Kafka的官方文档:http://kafka.apache.org/documentation/#quickstart
Kafka的核心论文:https://www.kancloud.cn/kancloud/log-real-time-datas-unifying/58708
Kafka原理介绍文档:https://cwiki.apache.org/confluence/display/KAFKA/Kafka+Improvement+Proposals、http://kafka.apache.org/documentation/#design、http://kafka.apache.org/documentation/#implementation
--代码的异步化处理
CompletableFuture简单介绍:
whenComplete和exceptionally
whenCompleteAsync把这个任务提交给线程池执行exceptionally 就是执行失败了handle 是任务执行完成对结果的处理,同thenApply不同的是,handle是在线程执行完之后再执行,如果异常也会执行,但是thenApply只会执行成功的
thenAccept 根据返回结果执行后续步骤
--异步收发网络数据
Netty:

NIO:

关于JAVA的网络,之前有个比喻形式的总结,分享给大家:
例子:有一个养鸡的农场,里面养着来自各个农户(Thread)的鸡(Socket),每家农户都在农场中建立了自己的鸡舍(SocketChannel)
1、BIO:Block IO,每个农户盯着自己的鸡舍,一旦有鸡下蛋,就去做捡蛋处理;
2、NIO:No-Block IO-单Selector,农户们花钱请了一个饲养员(Selector),并告诉饲养员(register)如果哪家的鸡有任何情况(下蛋)均要向这家农户报告(select keys);
3、NIO:No-Block IO-多Selector,当农场中的鸡舍逐渐增多时,一个饲养员巡视(轮询)一次所需时间就会不断地加长,这样农户知道自己家的鸡有下蛋的情况就会发生较大的延迟。怎么解决呢?没错,多请几个饲养员(多Selector),每个饲养员分配管理鸡舍,这样就可以减轻一个饲养员的工作量,同时农户们可以更快的知晓自己家的鸡是否下蛋了;
4、Epoll模式:如果采用Epoll方式,农场问题应该如何改进呢?其实就是饲养员不需要再巡视鸡舍,而是听到哪间鸡舍的鸡打鸣了(活跃连接),就知道哪家农户的鸡下蛋了;
5、AIO:Asynchronous I/O, 鸡下蛋后,以前的NIO方式要求饲养员通知农户去取蛋,AIO模式出现以后,事情变得更加简单了,取蛋工作由饲养员自己负责,然后取完后,直接通知农户来拿即可,而不需要农户自己到鸡舍去取蛋。
--应用程序之间网络传输的数据的形式
TCP连接传输的是二进制流,也就是一段一段的101010...,而在一般的网络框架API中,传输形式的是字节(Byte),一个字节为8个二进制位(bit),所以在这里,二进制流和字节流本质上是一样的。
序列化实现需要考虑的因素:
为什么不能直接把内存中,对象对应的二进制数据直接通过网络发送出去,或者保存在文件中呢?为什么还需要序列化和反序列化呢?
答案很简单:因为对象中不只是包含想要传输的数据,还包含这个对象的一些额外的信息,具有语言独特性,如果直接发送过去,有可能接收端语言不通无法识别。而序列化之后,根据约定的序列化格式解析就可以读取数据了。
--传输协议
如何断句呢?给每句话前面加一个表示这句话长度的数字,收到数据的时候,我们按照长度来读取就可以了。
单工协议:

双工协议:

Kafka 有哪些“独门绝技”呢?
1.使用批量消息提升服务端消息处理能力
发送端:Producer只提供了单条send的能力,但是在实际发送时,使用了异步批量发送的机制;攒一波再发送。
Broker端:不会把批消息还原为多条消息,再一条条处理,而是直接处理一个批消息
Consumer端:Consumer 从 Broker 拉到一批消息后,在客户端把批消息解开,再一条一条交给用户代码处理
2.使用顺序读写提升磁盘IO性能
对于磁盘来说它有一个特性,顺序读写的性能要远远好于随机读写,在SSD(固态硬盘)能够达到几倍,在机械硬盘上能够达到几十倍
因为操作系统每次从磁盘读写数据的时候都会寻址,也就是要找到数据在磁盘上的物理位置。
Kafka就是利用了这个特性:
对于每个分区,它把从Producer收到的消息顺序的写入到对应的log文件中,一个文件写满了,就开启一个新文件接着顺序写下去。
消费的时候也是从某个全局的位置开始,也就是从某个log文件的位置开始,顺序的读取消息。
3.实现缓存 - PageCache加速消息读写
PageCache是现代操作系统具备的一种特性,就是操作系统在内存中给磁盘的文件建立缓存。无论我们使用什么语言,在调用操作系统API读写文件时,并不是直接去读写磁盘上的文件,而是操作的PageCache,也就是文件在内存中的副本。
应用程序在写入文件时,操作系统会先写入到PageCache中,然后再一批批的写入到磁盘
应用程序在读取文件时,也是先从PageCache中读取,如果PageCache中有,就直接读取,这样就省去了读取磁盘的时间;若是没有,这时操作系统会引发一个缺页中断,应用程序的读取线程会被阻塞,操作系统把文件复制到PageCache中,再从PageCache中读取。
PageCache的保存策略:
应用程序在使用完某块PageCache后,并不会立即清除而是尽可能地利用空闲的物理内存保存这些 PageCache,除非系统内存不够用,操作系统才会清理掉一部分 PageCache。清理的策略一般是 LRU 或它的变种算法,它保留 PageCache 的逻辑是:优先保留最近一段时间最长使用的PageCache。
Kafka读写消息重新利用了这个特性,一般来说,消息刚刚写到服务端就会被消费。消息队列它的读写比例大致是 1:1
好处:1.读取速度非常快,2.为写入让出磁盘IO资源,间接的提升写入的性能。
