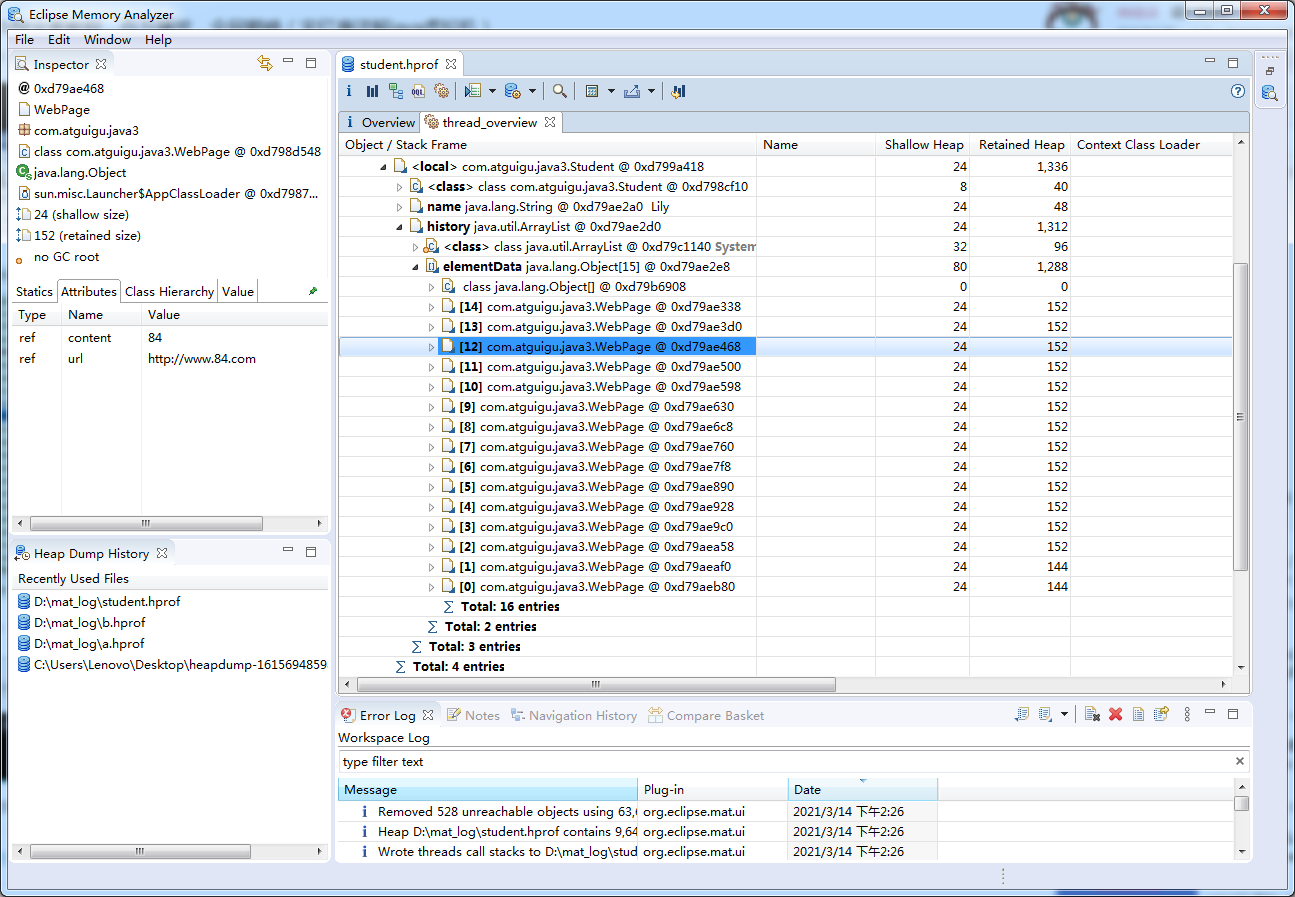
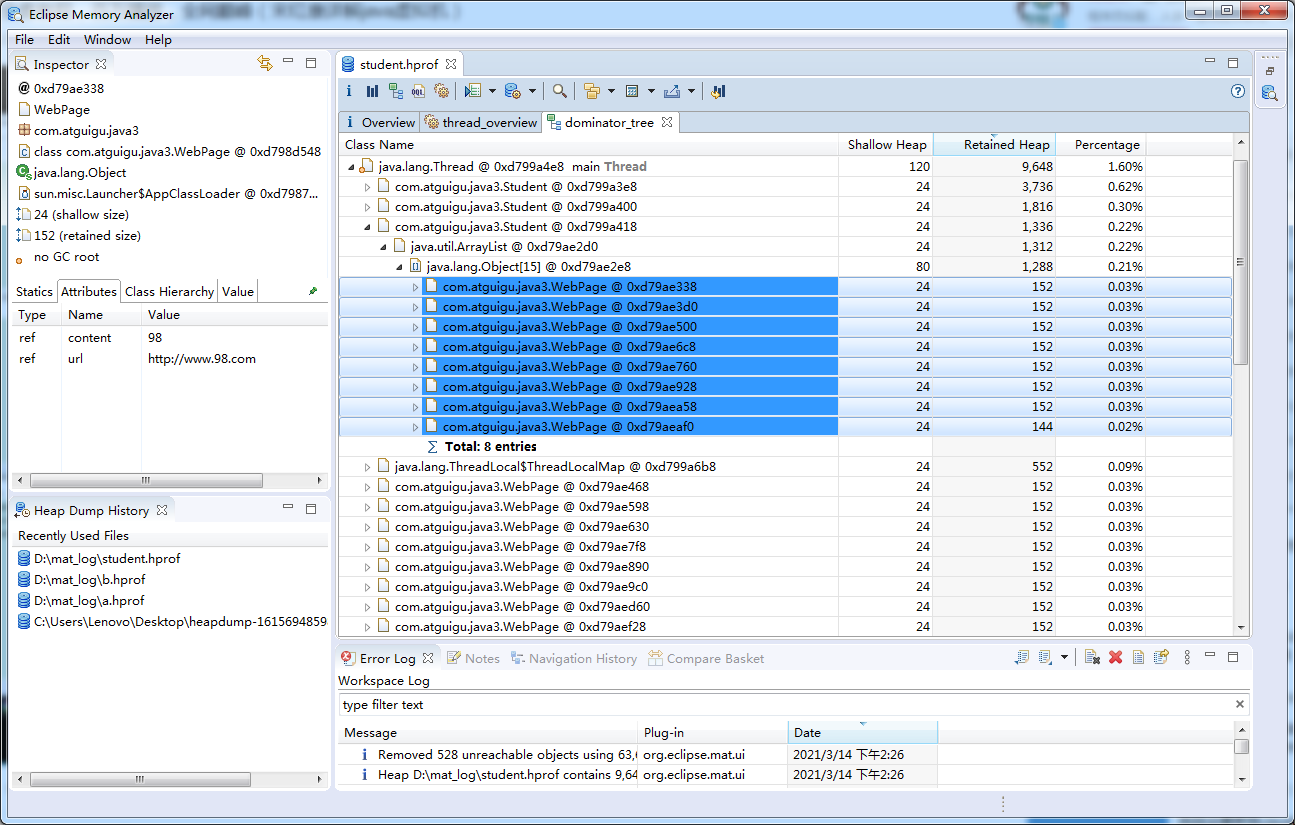
下图显示了对象支配树视图的一部分。该截图显示部分Lily学生的history队列的直接支配对象。即当Lily对象被回收,也会一并回收的所有对象。显然能被3或者5整除的网页不会出现在该列表中,因为们同时被另外两名学生对象引用。
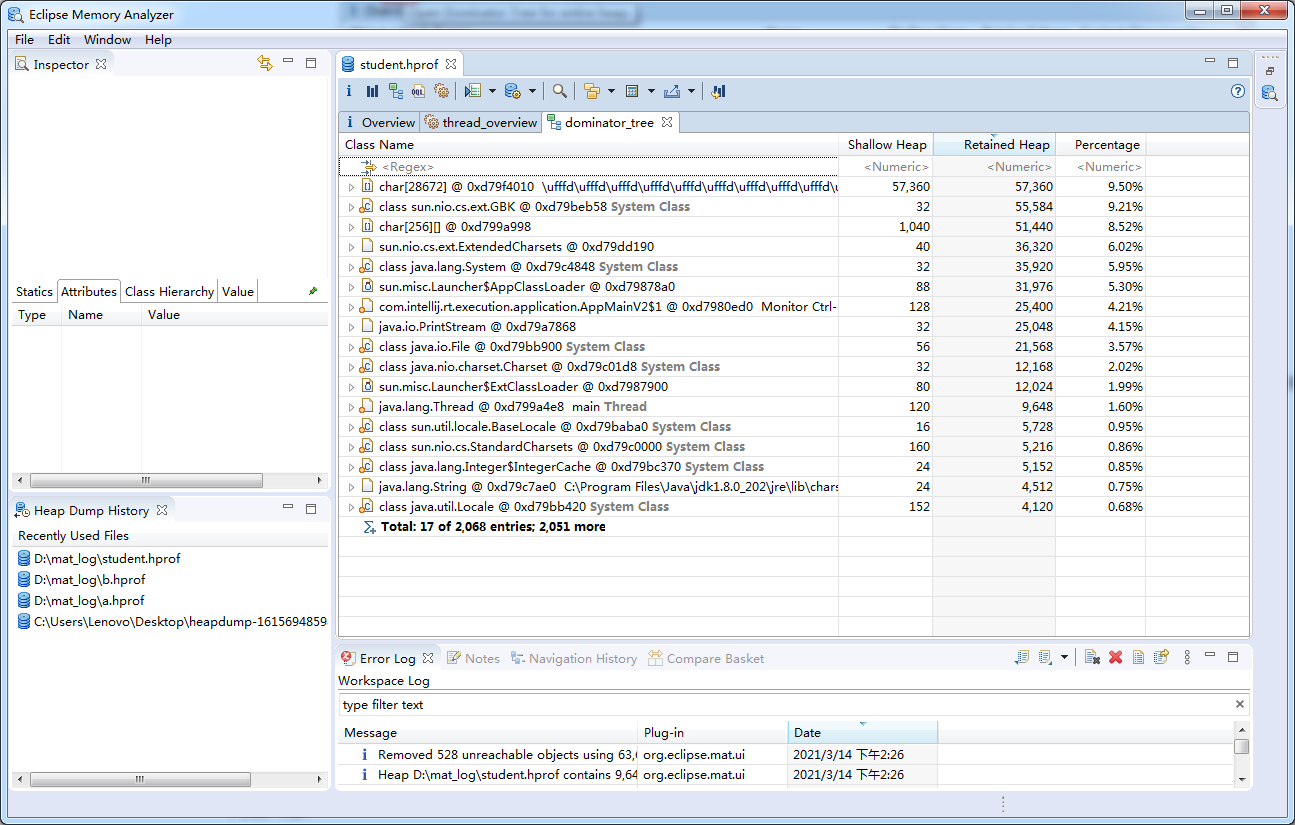
以Lily为例,只有8个,剩下其他其他两个学生也能访问到:
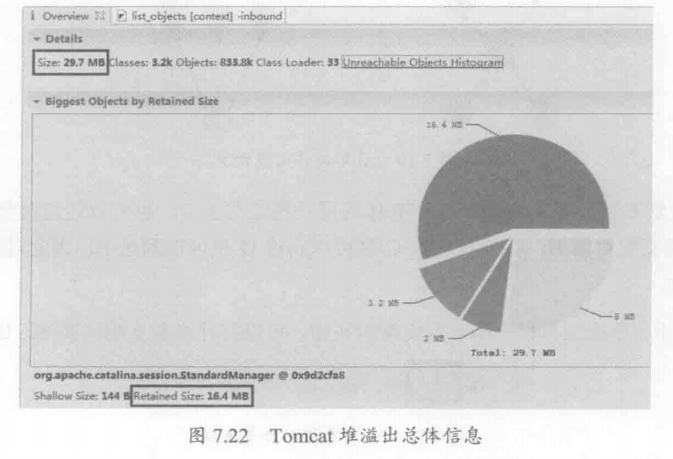
Tomcat是最常用的Java Servlet容器之一,同时也可以当做单独的Web服务器使用。Tomcat本身使用Java实现,并运行于Java虚拟机之上。在大规模请求时,Tomcat有可能会因为无法承受压力而发生内存溢出错误。这里根据一个被压垮的Tomcat的堆快照文件,来分析Tomcat在崩溃时的内部情况。
图7.22显示了Tomcat溢出时的总体信息,可以看到堆的大小为29.7MB。从统计饼图中得知,当前深堆最大的对象为StandardManager,它持有大约16.4MB的对象。
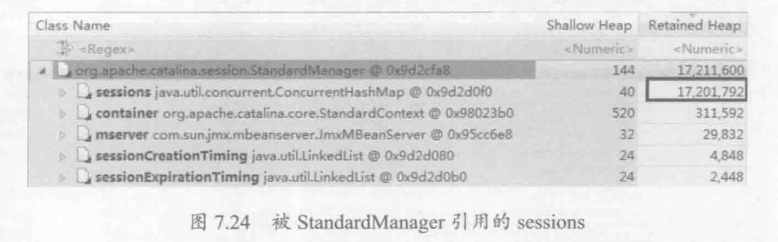
一般来说,我们总是会对占用空间最大的对象特别感兴趣,如果可以查看StandardManager内部究竟引用了哪些对象,对于分析问题可能会起到很大的帮助。因此,在饼图中单击StandardManager所在区域,在弹出菜单中选择“with outgoing references”命令,如图7.23所示。这样将会列出被StandardManager引用的所有对象。

图7.24显示了被StandardManager引用的对象,其中特别显眼的就是sessions对象,它占用了约17MB空间。
继续查找,打开sessions对象,查看被它引用的对象,如图7.25所示。可以看到sessions对象为ConcurrentHashMap,其内部分为16个Segment。从深堆大小看,每个Segment都比较平均,大约为1MB,合计17MB。继续打开Segment,查看存储在sessions中的真实对象。如图7.26所示,可以找到内部存放的为StandardSession对象。


通过OQL命令,查找所有的StardardSession,如图7.27所示。可以看到当前堆中含有9941个session,并且每一个session的深堆为1592字节,合计约15MB,达到当前堆大小的50%。由此,可以知道,当前Tomcat发生内存溢出的原因,极可能是由于在短期内接收大量不同客户端的请求,从而创建大量session导致。
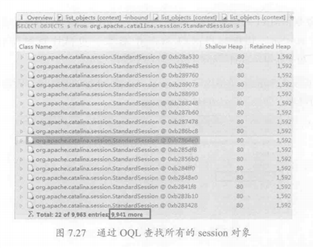
为了获得更为精确的信息,可以查看每一个session的内部数据,如图7.28所示,在左侧的对象属性表中,可以看到所选中的session的最后访问时间和创建时间。
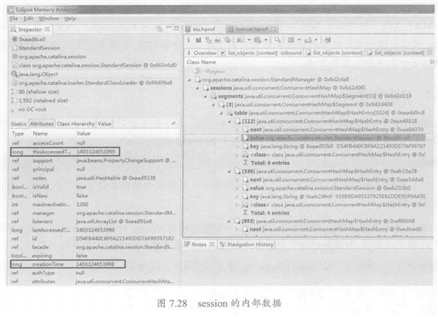
