Graylog 是一个开源的日志管理系统。能够通过不同 Input 接口接收日志,并为用户提供 Web 访问接口,它使用 Elasticsearch 索引和保存日志,使用 MongoDB 作为配置信息的存储。
?
大致工作流程是日志信息通过 Inputs 进入 Graylog,如果有设置日志字段提取的话经过 Extractor,之后到达 Streams 日志流中,最后就是根据Streams 日志流设置写入指定 Index,然后根据日志流中设置的匹配信息触发 Alters 报警。
?
与当前流行的 ELK 相比,它更容易上手使用,而且带流量控制,有报警功能。所以才使用了 Graylog,用它来收集各个 Web、DB 的日志,工作站上 puppet、crontab 的运行日志以及防火墙交换机的日志并设置日志报警。
?
目前我学习和工作中使用的版本是 Graylog 2.4,安装在 CentOS 7.2 上。
Graylog 的安装很简单,直接可以参考官网的文档进行安装即可:
http://docs.graylog.org/en/2.4/pages/getting_started.html
Graylog 可以从插件市场通过插件和内容包来完善 Graylog 日志系统的功能使用:
https://marketplace.graylog.org
Graylog 通过 Inputs 收集日志,收集日志的方式支持很多,支持的方式如下:
Plain/Raw Text (TCP, UDP, AMQP, Kafka)
?
Graylog 比较常用的三种 Input 的方式:
通过 Syslog 的方式,在 Rsyslog 的配置文件中配置使用 UDP 或 TCP 发送日志到 Graylog,或直接使用 logger 命令发送给 Graylog:
UDP 配置:
*.* @graylog.wdroot.com:514;RSYSLOG_SyslogProtocol23FormatTCP 配置:
*.* @@graylog.wdroot.com:514;RSYSLOG_SyslogProtocol23Formatlogger 方式:
# bash command 2>&1 | logger -i -d -p alert -n graylog.wdroot.com -t ‘CROND check‘
server_url: http://graylog.wdroot.com:9000/api/
update_interval: 10
