>>> lines=sc.textFile("file:///usr/local/spark/mycode/rdd/word.txt")

>>> words = lines.flatMap(lambda line:line.split()).collect()

>>> wordsL = sc.parallelize(words)
>>> sc.parallelize(words).pipe("tr ‘A-Z‘ ‘a-z‘").collect()

>>> wordsL = sc.parallelize(words)
>>> wordsL.collect()
>>> wordsL.filter(lambda word:len(word)>3).collect()

>>> with open(‘/usr/local/spark/mycode/rdd/stopwords.txt‘)as f:
... stops=f.read().split()
>>> wordsL.filter(lambda word:word not in stops).collect()

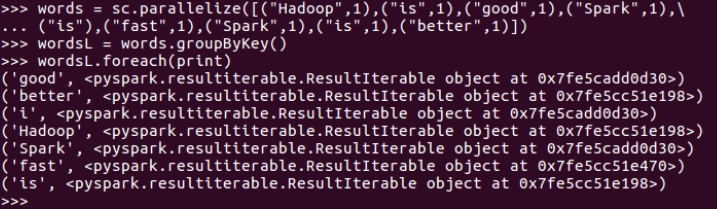
>>> words = sc.parallelize([("Hadoop",1),("is",1),("good",1),("Spark",1),... ("is"),("fast",1),("Spark",1),("is",1),("better",1)])
>>> wordsL = words.groupByKey()
>>> wordsL.foreach(print)
>>> lines = sc.textFile(‘file:///usr/local/spark/mycode/rdd/chapter4-data01.txt‘)

>>> lines.take(5)

>>> groupByName=lines.map(lambda line:line.split(‘,‘)).... map(lambda line:(line[0],(line[1],line[2]))).groupByKey()
>>> groupByName.take(5)
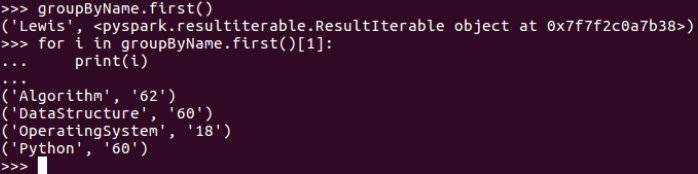
>>> groupByName.first()
>>> for i in groupByName.first()[1]:
... print(i)

>>> groupByCourse=lines.map(lambda line:line.split(‘,‘)).... map(lambda line:(line[1],(line[0],line[2]))).groupByKey()
>>> groupByCourse.first()
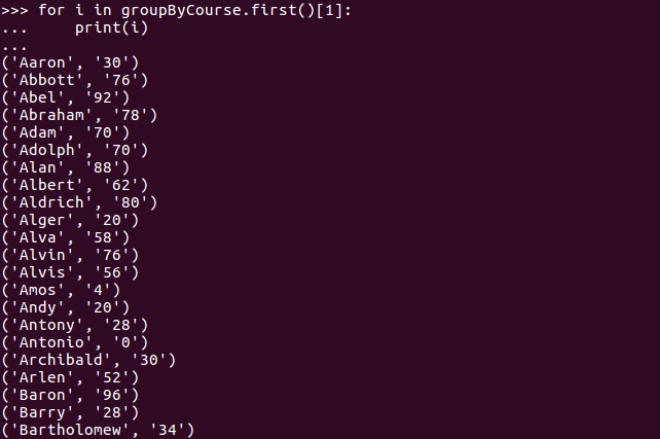
>>> for i in groupByCourse.first()[1]:
... print(i)

原文:https://www.cnblogs.com/86xiang/p/14603890.html