通过OQL命令和MAT的排序功能,如图7.29所示,可以找到当前系统中最早创建的session和最后创建的session。再根据当前的session总数,可以计算每秒的平均压力为:9941/(1403324677648-1403324645728)*1000=311次/秒。
由此推断,在发生Tomcat堆溢出时,Tomcat在连续30秒的时间内,平均每秒接收了约311次不同客户端的请求,创建了合计9941个session。
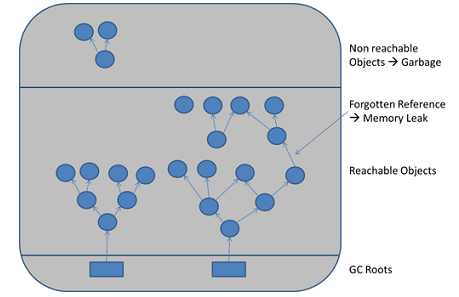
可达性分析算法来判断对象是否是不再使用的对象,本质都是判断一个对象是否还被引用。那么对于
这种情况下,由于代码的实现不同就会出现很多种内存泄漏问题(让JVM误以为此对象还在引用中,;
法回收,造成内存泄漏)。
严格来说,只有对象不会再被程序用到了,但是GC又不能回收他们的情况,才叫内存泄漏。
但实际情况很多时候一些不太好的实践(或疏忽)会导致对象的生命周期变得很长甚至导致OOM,也
以叫做宽泛意义上的“内存泄漏”。
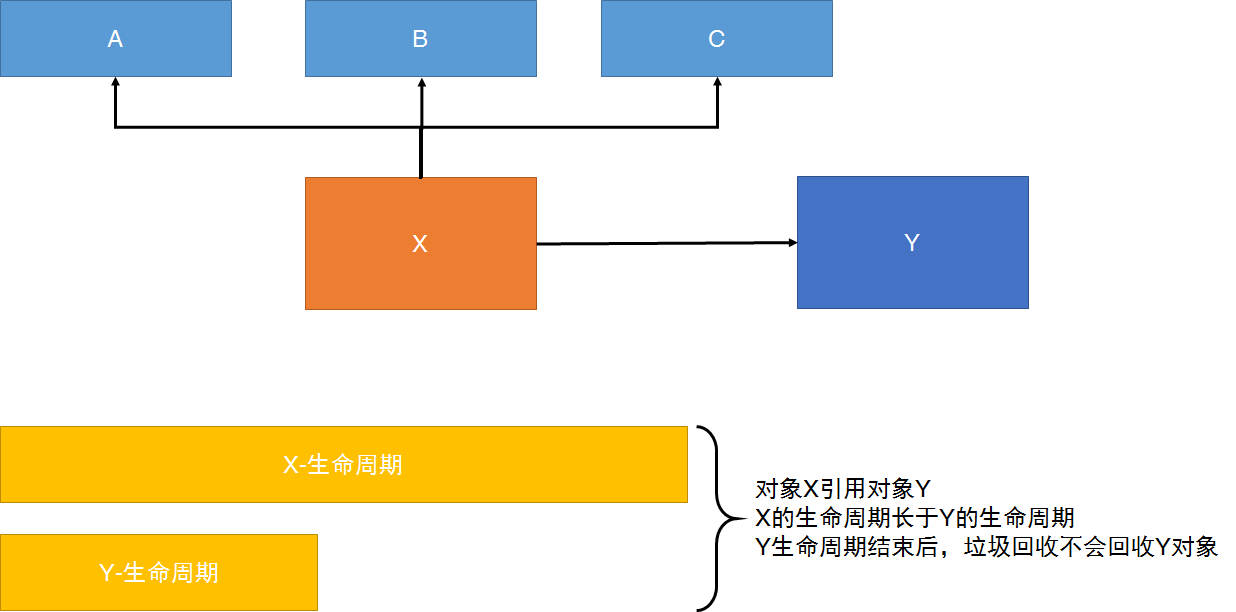
对象X引用对象Y,的生命周期比Y的生命周期长;
那么当Y生命周期结束的时候,X依然引用着Y,这时候,垃圾回收期是不会回收对象Y的;
如果对象X还引用着生命周期比较短的A、B、C,对象A又引用着对象a、b、c,这样就可能造成大量无用的对象不能被回收,进而占据了内存资源,造成内存泄漏,直到内存溢出。
申请了内存用完了不释放,比如一共有1024M的内存,分配了512M的内存一直不回收,那么可以用的内存只有512M了,仿佛泄露掉了一部分;
通俗一点讲的话,内存泄漏就是占着茅坑不拉屎。
申请内存时,没有足够的内存可以使用;
通俗一点儿讲,一个厕所就三个坑,有两个站着茅坑不走的(内存泄漏),剩下最后一个坑,厕所表示接待压力很大,这时候一下子来了两个人,坑位(内存)就不够了,内存泄漏变成内存溢出了。
可见,内存泄漏和内存溢出的关系:内存泄漏的增多,最终会导致内存溢出。
经常发生:发生内存泄露的代码会被多次执行,每次执行,泄露一块内存;
偶然发生:在某些特定情况下才会发生
一次性:发生内存泄露的方法只会执行一次;
隐式泄漏:一直占着内存不释放,直到执行结束;严格的说这个不算内存泄漏,因为最终释放掉了,但是如果执行时间特别长,也可能会导致内存耗尽。
静态集合类,如HashMap、LinkedList等等。如果这些容器为静态的,那么它们的生命周期与JVM程序一致,则容器中的对象在程序结束之前将不能被释放,从而造成内存泄漏。简单而言,长生命周期的对象持有短生命周期对象的引用,尽管短生命周期的对象不再使用,但是因为长生命周期对象持有它的引用而导致不能被回收。
package com.atguigu.java4;
import java.util.ArrayList;
import java.util.List;
public class MemoryLeak {
static List<Object> list = new ArrayList<>();
public void oomTest() {
// 局部变量
Object obj = new Object();
list.add(obj);
}
}
单例模式,和静态集合导致内存泄露的原因类似,因为单例的静态特性,它的生命周期和JVM的生命周期一样长,所以如果单例对象如果持有外部对象的引用,那么这个外部对象也不会被回收,那么就会造成内存泄漏。
