通配符号用来按照文件名称进行匹配查找。
*: 表示匹配所有内容信息
{}:生成一行序列信息,可以是连续的序列也可以是非连续的序列;生成组合序列
系统正则符号用来方便匹配查找文件中的内容信息,分为基础正则表达式和扩展正则表达式
^:匹配行首
$:匹配行尾
^$:匹配空行
.:匹配任意一个字符
*:匹配前面字符出现次数0次或1次以上
.*:匹配所有信息,包含空行
[]:匹配[ ] 范围中任意一个字符
[^] :匹配[ ] 范围外任意一个字符
\:转义字符,常用\n,\t,\r等
?:匹配前面字符出现0次或1次
+ :匹配前面字符出现1次或多次
|:匹配“|”两侧满足条件的字符
():匹配分组信息,表示一个整体信息,用于后项引用前项
{n,m}:匹配前一个字符至少出现n次,至多出现m次
{n}:匹配前一个字符出现n次
{n,}:匹配前一个字符至少出现n次
{,m}:匹配前一个字符至多出现m次
贪婪模式是指在正则表达式匹配成功的前提下,会尽可能多地匹配。例如: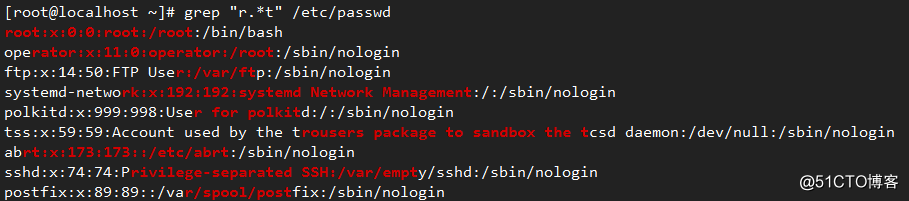
原文:https://blog.51cto.com/12631595/2667376