程序要使用的数组放在一个叫 input.txt 的文件中, 文件格式是:
数组的行数,
数组的列数,
每一行的元素(用“,”隔开)
def Summax(lis): maxsum=int(lis[0])#定义存储当前的最大和 presum=0#定义存放之前的累加值 for i in lis: if presum<0: presum=int(i)#如果之前的累加和小于0,则替换当前值进行累加 else: presum+=int(i)#如果是大于等于0的则需要将当前的数加到当前最大子数组中 if presum>maxsum: maxsum=presum return maxsum #处理单维数组 infile=r‘abc.txt‘ f=open(infile,‘r‘,encoding="utf-8") sourceInLine=f.readlines() dataset=[] for line in sourceInLine: temp1=list(map(int,line.strip(‘,\n‘).split(","))) dataset.append(temp1) #第三行开始是要计算的数据 print(dataset) print(‘单维数组的最大连续子数组和是:‘,Summax(dataset[2]))
结果:
数组由一维变为二维,基本思路如下
1.遍历行,将行数组求和(先求最开始两个行数组的和,例如 [9, 2, -6, 2] [-4, 1, -4, 1],列求和得新的数组res1 = [5, 3, -10, 3],求res1中连续子串的最大和。
2.res1已经保存了初始的求和数组,继续将res1+arr[j],列求和得到新的res1,继续求res1的子串最大和。依次迭代。从第一行开始遍历,所以用两个for循环,第一个for用来遍历所有的行数,以每个作为起始,后用起始点后的剩余行进行叠加,求最大即可。
import numpy as np def Summax(lis): maxsum=int(lis[0])#定义存储当前的最大和 presum=0#定义存放之前的累加值 for i in lis: if presum<0: presum=int(i)#如果之前的累加和小于0,则替换当前值进行累加 else: presum+=int(i)#如果是大于等于0的则需要将当前的数加到当前最大子数组中 if presum>maxsum: maxsum=presum return maxsum def Read(infile):
#infile=r‘abc.txt‘
f=open(infile,‘r‘,encoding="utf-8")
sourceInLine=f.readlines()
dataset=[]
for line in sourceInLine:
temp1=list(map(int,line.strip(‘,\n‘).split(",")))
dataset.append(temp1)
arr=np.delete(dataset,[0,1],axis=0)#删除行列数据信息
l = len(arr)
max_num = 0
for i in range(l):
res1 = arr[i]
for j in range(i+1,l):