4.Zero Copy :零拷贝技术 - 提升消费性能
在服务端处理消息的逻辑为:
1.从磁盘文件中读取数据到PageCache
2.从PageCahce中复制到应用程序的内存中
3.从应用程序的内存空间复制到Socket的缓冲区,这个过程就是我们调用网络框架API的过程。
使用零拷贝技术可以将上面的复制减少一次,上面的2、3步骤两次复制合并为1次复制,直接将PageCache中数据复制到Socket缓冲区中。这样减少一次数据复制,由于不用把数据复制到用户内存空间,DMA 控制器可以直接完成数据复制,不需要 CPU 参与,速度更快。
--硬件同步原语
硬件同步原语(Atomic Hardware Primitives)是由计算机硬件提供的一组原子操作,我们比较常用的原语主要是 CAS 和 FAA 这两种。
CAS(Compare And Swap):先比较,再交换
FAA(Fetch and Add):先获取,然后给变量 增加 值,返回变量之前的值
/**
* 使用锁实现并发转账
*/
private static int balance = 0;
public static void main(String[] args) {
int count = 10000000;
Lock lock = new ReentrantLock();
final CountDownLatch latch = new CountDownLatch(count);
long l = System.currentTimeMillis();
for (int i = 0; i < count; i++) {
//这里未指定线程池,用到的是ForkJoinPool
CompletableFuture.runAsync(() -> transfer(1, lock, latch));
}
System.out.println(balance);
System.out.println("1消耗时间:" + String.valueOf(System.currentTimeMillis() - l));
try {
//假如countDownLatch,等待所有的线程都执行完成再处理结果
latch.await();
} catch (Exception e) {
e.printStackTrace();
}
System.out.println(balance);
System.out.println("2消耗时间:" + String.valueOf(System.currentTimeMillis() - l));
}
public static void transfer(int add, Lock lock, CountDownLatch latch) {
lock.lock();
try {
balance += add;
latch.countDown();
} finally {
lock.unlock();
}
}
/**
* AtomicInteger CAS
*/
private static AtomicInteger balance = new AtomicInteger(0);
public static void main(String[] args) {
int count = 10000000;
final CountDownLatch latch = new CountDownLatch(count);
long l = System.currentTimeMillis();
for (int i = 0; i < count; i++) {
//这里未指定线程池,用到的是ForkJoinPool
CompletableFuture.runAsync(() -> transfer2(1, latch));
}
System.out.println(balance);
System.out.println("1消耗时间:" + String.valueOf(System.currentTimeMillis() - l));
try {
//假如countDownLatch,等待所有的线程都执行完成再处理结果
latch.await();
} catch (Exception e) {
e.printStackTrace();
}
System.out.println(balance);
System.out.println("2消耗时间:" + String.valueOf(System.currentTimeMillis() - l));
}
/**
* cas
*/
public static void transfer(int add, CountDownLatch latch) {
while(true){
int old = balance.get();
if (balance.compareAndSet(old,old + add)){
break;
}
}
latch.countDown();
}
/**
* ffa
*/
public static void transfer2(int add, CountDownLatch latch) {
balance.getAndAdd(add);
latch.countDown();
}
数据压缩:数据压缩不仅能节省存储空间,还可以用于提升网络传输性能
什么时候做数据压缩?
故:数据压缩是一个时间换空间或者说CPU资源换存储资源的游戏,所以要考量系统的瓶颈,是磁盘IO、还是网络带宽、还是CPU;再决定是否需要数据压缩。
常见的压缩算法:ZIP,GZIP(更高的压缩比),SNAPPY,LZ4(压缩速度快) 等
如果要对流数据进行压缩,那必须把流数据划分成多个帧,一帧一帧的分段压缩。一般是对出现频率高、占用内容大的内容使用较短的编码。被压缩的数据长度越大,重码率会更高,压缩比也就越高,但是分段也不是越大越好,容易造成解压浪费。
结论:根据你的业务,选择合适的压缩分段,在压缩率、压缩速度和解压浪费之间找到一个合适的平衡。
Kafka如何处理数据压缩?
