深圳浪尖 浪尖聊大数据
receiver个数 KafkaUtils.createStream调用次数决定,调用一次产生一个receiver
al topicMap = Map("page_visits" -> 1) map的value对应的数值实际上是消费的线程个数。
前情:基于reciver kafka java客户端消费者高阶API
根据数据量来调整block的生成周期。
a). 增加executor
b). repartition增加分区
c). 调整数据本地性 spark.locality.wait 假如任务都是3s以内执行结束,就会导致越来越多的任务调度到数据存在的executor上执行,最终导致executor执行的任务失衡。
kafka 082 高阶消费者api,有分组的概念。当然就会产生一个问题,消费者组内的线程数,和kafka分区数的对应关系。
checkpoint 目的是从driver故障恢复或者恢复upstatebykey等状态
9 限制消费者最大速率
1. spark.streaming.backpressure.enabled
默认是false,设置为true,就开启了背压机制。
2. spark.streaming.backpressure.initialRate
默认没设置,初始速率。第一次启动的时候每个receiver接受数据的最大值。
3. spark.streaming.receiver.maxRate
默认值没设置。每个接收器将接收数据的最大速率(每秒记录数)。
实际上,每个流每秒最多将消费此数量的记录。 将此配置设置为0或负数将不会对速率进行限制。10。 spark.streaming.stopGracefullyOnShutdown
on yarn 模式kill的时候是立即终止程序的,无效。
未加入wal的基于recevier的dstream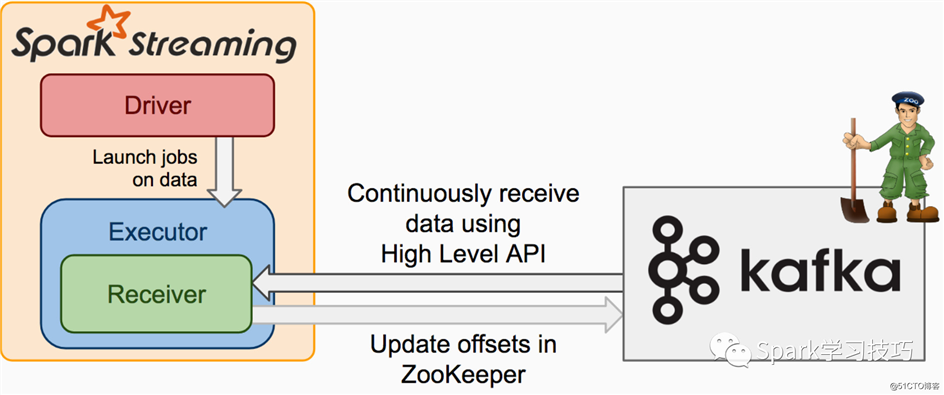
加入wal的Dstream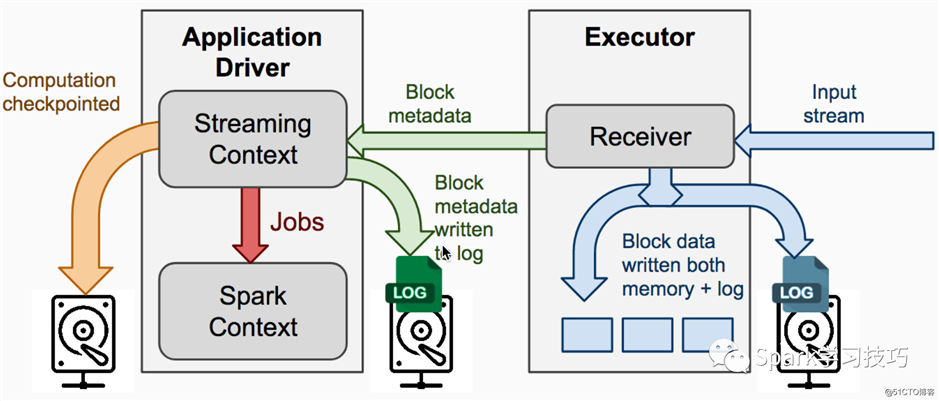
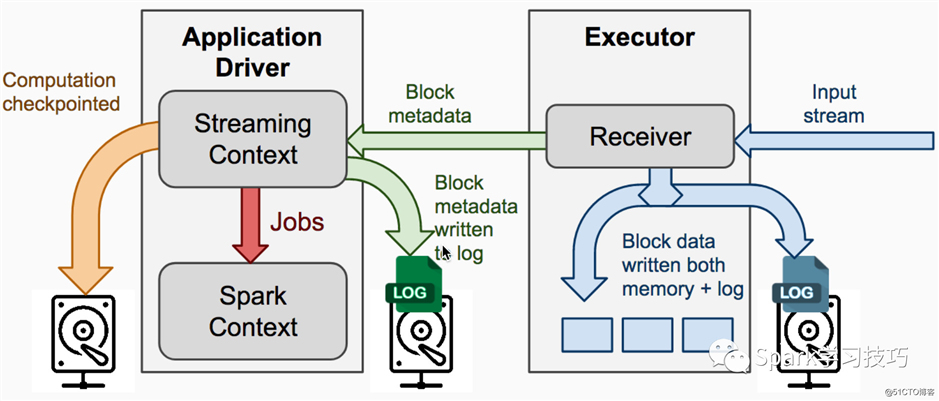
存checkpoint和wal的过程
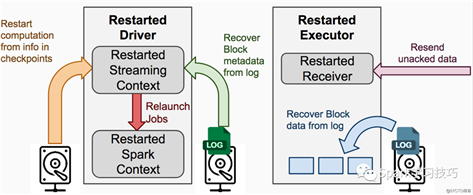
故障恢复图解
视频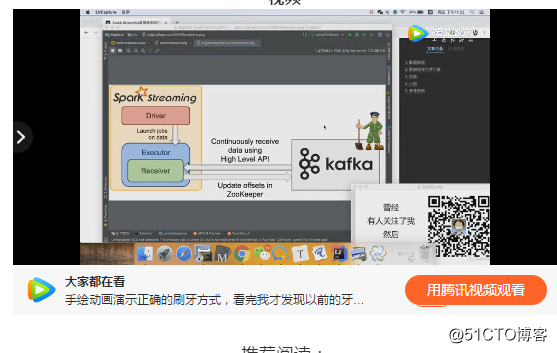
https://v.qq.com/x/page/x0704oo7k06.html
原文:https://blog.51cto.com/15127544/2665110