tls_skip_verify: false
send_status: true
list_log_files:
collector_id: file:/etc/graylog/collector-sidecar/collector-id
cache_path: /var/cache/graylog/collector-sidecar
log_path: /var/log/graylog/collector-sidecar
log_rotation_time: 86400
log_max_age: 604800
tags:
官方推荐的客户端 Sidecar 抓取日志,这里有一个最重要的东西就是标签 tags,例如上面客户端配置文件中设置的 tags 是 apache,会在 Graylog 的 Collectors 中设置的 apache 的 tag 匹配到,则客户端日志收集程序会使用 tag 是 apache 配置的日志输出方式将日志输入到Graylog 中。下图中,我针对 tag 是 apache 的客户端日志收集,针对 Beats 的收集方式采用的设置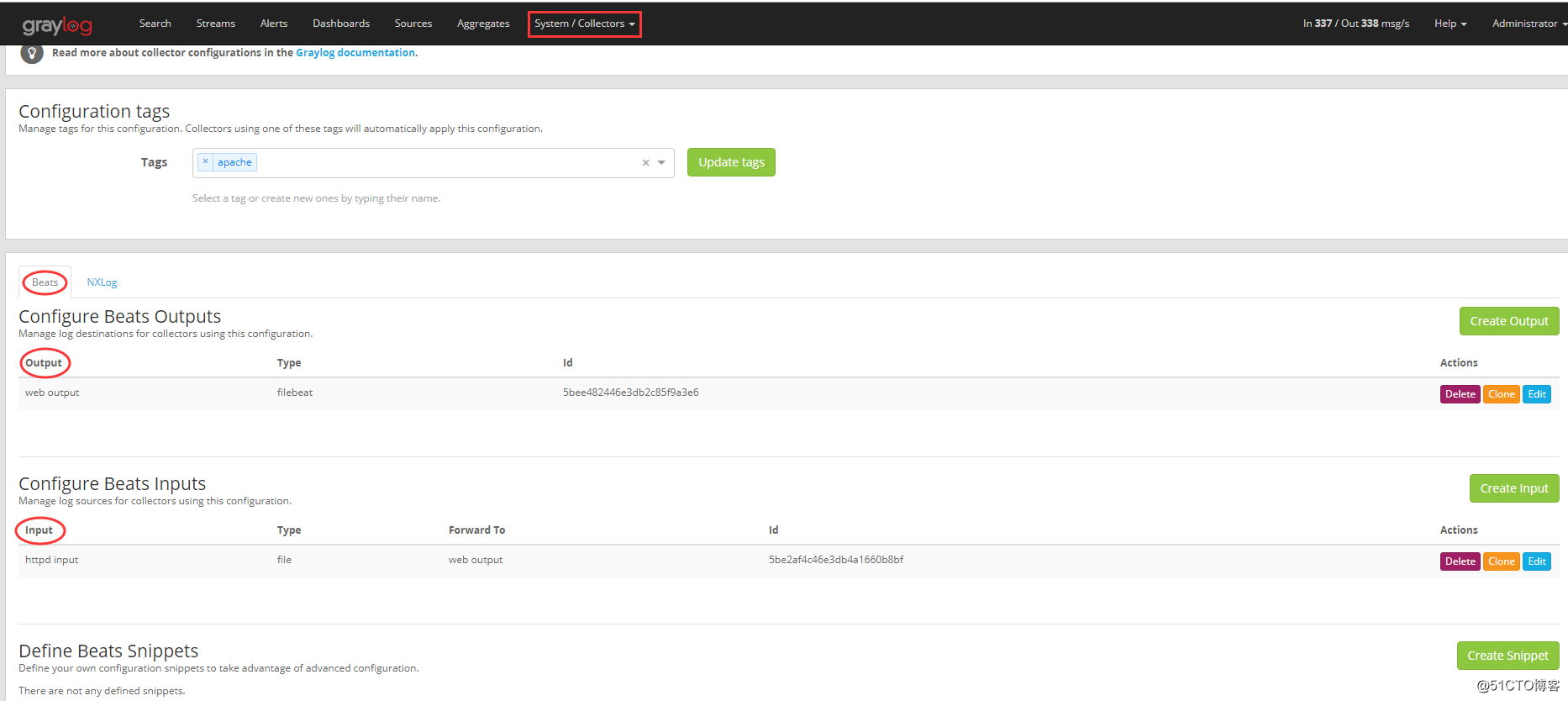
?
# curl -XPOST http://graylog.wdroot.com:12202/gelf -p0 -d ‘{“short_message”:”Hello there”, “host”:”example.org”, “facility”:”test”, “_foo”:”bar”}’在通过 Inputs 从客户端将日志收集到 Graylog 之后,下一流程就是 Extractor,类似于 logstash 中的 filter,可以从日志消息中提取自己想要的字段信息。每个 Input 需要单独配置 Extractors 来做字段转换提取。
?
例如接收的 Apache 的日志中含有访问 Apache 的源地址的,可以从 message 字段中单独将访问 Apache 的源地址通过 Extractor 提取出来,以便用于分析。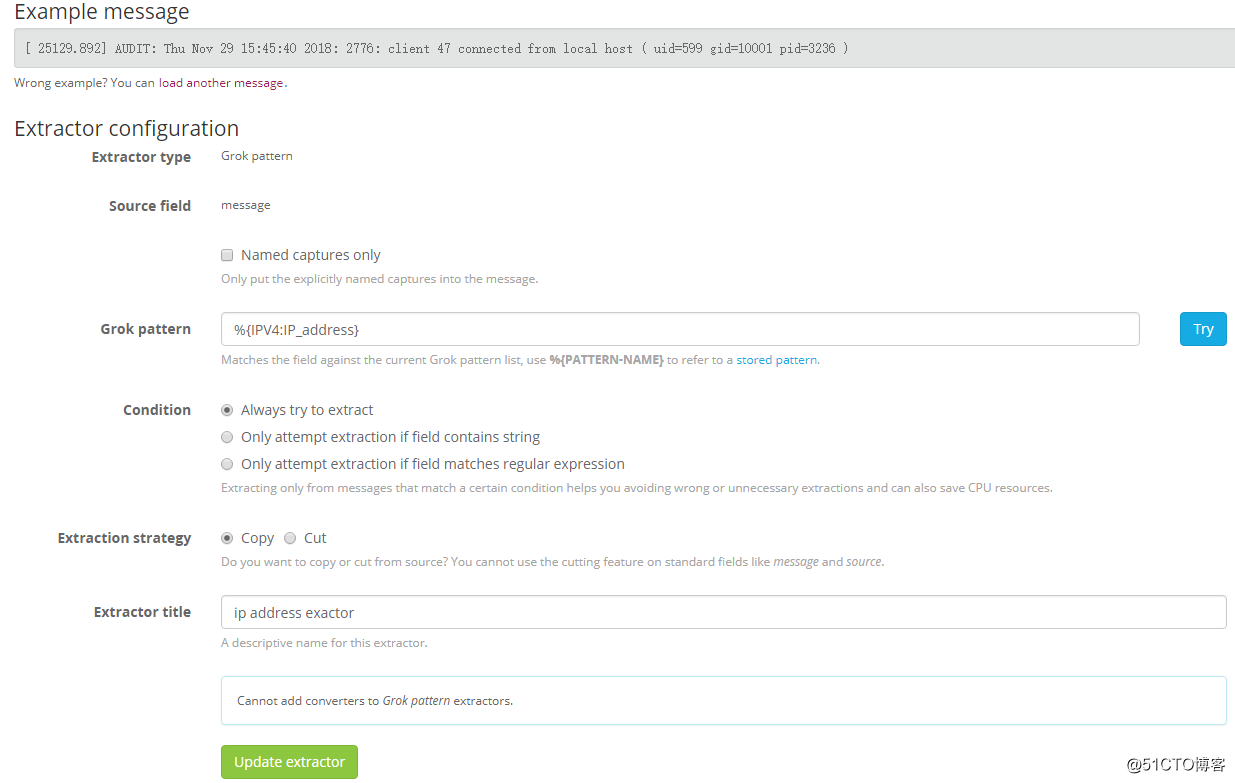
另外还可以根据 Graylog 市场中查找自己想要的 Extractor 内容包,然后通过 Graylog Web 导入到自己的 Graylog 中使用。例如我们收集了飞塔防火墙的日志,想要对飞塔防火墙的日志信息进行提取,就是在 Graylo g的市场中搜索 FortiGate 的内容包和插件。