Kafka默认不开启压缩。可以配置开启压缩及压缩算法
压缩策略是:
Kafka 选择一批消息一起压缩,每一个批消息就是一个压缩分段。也就是在消息发送方压缩,Broker不解压,在消费方解压。
RocketMQ的压缩代码:
//DefaultMQProducerImpl
private boolean tryToCompressMessage(final Message msg) {
//批次消息不支持
if (msg instanceof MessageBatch) {
//batch dose not support compressing right now
return false;
}
byte[] body = msg.getBody();
if (body != null) {
//如果消息体的长度大于4K
if (body.length >= this.defaultMQProducer.getCompressMsgBodyOverHowmuch()) {
try {
//使用zip算法,级别为5
byte[] data = UtilAll.compress(body, zipCompressLevel);
if (data != null) {
msg.setBody(data);
return true;
}
} catch (IOException e) {
log.error("tryToCompressMessage exception", e);
log.warn(msg.toString());
}
}
}
return false;
}
rocketmq release-4.5.1源码阅读
init - 启动过程 - 实现:org.apache.rocketmq.client.impl.producer.DefaultMQProducerImpl#start(boolean)
send - 消息发送 - 实现:org.apache.rocketmq.client.impl.producer.DefaultMQProducerImpl#send(org.apache.rocketmq.common.message.Message)
在 Producer 的接口 MQProducer 中,按照发送方式不同可以分成三类:
switch (communicationMode) {
case ONEWAY:
this.remotingClient.invokeOneway(addr, request, timeoutMillis);
return null;
case ASYNC:
final AtomicInteger times = new AtomicInteger();
long costTimeAsync = System.currentTimeMillis() - beginStartTime;
if (timeoutMillis < costTimeAsync) {
throw new RemotingTooMuchRequestException("sendMessage call timeout");
}
this.sendMessageAsync(addr, brokerName, msg, timeoutMillis - costTimeAsync, request, sendCallback, topicPublishInfo, instance,
retryTimesWhenSendFailed, times, context, producer);
return null;
case SYNC:
long costTimeSync = System.currentTimeMillis() - beginStartTime;
if (timeoutMillis < costTimeSync) {
throw new RemotingTooMuchRequestException("sendMessage call timeout");
}
return this.sendMessageSync(addr, brokerName, msg, timeoutMillis - costTimeSync, request);
default:
assert false;
break;
}
Kafka消息消费源码
订阅:org.apache.kafka.clients.consumer.KafkaConsumer#subscribe(java.util.Collection<java.lang.String>, org.apache.kafka.clients.consumer.ConsumerRebalanceListener)
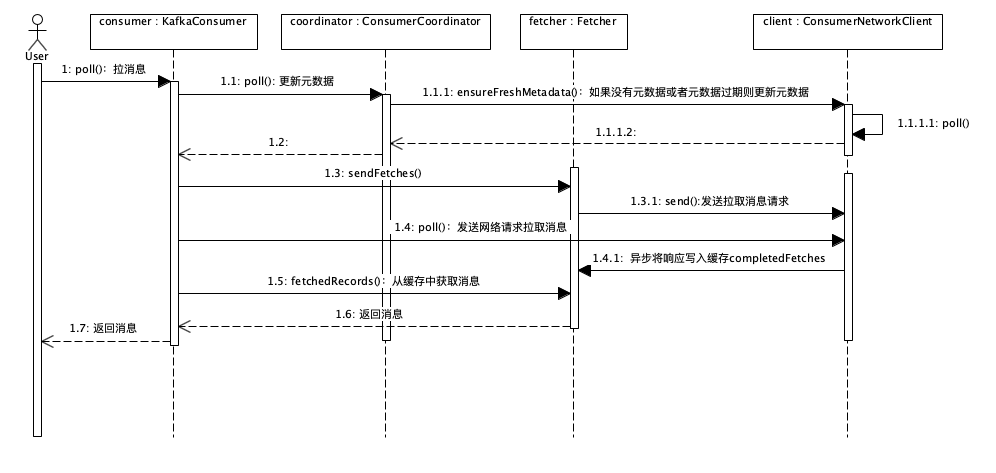
怎么保证消息不会丢失:
生产和消费两端:基于“请求和确认”机制和业务代码,来确保消息不会丢失。
在服务端(Broker):一般采用持久化和复制的方式
复制的方式:把消息复制到多个节点,不仅可以解决丢消息的问题,还可以保证消息服务的高可用,即使某一个节点宕机了,也可以使用其他节点来收发消息,所以大部分生产系统都会把消息队列配置成集群模式,开启消息复制。
消息复制面临的问题:
高性能:消息复制写入的节点越多,可用性和数据可靠性就越好,但是写入性能就越低,这是一个天然的矛盾。对消息消费不影响。
一致性:采用“主-从”的复制方式
高可用:需要解决当某个主节点宕机了,尽快选出一个节点接替主节点。
1.节点自选举:还存活的节点通过投票,选择一个主节点;优点是:没有外部依赖,可以实现自我管理。缺点是:投票的实现都比较复杂,并且选举的过程是比较慢的,选举过程一直不可用。
2.大部分复制的实现,都不会选择把消息写入全部副本再返回确认