内部类持有外部类,如果一个外部类的实例对象的方法返回了一个内部类的实例对象。
这个内部类对象被长期引用了,即使那个外部类实例对象不再被使用,但由于内部类持有外部类的实例对象,这个外部类对象将不会被垃圾回收,这也会造成内存泄漏。
各种连接,如数据库连接、网络连接和I0连接等。
在对数据库进行操作的过程中,首先需要建立与数据库的连接,当不再使用时,需要调用close方法来释放与数据库的连接。只有连接被关闭后,垃圾回收器才会回收对应的对象。
否则,如果在访问数据库的过程中,对Connection、Statement或ResultSet不显性地关闭,将会造成大量的对象无法被回收,从而引起内存泄漏。
package com.atguigu.java4;
import java.sql.*;
public class MemoryLeak {
public static void main(String[] args) {
Connection conn = null;
try {
Class.forName("com.mysql.jdbc.Driver");
conn = DriverManager.getConnection("url", "", "");
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("......");
} catch (ClassNotFoundException | SQLException e) {
e.printStackTrace();
} finally {
// 1. 关闭结果集Statement
// 2. 关闭声明的对象ResultSet
// 3. 关闭连接Connection
}
}
}
变量不合理的作用域。一般而言,一个变量的定义的作用范围大于其使用范围,很有可能会造成内存泄
另一方面,如果没有及时地把对象设置为null,很有可能导致内存泄漏的发生。
package com.atguigu.java4;
public class UsingRandom {
private String msg;
public void receiveMsg() {
// 从网络中接受数据保存到msg中
readFromNet();
// 将msg保存到数据库中
saveDB();
}
}
如上面这个伪代码,通过readFromNet方法把接受的消息保存在变量msg中,然后调用saveDB方法把msg的内容保存到数据库中,此时msg已经就没用了,由于msg的生命周期与对象的生命周期相同,此时msg还不能回收,因此造成了内存泄漏。
实际上这个msg变量可以放在receiveMsg方法内部,当方法使用完,那么msg的生命周期也就结束,此时就可以回收了。还有一种方法,在使用完msg后,把msg设置为null,这样垃圾回收器也会回收msg的内存空间。
改变哈希值,当一个对象被存储进HashSet集合中以后,就不能修改这个对象中的那些参与计算哈希值的字段了。
否则,对象修改后的哈希值与最初存储进HashSet集合中时的哈希值就不同了,在这种情况下,即使在contains方法使用该对象的当前引用作为的参数去HashSet集合中检索对象,也将返回找不到对象的结果,这也会导致无法从HashSet集合中单独删除当前对象,造成内存泄漏。这也是 String 为什么被设置成了不可变类型,我们可以放心地把 String 存入 HashSet,或者把String当做HashMap的key值;