res1 = list(map(lambda x : x[0] + x[1],zip(res1,arr[j])))
max_num = max(Summax(res1),max_num)
print(arr)
print(‘二维数组的最大连续子数组和是:‘,max_num)
#return max_num
#1.numpy.delete(arr,obj,axis=None)arr:输入向量obj:表明哪一个子向量(第(obj+1)行)应该被移除。可以为整数或一个int型的向量axis:表明删除哪个轴的子向量,若默认,则返回一个被拉平的向量 #infile=np.delete(infile,[0,1],axis=0)
结果: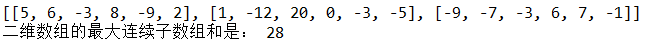
使用python自带测试库,安装测试库unittest
代码实现:
import unittest
from unittest import TestCase
class MaxTest(TestCase):
def test_1(self):
infile1=r‘abc1.txt‘
self.assertEqual(Read(infile1),28)
print("文本测试数据:MaxSum=",Read(infile1))
def test_2(self):
infile2=r‘abc2.txt‘
self.assertEqual(Read(infile2),33)
print("文本测试数据:MaxSum=",Read(infile2))
def test_3(self):
infile3=r‘abc3.txt‘
self.assertEqual(Read(infile3),37)
print("文本测试数据:MaxSum=",Read(infile3))
def test_4(self):
infile4=r‘abc4.txt‘
self.assertEqual(Read(infile4),31)
print("文本测试数据:MaxSum=",Read(infile4))
if __name__==‘__main__‘:
unittest.main()
结果:
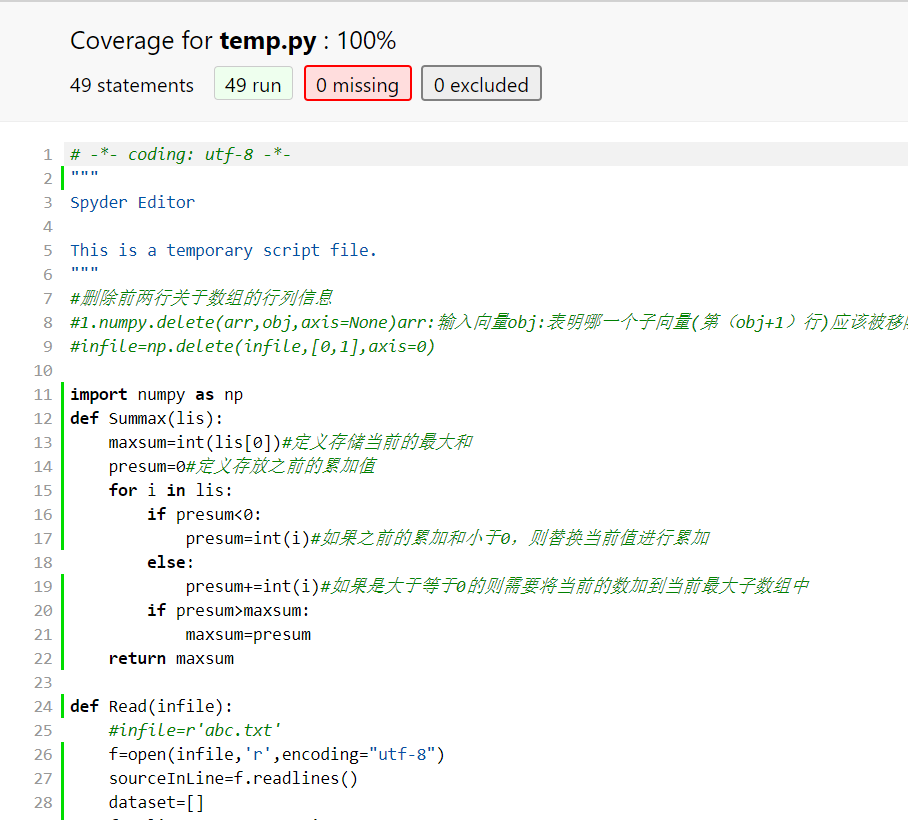
今天发现了一个好用的python代码覆盖率检查工具:coverage, 可以高亮显示代码中哪些语句未被执行,哪些执行了,方便单测。
coverage run test.py:开始统计执行,执行完会自动生成个.coverage的文件
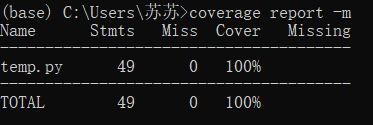
coverage report -m:命令行统计概要,执行率100%
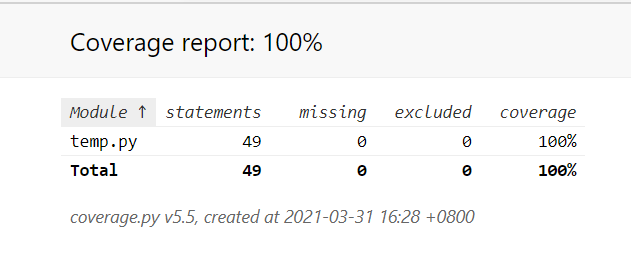
coverage html -d reportcoveragehtml:生成reportcoveragehtml的文件夹,包含html的结果报告,看起来更直观
仍然是在unittest框架中使用,加了一个文件关闭的方法file.clse(), 就可以了
原文:https://www.cnblogs.com/xyx520/p/14582278.html