18年的时候迎来了一次重大的更新:引入 Deldger,增加了一种全新的复制方式。
传统的复制方式:
复制的基本单位为Broker,复制也是采用的主从方式,通常情况下配置成一主一从,也可以配置成一主多从。
两种复制方式:
异步复制:消息先发到主节点上,就返回“写入成功”,然后消息再复制到从节点
RocketMQ中的主从关系是配置固定的,不支持动态切换。如果主节点宕机了,生产者就不能生产消息了,消费者可以自动切换到从节点消费消息;即使有一些消息没来及复制到从节点,依然在主节点的磁盘上,除非主节点的磁盘坏了,否则主节点恢复福的时候,就能把这些消息同步到从节点,再由消费者消费。 - 结果是:不会丢消息,消息的顺序也是没有问题的。缺点是牺牲了一部分的可用性。换取了比较好的性能和数据一致性。
同步双写:消息同步写到主从节点上,都写入成功在返回成功。
本质区别是:写入多少副本再返回成功的问题。在返回成功前,如果写入的副本数不够多,那就回丢消息。
RocketMQ如何保证可用性:
既然一对主从可能会出现不可用的问题,那就再来多个主从节点,同时支持同一个主题的不同队列分布在多对主从节点上去,每对主从节点承担主题中的一部分队列。如果某个主节点宕机了,会自动切换到其他主节点上发消息。这样既解决了部分可用性问题,还通过水平扩容提升Topic性能。
还有一些问题:如果是保证消息顺序一致性的前提下,在主题层面无法保证顺序,只能执行队列来发送消息,这样当这个主节点宕机了,就不能切换到其他主节点。
基于上诉问题:RocketMQ 引入 Dledger,使用新的复制方式
Dledger复制
Dledger在写消息的时候,要求消息复制到半数以上的节点之后,才给客户端返回写入成功,并且它是支持通过选举来动态切换主节点的。
demo:假如有3个节点,主节点宕机了,2个从节点会通过投票选出一个新的主节点来提供服务,相比主从的复制模式,解决了可用性的问题。由于消息至少写入到两个节点才会返回成功,即使主节点宕机了,也至少有另一个从节点的消息跟主节点是一样的,在选举时,总是把数据跟主节点一样的从节点选举为主节点,这样就保证了数据的一致性。
缺点:
选举过程不能提供服务
至少需要3个节点才能保证数据的一致性,3个节点,只能保证一个节点宕机时可用,一旦两个节点同时宕机,即使还有一个节点也无法提供服务,造成部分资源浪费。
另外由于需要至少写入2个节点才返回成功,所以性能上并没有主从异步复制快。
Kafka实现复制的方式
Kafka复制的基本单位是分区。每个分区的几个副本之间,构成一个小的复制集群,Broker是这些分区集群的容器。Kafka的Broker是不分主从的。
分区的多个副本也是采用一主多从的方式,在写入消息的时候使用的也是异步复制,消息在写入到主节点之后,并不会马上返回成功,而是等待足够多的节点都返回成功后再返回
“足够多”的名词为:ISR:保持数据同步的副本,数量是可配置的,注意:这个数量是包含主节点的。
Kafka 使用 ZooKeeper 来监控每个分区的多个节点,如果发现某个分区的主节点宕机了,Kafka 会利用 ZooKeeper 来选出一个新的主节点。
默认情况下,如果所有的ISR都宕机,那么分区就无法同步服务了,也可以配置成让分区继续提供服务,这样只要有一个节点存活就可以提供服务,缺点是会丢失消息。
问题:
假设我们有一个 5 节点的 RocketMQ 集群,采用 Dledger5 副本的复制方式,集群中只有一个主题,50 个队列均匀地分布到 5 个 Broker 上。如果需要你来配置一套 Kafka 集群,要求达到和这个 RocketMQ 集群一样的性能(不考虑 Kafka 和 RocketMQ 本身的性能差异)、可用性和数据一致性,该如何配置?
答:5副本,10个分区,至少保持isr集合中有三个broker
在RocketMQ使用NameServer来作为协调器,使Broker、生产者、消费者之间能够通信。
NameServer的作用:作为一个独立的进程,为Broker、生产者和消费者提供服务,为客户端提供寻址服务,帮助客户端找到topic对应的broker地址;监控每个broker的存活状态。
NameServer的部署:可以单节点,可以集群式部署,集群式部署各个节点之间并不通信,每个节点可以独立提供全部的服务。
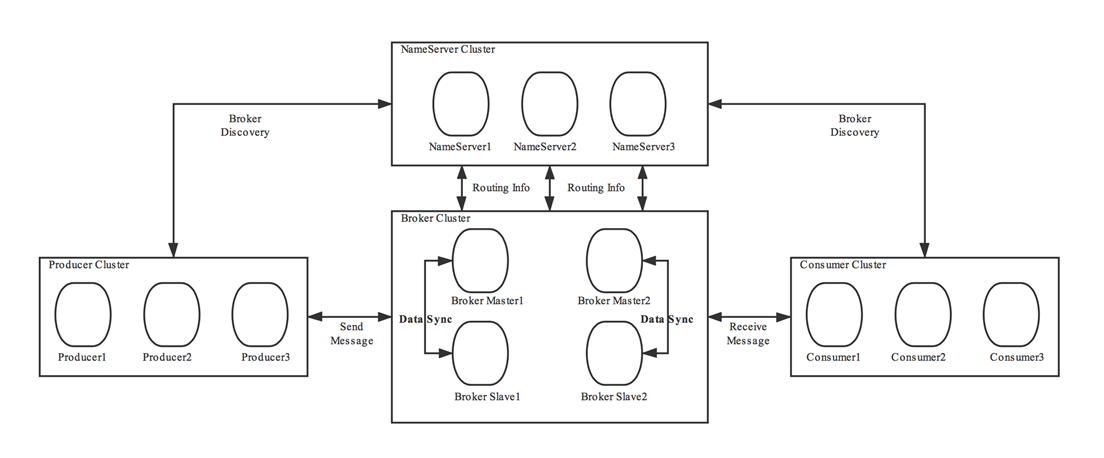
NameServer的工作过程:
1.路由注册:每个broker启动的时候都要和所有的NameServer通信,来保证NameServer信息的完整性。
2.当Broker保存的topic信息发生变化时,也会主动通知NameServer更新路由信息
3.心跳:Broker定时(每隔30秒)给所有的Broker节点上报路由信息,1是为了保证数据的一致性,另外也是为了监控Broker的健康状态。
4.路由剔除:若是Broker没有定时上报路由信息(默认2分钟),则认为Broker下线,NameServer会移除这个Broker的信息,避免客户端连接一个不可用的Broker
5.路由发现:主要是针对生产者和消费者-统称客户端,客户端会定时(30秒)挨个topic从NameServer拉取Broker的信息。当Broker与客户端通信失败之后,会重新从NameServer拉取信息,然后连接到其他Broker继续生产或者消费,这样实现了自动切换(依赖于重试机制)
稍微介绍下RocketMQ的消费类型:
1. 普通消息:可以重试(默认重试2次),发送到哪个队列都可以,无序
2.普通有序消息:不能重试 动态决定需要发送到哪个队列,除非出现异常情况才会发送到其他队列
3.严格有序消息:不能重试,明确指定到发送的队列
问题来了,为什么RocketMQ选择了NameServer,而不是使用Kafka中类似的Zookeeper?