当我们想把自己定义的类保存到散列表的时候,需要保证对象的hashCode不可变。
举例1:
package com.atguigu.java4;
import java.util.HashSet;
/**
* 演示内存泄漏
*/
public class ChangeHashCode {
public static void main(String[] args) {
HashSet<Person> set = new HashSet<>();
Person p1 = new Person(1001, "AA");
Person p2 = new Person(1002, "BB");
set.add(p1);
set.add(p2);
// 导致了内存的泄漏
p1.name = "CC";
// 删除失败
set.remove(p1);
// [Person{id=1002, name=‘BB‘}, Person{id=1001, name=‘CC‘}]
System.out.println(set);
set.add(new Person(1001, "CC"));
// [Person{id=1002, name=‘BB‘}, Person{id=1001, name=‘CC‘}, Person{id=1001, name=‘CC‘}]
System.out.println(set);
set.add(new Person(1001, "AA"));
// [Person{id=1002, name=‘BB‘}, Person{id=1001, name=‘CC‘}, Person{id=1001, name=‘CC‘}, Person{id=1001, name=‘AA‘}]
System.out.println(set);
}
}
class Person {
int id;
String name;
public Person() {
}
public Person(int id, String name) {
this.id = id;
this.name = name;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Person)) return false;
Person person = (Person) o;
if (id != person.id) return false;
return name != null ? name.equals(person.name) : person.name == null;
}
@Override
public int hashCode() {
int result = id;
result = 31 * result + (name != null ? name.hashCode() : 0);
return result;
}
@Override
public String toString() {
return "Person{" +
"id=" + id +
", name=‘" + name + ‘\‘‘ +
‘}‘;
}
}
举例2:
