你想获得双倍训练速度的快感吗?
你想让你的显存空间瞬间翻倍吗?
如果我告诉你只需要三行代码即可实现,你信不?
在这篇博客里,瓦砾会详解一下混合精度计算(Mixed Precision),并介绍一款Nvidia开发的基于PyTorch的混合精度训练加速神器--Apex,最近Apex更新了API,可以用短短三行代码就能实现不同程度的混合精度加速,训练时间直接缩小一半。
话不多说,直接先教你怎么用。
from apex import amp
model, optimizer = amp.initialize(model, optimizer, opt_level="O1") # 这里是“欧一”,不是“零一”
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()对,就是这么简单,如果你不愿意花时间深入了解,读到这基本就可以直接使用起来了。
但是如果你希望对FP16和Apex有更深入的了解,或是在使用中遇到了各种不明所以的“Nan”的同学,可以接着读下去,后面会有一些有趣的理论知识和瓦砾最近一个月使用Apex遇到的各种bug,不过当你深入理解并解决掉这些bug后,你就可以彻底摆脱“慢吞吞”的FP32啦。
为了充分理解混合精度的原理,以及API的使用,先补充一点基础的理论知识。
半精度浮点数是一种计算机使用的二进制浮点数数据类型,使用2字节(16位)存储。
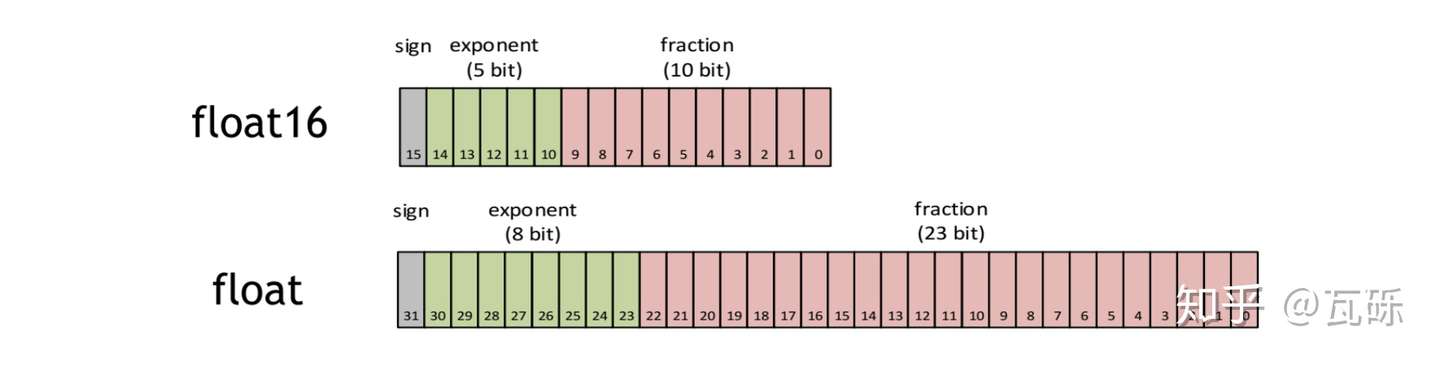 FP16的组成
FP16的组成
其中,sign位表示正负,exponent位表示指数( ),
fraction位表示的是分数( )。其中当指数为零的时候,下图加号左边为0,其他情况为1。
 fp16的样例
fp16的样例
在使用FP16之前,我想再赘述一下为什么我们使用FP16。
这个部分是整个博客最重要的理论核心。 讲了这么多FP16的好处,那么使用FP16的时候有没有什么问题呢?当然有。FP16带来的问题主要有两个:1. 溢出错误;2. 舍入误差。
 下溢出
下溢出
2. 舍入误差(Rounding Error) 舍入误差指的是当梯度过小,小于当前区间内的最小间隔时,该次梯度更新可能会失败,用一张图清晰地表示:
 舍入误差
舍入误差
曾经的Apex混合精度训练的api仍然需要手动half模型以及输入的数据,比较麻烦,现在新的api只需要三行代码即可无痛使用:
from apex import amp
model, optimizer = amp.initialize(model, optimizer, opt_level="O1") # 这里是“欧一”,不是“零一”
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()1. opt_level
其中只有一个opt_level需要用户自行配置:
O0:纯FP32训练,可以作为accuracy的baseline;O1:混合精度训练(推荐使用),根据黑白名单自动决定使用FP16(GEMM, 卷积)还是FP32(Softmax)进行计算。O2:“几乎FP16”混合精度训练,不存在黑白名单,除了Batch norm,几乎都是用FP16计算。O3:纯FP16训练,很不稳定,但是可以作为speed的baseline;2. 动态损失放大(Dynamic Loss Scaling)
AMP默认使用动态损失放大,为了充分利用FP16的范围,缓解舍入误差,尽量使用最高的放大倍数( ),如果产生了上溢出(Overflow),则跳过参数更新,缩小放大倍数使其不溢出,在一定步数后(比如2000步)会再尝试使用大的scale来充分利用FP16的范围:
 Nvidia关于动态损失放大的解释
Nvidia关于动态损失放大的解释
这一部分是整篇博客最干货的部分,是瓦砾在最近在apex使用中的踩过的所有的坑,由于apex报错并不明显,常常debug得让人很沮丧,但只要注意到以下的点,95%的情况都可以畅通无阻了:
amp.register_float_function(torch, ‘sigmoid‘)这篇从理论到实践地介绍了混合精度计算以及Apex新API(AMP)的使用方法。瓦砾现在在做深度学习模型的时候,几乎都会第一时间把代码改成混合精度训练的了,速度快,精度还不减,确实是调参炼丹必备神器。目前网上还并没有看到关于AMP以及使用时会遇到的坑的中文博客,所以这一篇也是希望大家在使用的时候可以少花一点时间debug。当然,如果读者们有发现新的坑欢迎交流,我会补充在博客中。
更优雅的排版请见我的博客:瓦特兰蒂斯
原文:https://www.cnblogs.com/sddai/p/14597434.html