Zk具备NameServer的所有功能,同时还能够进行master选举、服务治理等,功能完备,为什么还要被放弃呢,
放弃的原因:
1.zk功能太齐全了,RocketMQ只需要轻量级的数据服务,保证最终一致性,而不是强一致性。
2.减少中间件依赖,减少维护成本
结论:根据CAP理论,Rocket在NameServer设计上选择了AP
C(Consistency):一致性 NameServer实例间不通信,某个时间,实例中的数据会不同
A(Availability):有效性 有一个节点存活就能提供服务
P(Partiton Tolerance):分区容错性 NameServer节点多机房部署等等.
源码解读:
NameServer中主要存储的信息主要是几个map:在 RouteInfoManager 中
//这里存储的是topic和队列的信息 ,其中每个队列信息对应的QueueData还保存了对应的brokerName - 这里的broker是一组broker,比如一个主节点+多个从节点 private final HashMap<String/* topic */, List<QueueData>> topicQueueTable; //保存了集群每一个brokerName对应的broker的信息 private final HashMap<String/* brokerName */, BrokerData> brokerAddrTable; //集群名称 和 broker名称的对应关系 private final HashMap<String/* clusterName */, Set<String/* brokerName */>> clusterAddrTable; //每个broker当前的动态信息,心跳的更新时间,路由数据版本等 private final HashMap<String/* brokerAddr */, BrokerLiveInfo> brokerLiveTable; //每个broker对应的消息过滤服务的地址,用于服务端消息过滤 private final HashMap<String/* brokerAddr */, List<String>/* Filter Server */> filterServerTable;
入口:DefaultRequestProcessor#processRequest
实际处理方法:RouteInfoManager#registerBroker

public RegisterBrokerResult registerBroker( final String clusterName, final String brokerAddr, final String brokerName, final long brokerId, final String haServerAddr, final TopicConfigSerializeWrapper topicConfigWrapper, final List<String> filterServerList, final Channel channel) { RegisterBrokerResult result = new RegisterBrokerResult(); try { try { //使用了读写锁,这里为写锁 this.lock.writeLock().lockInterruptibly(); //获取当前的集群名称对应的broker名称 Set<String> brokerNames = this.clusterAddrTable.get(clusterName); if (null == brokerNames) { brokerNames = new HashSet<String>(); this.clusterAddrTable.put(clusterName, brokerNames); } //将当前的broker加入到set中 brokerNames.add(brokerName); boolean registerFirst = false; //判断是否为第一次注册 BrokerData brokerData = this.brokerAddrTable.get(brokerName); if (null == brokerData) { //若是原来的brokerMap中没有,就认为是第一次注册 registerFirst = true; brokerData = new BrokerData(clusterName, brokerName, new HashMap<Long, String>()); this.brokerAddrTable.put(brokerName, brokerData); } Map<Long, String> brokerAddrsMap = brokerData.getBrokerAddrs(); //获取到broker的地址 //Switch slave to master: first remove <1, IP:PORT> in namesrv, then add <0, IP:PORT> //The same IP:PORT must only have one record in brokerAddrTable Iterator<Entry<Long, String>> it = brokerAddrsMap.entrySet().iterator(); while (it.hasNext()) { Entry<Long, String> item = it.next(); //把不等于当前brokerId的节点都去掉 if (null != brokerAddr && brokerAddr.equals(item.getValue()) && brokerId != item.getKey()) { it.remove(); } } //把新的broker地址放入map,得到老的地址 String oldAddr = brokerData.getBrokerAddrs().put(brokerId, brokerAddr); registerFirst = registerFirst || (null == oldAddr); if (null != topicConfigWrapper && MixAll.MASTER_ID == brokerId) { //当前为brokerId的master,并且是第一次注册 ,或者是broker中的信息变更了 if (this.isBrokerTopicConfigChanged(brokerAddr, topicConfigWrapper.getDataVersion()) || registerFirst) { ConcurrentMap<String, TopicConfig> tcTable = topicConfigWrapper.getTopicConfigTable(); if (tcTable != null) { //处理broker对应的topic对应的信息 进行更新 for (Map.Entry<String, TopicConfig> entry : tcTable.entrySet()) { this.createAndUpdateQueueData(brokerName, entry.getValue()); } } } } //更新:brokerLiveTable BrokerLiveInfo prevBrokerLiveInfo = this.brokerLiveTable.put(brokerAddr, new BrokerLiveInfo( System.currentTimeMillis(), topicConfigWrapper.getDataVersion(), channel, haServerAddr)); if (null == prevBrokerLiveInfo) { log.info("new broker registered, {} HAServer: {}", brokerAddr, haServerAddr); } //更新filterServerTable if (filterServerList != null) { if (filterServerList.isEmpty()) { this.filterServerTable.remove(brokerAddr); } else { this.filterServerTable.put(brokerAddr, filterServerList); } } //如果当前broker不是master,那么结果中需要带上master的地址 if (MixAll.MASTER_ID != brokerId) { String masterAddr = brokerData.getBrokerAddrs().get(MixAll.MASTER_ID); if (masterAddr != null) { BrokerLiveInfo brokerLiveInfo = this.brokerLiveTable.get(masterAddr); if (brokerLiveInfo != null) { result.setHaServerAddr(brokerLiveInfo.getHaServerAddr()); result.setMasterAddr(masterAddr); } } } } finally { //释放锁 this.lock.writeLock().unlock(); } } catch (Exception e) { log.error("registerBroker Exception", e); } return result; }