package com.atguigu.java4;
import java.util.HashSet;
/**
* 演示内存泄漏
*/
public class ChangeHashCode1 {
public static void main(String[] args) {
HashSet<Point> hs = new HashSet<>();
Point cc = new Point();
// hashCode = 41
cc.setX(10);
hs.add(cc);
// hashCode = 51 此行为导致了内存的泄漏
cc.setX(20);
// hs.remove = false
System.out.println("hs.remove = " + hs.remove(cc));
hs.add(cc);
// hs.size = 2
System.out.println("hs.size = " + hs.size());
// [Point{x=20}, Point{x=20}]
System.out.println(hs);
}
}
class Point {
int x;
public Point() {
}
public Point(int x) {
this.x = x;
}
public int getX() {
return x;
}
public void setX(int x) {
this.x = x;
}
@Override
public boolean equals(Object obj) {
if (this == obj) return true;
if (obj == null) return false;
if (getClass() != obj.getClass()) return false;
Point other = (Point) obj;
if (x != other.x) return false;
return true;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + x;
return result;
}
@Override
public String toString() {
return "Point{" +
"x=" + x +
‘}‘;
}
}
内存泄漏的另一个常见来源是缓存,一旦你把对象引用放入到缓存中,他就很容易遗忘。比如:之前项目在一次上线的时候,应用启动奇慢直到夯死,就是因为代码中会加载一个表中的数据到缓存(内存中,测试环境只有几百条数据,但是生产环境有几百万的数据。
对于这个问题,可以使用WeakHashMap代表缓存,此种Map的特点是,当除了自身有对key的引用外,此key没有其他引用那么此map会自动丢弃此值。
package com.atguigu.java4;
import java.util.HashMap;
import java.util.Map;
import java.util.WeakHashMap;
import java.util.concurrent.TimeUnit;
public class MapTest {
static Map<String, String> wMap = new WeakHashMap<>();
