InnoDB 里面每个事务有一个唯一的事务 ID,叫作 transaction id。它是在事务开始的时候向 InnoDB 的事务系统申请的,是按申请顺序严格递增的。
每行数据有多个版本,每次事务更新数据的时候,都会生成一个新的数据版本,并且把 transaction id 赋值给这个数据版本的事务 ID,记为 row trx_id。同时,旧的数据版本要保留,并且在新的数据版本中,可以直接拿到它。
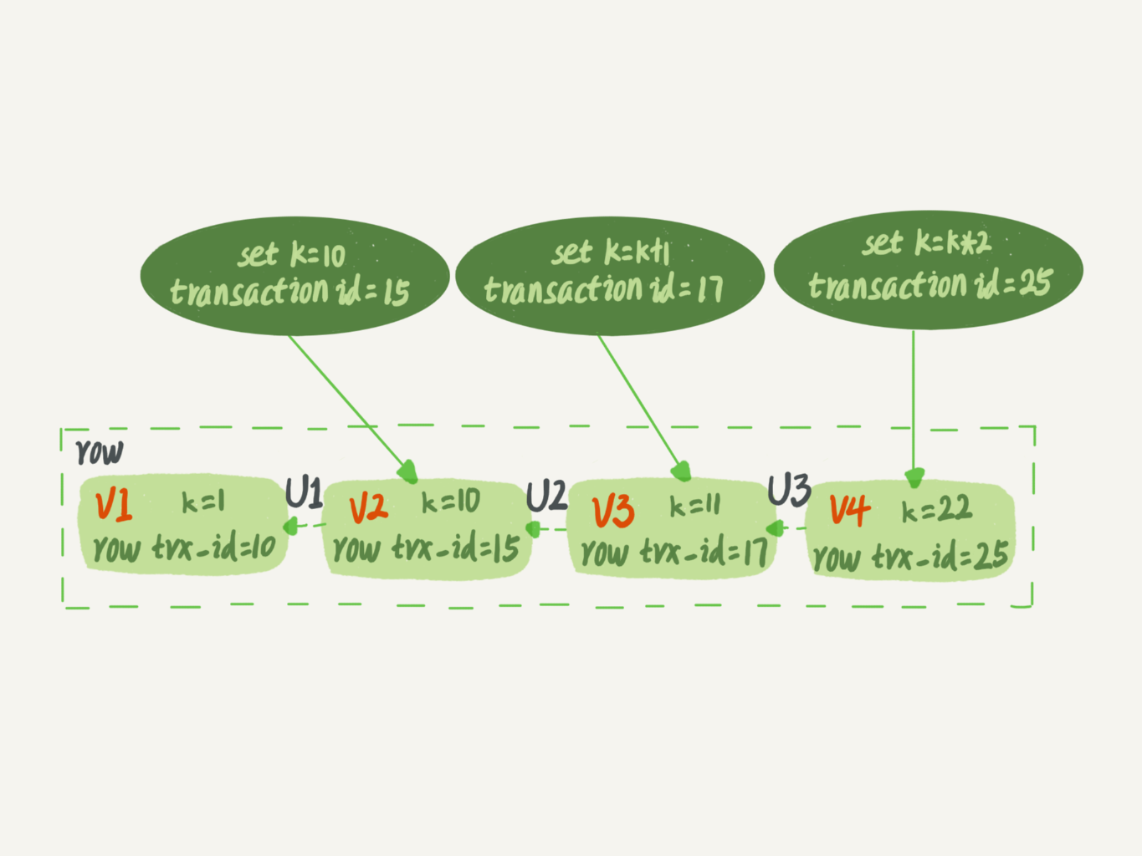
上图中三个虚线箭头,即U1、U2、U3就是 undo log,而V1、V2、V3 并不是物理上真实存在的,而是每次需要的时候根据当前版本和 undo log 计算出来的
快照是基于整库的,如何构建的?