入口:RouteInfoManager#pickupTopicRouteData
/** * 根据topic找到topic的路由信息 */ public TopicRouteData pickupTopicRouteData(final String topic) { //// 初始化返回数据 topicRouteData TopicRouteData topicRouteData = new TopicRouteData(); boolean foundQueueData = false; boolean foundBrokerData = false; Set<String> brokerNameSet = new HashSet<String>(); List<BrokerData> brokerDataList = new LinkedList<BrokerData>(); topicRouteData.setBrokerDatas(brokerDataList); HashMap<String, List<String>> filterServerMap = new HashMap<String, List<String>>(); topicRouteData.setFilterServerTable(filterServerMap); try { try { //加读锁 this.lock.readLock().lockInterruptibly(); //获取这个主题对应的队列的信息 List<QueueData> queueDataList = this.topicQueueTable.get(topic); if (queueDataList != null) { //把队列信息放在topic的队列路由信息中 topicRouteData.setQueueDatas(queueDataList); foundQueueData = true; //遍历队列 Iterator<QueueData> it = queueDataList.iterator(); while (it.hasNext()) { QueueData qd = it.next(); brokerNameSet.add(qd.getBrokerName()); } //遍历broker信息 for (String brokerName : brokerNameSet) { BrokerData brokerData = this.brokerAddrTable.get(brokerName); if (null != brokerData) { //复制一个broker信息 BrokerData brokerDataClone = new BrokerData(brokerData.getCluster(), brokerData.getBrokerName(), (HashMap<Long, String>) brokerData .getBrokerAddrs().clone()); //放入到list中 brokerDataList.add(brokerDataClone); foundBrokerData = true; for (final String brokerAddr : brokerDataClone.getBrokerAddrs().values()) { List<String> filterServerList = this.filterServerTable.get(brokerAddr); filterServerMap.put(brokerAddr, filterServerList); } } } } } finally { //释放du‘suo this.lock.readLock().unlock(); } } catch (Exception e) { log.error("pickupTopicRouteData Exception", e); } log.debug("pickupTopicRouteData {} {}", topic, topicRouteData); if (foundBrokerData && foundQueueData) { return topicRouteData; } return null; }
简单说下Zookeeper:
定义:是一个分布式协调框架,主要解决分布式集群中的一致性的问题
功能:
1.分布式存储系统,提供了类似文件系统的树形结构。
2.zk在树形的存储结构中,每个节点都是一个“ZNode”,同时提供了临时节点。
临时节点的特性:如果创建临时节点的客户端与zk丢失了连接,临时节点也会自动消失。
3.ZNode状态变化通知机制“Watcher”,一旦ZNode和它的子节点状态发生变化时,客户端会收到通知。
Kafka在zk中保存了什么信息?
如图所示:
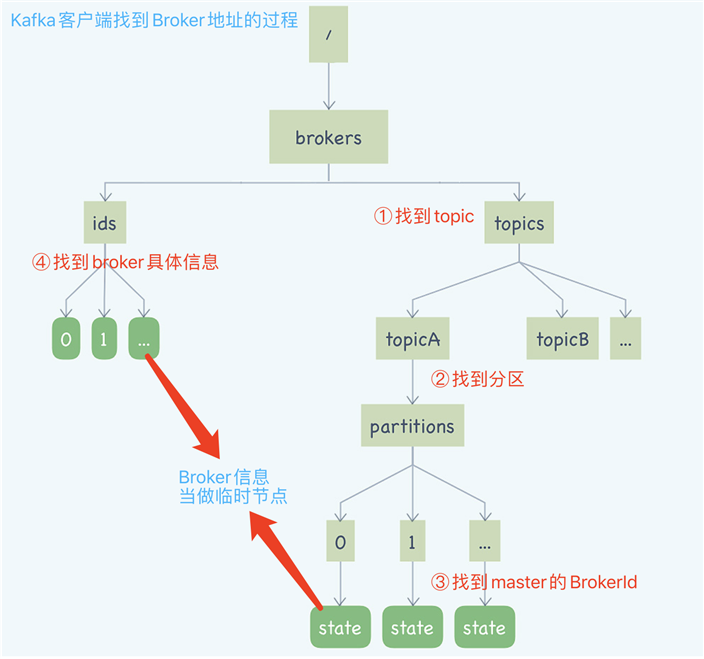 (注:圆角矩形为临时节点,直角矩形为持久化节点)
(注:圆角矩形为临时节点,直角矩形为持久化节点)
Kafka的客户端并不会直连ZK,ZK中的元数据信息通过Broker转发给每个客户端。
源码:
入口:客户端同Broker发生网络传输入口: org.apache.kafka.clients.NetworkClient#poll
调用链:NetworkClient#poll() -> DefaultMetadataUpdater#maybeUpdate(long) -> DefaultMetadataUpdater#maybeUpdate(long, Node)
producer发送事务消息
入口:org.apache.rocketmq.client.producer.TransactionMQProducer#sendMessageInTransaction(org.apache.rocketmq.common.message.Message, java.lang.Object)
public TransactionSendResult sendMessageInTransaction(final Message msg, final LocalTransactionExecuter localTransactionExecuter, final Object arg) throws MQClientException { TransactionListener transactionListener = getCheckListener(); if (null == localTransactionExecuter && null == transactionListener) { throw new MQClientException("tranExecutor is null", null); } Validators.checkMessage(msg, this.defaultMQProducer); SendResult sendResult = null; //1.对消息添加属性,表明这是一个事务消息,也就是半消息。 MessageAccessor.putProperty(msg, MessageConst.PROPERTY_TRANSACTION_PREPARED, "true"); MessageAccessor.putProperty(msg, MessageConst.PROPERTY_PRODUCER_GROUP, this.defaultMQProducer.getProducerGroup()); //2.