static Map<String, String> map = new HashMap<>();
public static void main(String[] args) {
init();
testWeakHashMap();
testHashMap();
}
public static void init() {
String ref1 = new String("obejct1");
String ref2 = new String("obejct2");
String ref3 = new String("obejct3");
String ref4 = new String("obejct4");
wMap.put(ref1, "cacheObject1");
wMap.put(ref2, "cacheObject2");
map.put(ref3, "cacheObject3");
map.put(ref4, "cacheObject4");
System.out.println("String引用ref1,ref2,ref3,ref4 消失");
}
public static void testWeakHashMap() {
System.out.println("WeakHashMap GC之前");
System.out.println(wMap);
try {
System.gc();
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("WeakHashMap GC之后");
System.out.println(wMap);
}
public static void testHashMap() {
System.out.println("HashMap GC之前");
System.out.println(map);
try {
System.gc();
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("HashMap GC之后");
System.out.println(map);
}
}

上面代码演示WeakHashMap如何自动释放缓存对象,当init函数执行完成后,局部变量符串引用weakd1、weakd2、d1、d2都会消失,此时只有静态map中保存中对字符串对象的引用,可以看到,调用gc之后,HashMap的没有被回收,而WeakHashMap里面的缓存被回收了。
内存泄漏另一个常见来源是监听器和其他回调,如果客户端在你实现的API中注册回调,却没有显示的取消,那么就会积聚。
需要确保回调立即被当作垃圾回收的最佳方法是只保存它的弱引用,例如将他们保存成为WeakHashMap中的键。
package com.atguigu.java4;
import java.util.Arrays;
import java.util.EmptyStackException;
public class Stack {
private Object[] elements;
private int size = 0;
private static final int DEFAULT_INITIAL_CAPACITY = 16;
public Stack() {