按照可重复读的定义,一个事务启动的时候,能够看到所有已经提交的事务结果,但是之后的事务执行期间,其他事务的更新对它不可见。
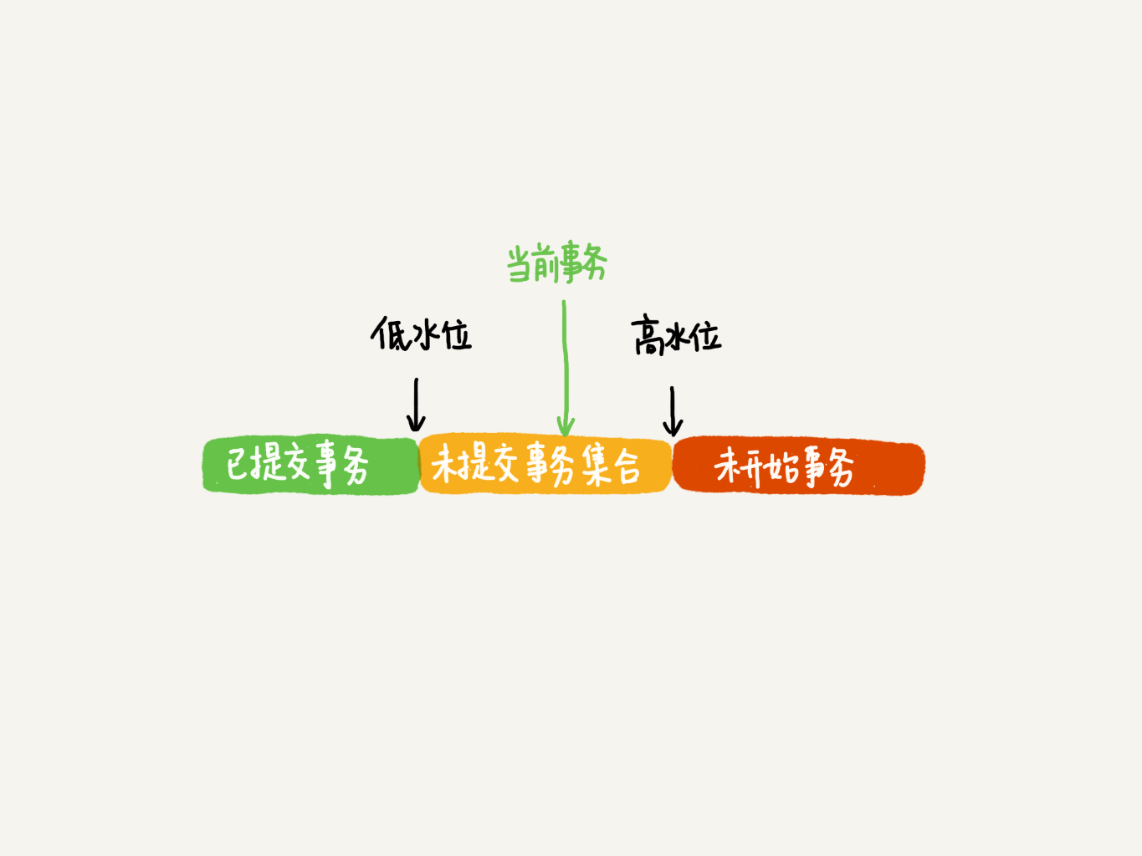
在实现上, InnoDB 为每个事务构造了一个数组,用来保存这个事务启动瞬间,当前正在“活跃”的所有事务 ID,即启动了但还没提交的事务ID,对应上图中黄色部分。这个数组对应两个概念:
由视图数组和高水位,组成了当前事务的一致性视图(read-view),而数据版本的可见性规则,就是基于数据的 row trx_id 和这个一致性视图的对比结果得到的,如下所示:
-- 假设存在事务T1,T2,T4,T7,T8,T9,其中T2,T4,T8活跃状态,此刻启动事务A
-- 事务A的视图数组viewA如下
viewA = [T2,T4,T8]
-- 低水位
lowLevel = T2
-- 高水位
highLevel = T9 + 1
-- T1:T1 < T2,即处于绿色部分,对于事务A可见
-- T11:T11 > T10,即处于红色部分,对于事务A不可见
-- T4:T4 > T2 && T4 < T10,即处于黄色部分,且存在viewA中,说明未提交不可见
-- T7:T7 > T2 && T7 < T10,即处于黄色部分,但不存在viewA中,说明已提交可见
MVCC只在读已提交和可重复读两个隔离级别下工作,两者的差异在于:
原文:https://www.cnblogs.com/sheung/p/14554591.html