发送半消息 try { sendResult = this.send(msg); } catch (Exception e) { throw new MQClientException("send message Exception", e); } LocalTransactionState localTransactionState = LocalTransactionState.UNKNOW; Throwable localException = null; switch (sendResult.getSendStatus()) { case SEND_OK: { try { if (sendResult.getTransactionId() != null) { msg.putUserProperty("__transactionId__", sendResult.getTransactionId()); } String transactionId = msg.getProperty(MessageConst.PROPERTY_UNIQ_CLIENT_MESSAGE_ID_KEYIDX); if (null != transactionId && !"".equals(transactionId)) { msg.setTransactionId(transactionId); } //3.执行本地事务 if (null != localTransactionExecuter) { localTransactionState = localTransactionExecuter.executeLocalTransactionBranch(msg, arg); } else if (transactionListener != null) { log.debug("Used new transaction API"); // 3.1这里就是我们实现的执行本地事务的方法 localTransactionState = transactionListener.executeLocalTransaction(msg, arg); } if (null == localTransactionState) { localTransactionState = LocalTransactionState.UNKNOW; } if (localTransactionState != LocalTransactionState.COMMIT_MESSAGE) { log.info("executeLocalTransactionBranch return {}", localTransactionState); log.info(msg.toString()); } } catch (Throwable e) { log.info("executeLocalTransactionBranch exception", e); log.info(msg.toString()); localException = e; } } break; case FLUSH_DISK_TIMEOUT: case FLUSH_SLAVE_TIMEOUT: case SLAVE_NOT_AVAILABLE: localTransactionState = LocalTransactionState.ROLLBACK_MESSAGE; break; default: break; } try { //4.根据发送半消息的结果和执行本地事务的结果,来判断如何处理后续流程 //判断是提交还是回滚 this.endTransaction(sendResult, localTransactionState, localException); } catch (Exception e) { log.warn("local transaction execute " + localTransactionState + ", but end broker transaction failed", e); } TransactionSendResult transactionSendResult = new TransactionSendResult(); transactionSendResult.setSendStatus(sendResult.getSendStatus()); transactionSendResult.setMessageQueue(sendResult.getMessageQueue()); transactionSendResult.setMsgId(sendResult.getMsgId()); transactionSendResult.setQueueOffset(sendResult.getQueueOffset()); transactionSendResult.setTransactionId(sendResult.getTransactionId()); transactionSendResult.setLocalTransactionState(localTransactionState); return transactionSendResult; }
private MessageExtBrokerInner parseHalfMessageInner(MessageExtBrokerInner msgInner) { //记录当前消息的主题和队列到新的属性中 MessageAccessor.putProperty(msgInner, MessageConst.PROPERTY_REAL_TOPIC, msgInner.getTopic()); MessageAccessor.putProperty(msgInner, MessageConst.PROPERTY_REAL_QUEUE_ID, String.valueOf(msgInner.getQueueId())); msgInner.setSysFlag( MessageSysFlag.resetTransactionValue(msgInner.getSysFlag(), MessageSysFlag.TRANSACTION_NOT_TYPE)); // 替换消息的主题和队列为:RMQ_SYS_TRANS_HALF_TOPIC,0 //这个主题和队列对于消费者来说是不可见的,所以消息里的数据不可能被消费,这样就保证,在事务成功提交之前,这个半消息对于消费者来说是消费不到的。 msgInner.setTopic(TransactionalMessageUtil.buildHalfTopic()); msgInner.setQueueId(0); msgInner.setPropertiesString(MessageDecoder.messageProperties2String(msgInner.getProperties())); return msgInner; }
Broker事务反查 - 基于定时任务
入口:org.apache.rocketmq.broker.transaction.TransactionalMessageCheckService#run -> org.apache.rocketmq.broker.transaction.TransactionalMessageCheckService#onWaitEnd -> org.apache.rocketmq.broker.transaction.queue.TransactionalMessageServiceImpl#check
-> org.apache.rocketmq.broker.transaction.AbstractTransactionalMessageCheckListener#resolveHalfMsg -> org.apache.rocketmq.broker.transaction.AbstractTransactionalMessageCheckListener#sendCheckMessage
Broker提交事务或者回滚
入口:org.apache.rocketmq.broker.processor.EndTransactionProcessor
Rocket MQ中的事务:
解决问题:确保本地事务和发消息两个操作,要么都成功,要么都失败。并且Rocket MQ增加了一个事务反查的机制,来尽量提高事务执行的成功率和事务一致性。
Kafka的事务:
解决问题:确认在一个事务中发送的多条消息,要么都发送成功,要么都发送失败。(使用场景不多)
通常的Exactly Once:
消息从生产者发送到Broker,消费者再从Broker拉取消息,再进行消费。在这个过程中,确保每一条消息确保恰好传输一次,不重不丢。
Kafka的 Exactly Once:
在流计算中,用Kafka作为数据源,并且将计算结果保存到Kafka的这种场景下,数据从Kafka的某个主题中消费,在计算集群中计算,再把计算结果保存到Kafka的其他主题中。保证每条消息恰好被计算一次,确保计算结果正确。
Kafka的事务如何实现?