elements = new Object[DEFAULT_INITIAL_CAPACITY];
}
/**
* 入栈
*
* @param e
*/
public void push(Object e) {
ensureCapacity();
elements[size++] = e;
}
/**
* 出栈
*
* @return
*/
public Object pop() {
if (size == 0)
throw new EmptyStackException();
return elements[--size];
}
/**
* 扩容
*/
private void ensureCapacity() {
if (elements.length == size) {
elements = Arrays.copyOf(elements, 2 * size + 1);
}
}
}
上述程序并没有明显的错误,但是这段程序有一个内存泄漏,随着GC活动的增加,或者内存占用的不断增加,程序性能的降低就会表现出来,严重时可导致内存泄漏,但是这种失败情况相对较少。
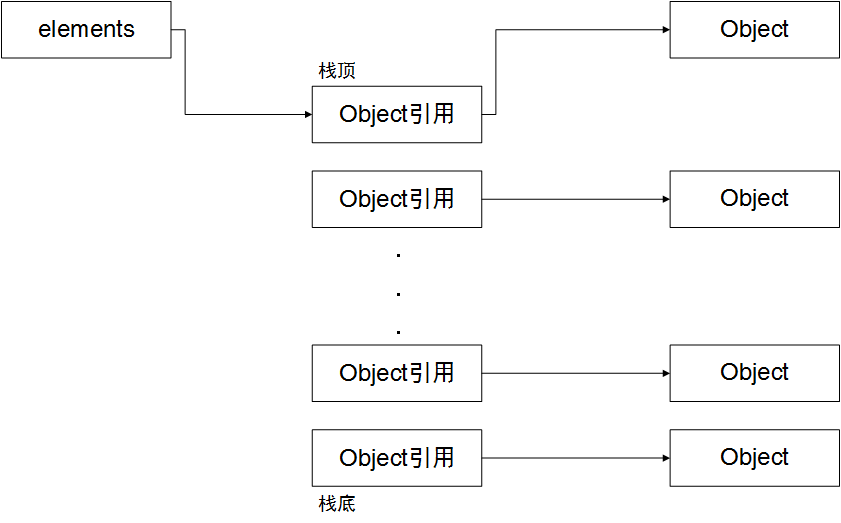
代码的主要问题在pop函数,下面通过这张图示展现
假设这个栈一直增长,增长后如下图所示
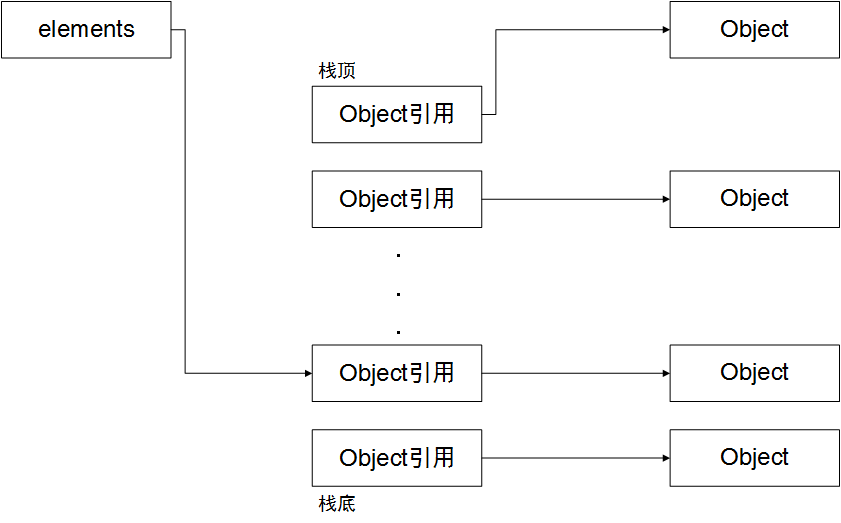
当进行大量的pop操作时,由于引用未进行置空,gc是不会释放的,如下图所示
将代码中的pop()方法变成如下方法:
public Object pop() {
if (size == 0) {
throw new EmptyStackException();
}
Object result = elements[--size];
elements[size] = null;
return result;
}
public class TestActivity extends Activity {
private static final object key = new Object();
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
// 匿名线程
new Thread() {
public void run() {
synchronized (key) {
try {
key.wait();
} catch (InterruptedException e) {
e.printstackTrace();
}
}
}
}.start();
}
}
MAT支持一种类似于SQL的查询语言OQL(Object Query Language)。OQL使用类SQL语法,可以在堆中进行对象的查找和筛选
在MAT中,Select子句的格式与SQL基本一致,用于指定要显示的列。Select子句中可以使用“*”,查看结果对象的引用实例(相当于outgoing references)。
SELECT * FROM java.util.Vector v
使用“OBJECTS”关键字,可以将返回结果集中的项以对象的形式显示。
SELECT objects v.elementData FROM java.util.Vector v
SELECT OBJECTS s.value FROM java.lang.String s