日志通过 Graylog 的 Input,再经过 Extractor,之后就是 Stream。一个 Stream 隶属于一个 Index Set,但是多个 Streams 可以共享同一个 Index Set。Graylog 有一个默认的 Stream,默认是所有日志信息通过这个默认流写到默认的索引 Default index set。
?
可以在 Streams 中创建自己的 Stream,然后编写日志流规则。例如我想要将日志字段的 message 信息中一旦包含 Error 字符串,则将匹配到的日志信息写到自己指定的 error 索引文件中,这样的好处是接下来可以在 Alerts 报警中选择自己创建的 Stream,然后设置报警条件,也可以在后续的 Output 中输出到其他地方来进行处理,同时自己创建的索引文件可以自定义该索引文件的保留策略。
Graylog 中可以手动创建自己的索引 Index,创建索引的选项中可以根据自己的需要设置索引的分片、复制、索引文件的切分与保留。
?
关于 Shards: 每个 Index 分多少片,每一片可以保存在 Elastic 集群中不同的机器上。日志存储和查询的瓶颈一般是磁盘 IO,通过分片可以将 IO压力分摊到多台机器。
?
关于 Replicas: 每个 Shard 额外保存多少个副本,当有机器出现故障,只要集群内能凑齐每个 Shard 中至少一个副本就不会有任何影响。当然可靠性是靠存储的冗余来实现的,需要消耗更多的磁盘空间。
?
过期策略主要根据日志量,磁盘空间,需要查询的时间跨度来决定,Graylog 提供了三种 Index 文件切割方案:按时间、按 Index 中日志数量、按 Index 的占用磁盘大小。
创建报警条件,需要选择报警来自哪个 Stream 以及条件类型,默认自带的报警功能有点简单,如果不满足可以从 Graylog 的插件市场通过安装插件的方式来完善报警功能,例如安装 Aggregate 插件或者 graylog-plugin-zabbix 插件结合 Zabbix Server 的 trapper 方式进行日志报警。
先记录到这里,后面用到了其他功能再继续完善。从初期使用的这段时间来说,Graylog 确实是一个非常容易部署使用,Web UI 比较友好的一个日志管理系统,而且它还支持 LDAP 的验证,并可以根据不同组设置默认的权限,以及创建不同的角色设置不同的权限等等。
原文:https://blog.51cto.com/liubin0505star/2670959