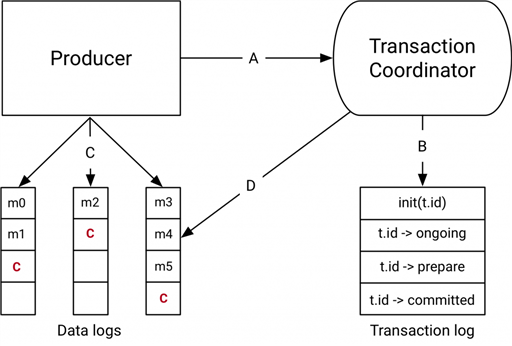
实现流程:
1.开启事务:生产者给协调者发起请求开启事务,协调者在事务日志中记录下事务id
2.给协调者发送请求,告知发送的消息的主题和分区
3.生产者发送消息
注:这里Kafka同Rocket MQ不同,Rocket MQ是在Broker中设置了一个特殊的队列,不能让消费者消费;Kafka却是当做一个正常消息,能够被消费者拉取,只是拉取到客户端了,再由客户端暂时过滤。
4.消息发送完成:生产者给协调者发送消息,告知事务提交或者事务回滚,由协调者开启两阶段提交,完成事务。
5.第一阶段:协调者把事务状态写入到事务日志,并设置为“预提交”,到这一步,无论后续出现什么问题,事务最终都会被提交。
6.第二结算:协调者在跟事务相关的每个分区,写入一条“事务结束”的消息;当消费者读取到事务结束的消息后,会把之前暂时过滤的消息放行给业务代码消费。
7.协调者记录最后一条事务日志,标识事务结束。
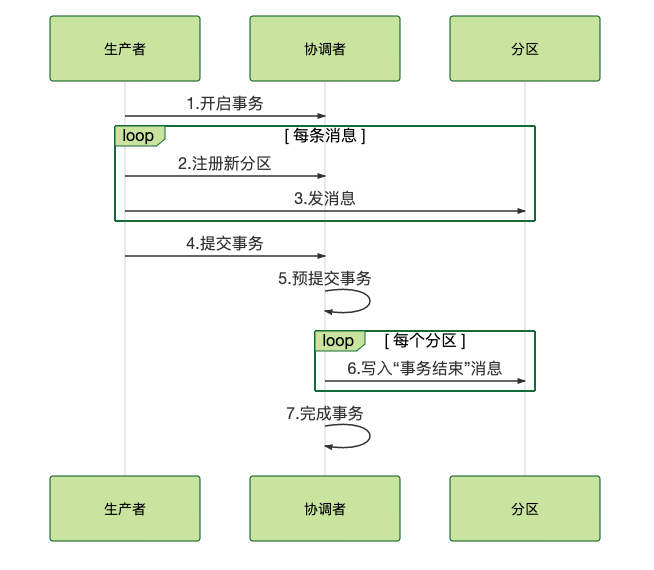 (Kafka事务的时序图)
(Kafka事务的时序图)
有状态:节点上存储了数据
无状态:节点上不保存数据
那么可知:Rocket MQ 和Kafka的Broker节点都是有节点,因为他们把数据存储在节点上。
新一代消息中间件:Pulsar
Pulsar的Broker是无状态
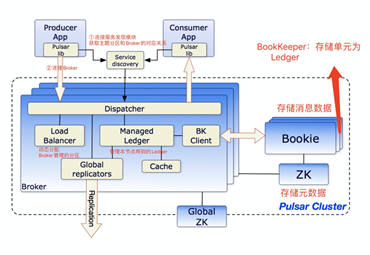
名词解释:
BookKeeper:分布式存储集群,存储消息数据
Zk:存储元数据
Ledger:一段WAL(Write Ahead Log),包含连续的若干条消息
Entry:消息在Ledger称为Entry
为了保证 Ledger 中的 Entry 的严格顺序,Pulsar 为 Ledger 增加一次性的写入限制,Broker 创建一个 Ledger 后,只有这个 Broker 可以往 Ledger 中写入 Entry,一旦 Ledger 关闭后,无论是 Broker 主动关闭,还是因为 Broker 宕机异常关闭,这个 Ledger 就永远只能读取不能写入
存储计算分离的优点:
1.对于计算节点,不需要进行数据存储,变为无状态节点,一个无状态节点组成的集群、管理、调度都变得非常简单;天然就支持水平扩展;任意一个请求都可以打到任意一个节点上,负载均衡非常灵活;故障转移也很简单,直接把请求转发到其他节点就可以了;
像ZK这种存储与计算不分离的,故障转移就十分麻烦,选举Leader就复杂。
2.对于存储节点,实现的功能十分专注就可以了
缺点:
1.Broker并没有解决问题,只是把问题抛给了BookKeeper,存储计算分离之后,原来一个集群变成了两个集群,整个系统其实变得更加复杂了
2.存储计算分离之后,性能上有一定的损失。比如消费一条消息,Broker还需要从BookKeeper读取数据,再返回客户端,增加了网络请求和内存拷贝。
不过:相对来说,存储计算分离是利用现有的技术,也是减少了复杂度,损失一些性能也是可以接受的。
Kafka和Rocket MQ的选举
Kafka的选举
Kafka使用ZK监控每个分区的多个副本,如果发现某个分区的主节点宕机了,Controller会受到ZK的通知,Controller会从ISR中重新选择一个主节点。
Controller本身也是通过ZK选举产生的。
在Broker启动后,都会尝试在ZK中创建一个临时节点,/controller,并把信息写到这个节点中,并且只有一个Broker能创建这个节点,那么这个Broker就是leader节点,其他没抢到的,就会Watch这个节点。
这个算法虽然不怎么优雅,但胜在简单直接,并且快速公平,是非常不错的选举方法。
RocketMQ的选举:
仅仅靠集群中的节点投票来选举Leader,自我选举的算法, 只会在集群内部进行,同事算法也会十分复杂,一般要进行多次选举。Dledger 采用的是Raft 一致性算法
原文:https://www.cnblogs.com/fengtingxin/p/14414073.html