在Select子句中,使用“AS RETAINED SET”关键字可以得到所得对象的保留集。
SELECT AS RETAINED SET * FROM com.atguigu.mat.Student
“DISTINCT”关键字用于在结果集中去除重复对象。
SELECT DISTINCT OBJECTS classof(s) FROM java.lang.String s
From子句用于指定查询范围,它可以指定类名、正则表达式或者对象地址。
SELECT * FROM java.lang.String s
下例使用正则表达式,限定搜索范围,输出所有com.atguigu包下所有类的实例
SELECT * FROM "com\.atguigu\..*"
也可以直接使用类的地址进行搜索。使用类的地址的好处是可以区分被不同ClassLoader加
载的同一种类型。
SELECT * FROM 0x37a0b4d
Where子句用于指定OQL的查询条件。OQL查询将只返回满足Where子句指定条件的对象。Where子句的格式与传统SQL极为相似。
例返回长度大于10的char数组。
SELECT * FROM Ichar[] s WHERE s.@length>10
下例返回包含“java”子字符串的所有字符串,使用“LIKE”操作符,“LIKE”操作符的操作参数为正则表达式。
SELECT * FROM java.lang.String s WHERE toString(s) LIKE " .*java.*"
下例返回所有value域不为null的字符串,使用“=”操作符。
SELECT * FROM java.lang.String s WHERE s.value != null
Where子句支持多个条件的AND、OR运算。下例返回数组长度大于15,并且深堆大于1000字节的所有Vector对象。
SELECT * FROM java.util.Vector v WHERE v.elementData.@length > 15 AND v.@retainedHeapSize > 1000
OQL中可以访问堆内对象的属性,也可以访问堆内代理对象的属性。访问堆内对象的属性时,
格式如下:
[<alias>.]<field>.<field>.<field>
其中alias为对象名称。
访问java.io.File对象的path属性,并进一步访问path的value属性:
SELECT toString(f.path.value) FROM java.io.File f
下例显示了String对象的内容、objectid和objectAddress。
SELECT s.toString(), s.@objectId, s.@objectAddress FROM java.lang.String s
下例显示java.util.Vector内部数组的长度。
SELECT v.elementData.@length FROM java.util.Vector v
下例显示了所有的java.util.Vector对象及其子类型
SELECT * FROM INSTANCEOF java.util.Vector
原文:https://www.cnblogs.com/iamfatotaku/p/14533130.html