这篇演讲的第一部分,首先简单介绍HBase的基础内容,而后探讨RowKey在读写流程中所发挥的关键作用。HBase的基础内容大部分已经在下面的文章里面详细探讨:
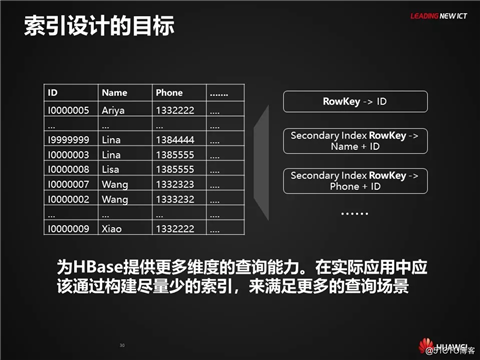
RowKey与索引设计,需要紧密结合业务需求场景。索引的设计目标是为HBase提供更多维度的查询能力。在实际应用中应该通过构建尽量少的索引,来满足更多的查询场景。因此第二部分介绍设计前需求调研的几个关键维度包括负载特点、查询场景以及数据特点。
负载特点
读写TPS;读写比重
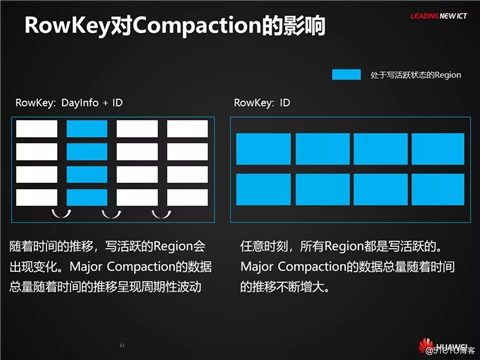
数据负载均衡与高效读取时常是矛盾的。
在重读轻写的大数据场景中,RowKey设计应该更侧重于如何高效读取。
而在重写轻读的大数据场景中,在满足基本查询需求的前提下,应该更关注整体的吞吐量,这就对数据的负载均衡提出了很高的要求。
查询场景
需要支持哪些查询场景?时延要求?
最高频的查询场景是什么?
是否有其它维度的价值查询场景?频度?
是否是组合字段场景?
各个字段的匹配类型?
数据特点
查询条件字段的离散度信息?
字段离散度的定义:
查询条件字段的数据分布特点?
数据生命周期?
第三部分介绍RowKey设计的几点技巧,二级索引RowKey设计的方法,组合字段RowKey/索引的适用场景/设计原则,字段组合的合理顺序等等。
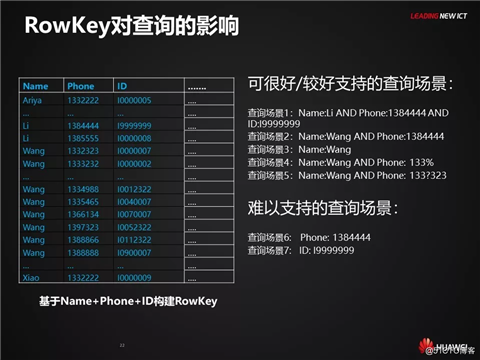
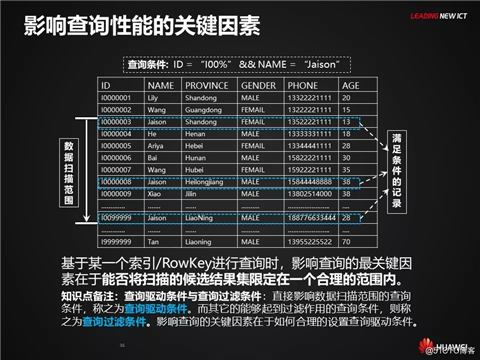
影响查询性能的关键因素
基于某一个索引/RowKey进行查询时,影响查询的最关键因素在于能否将扫描的候选结果集限定在一个合理的范围内。
知识点备注:查询驱动条件与查询过滤条件:直接影响数据扫描范围的查询条件,称之为查询驱动条件。而其它的能够起到过滤作用的查询条件,则称之为查询过滤条件。影响查询的关键因素在于如何合理的设置查询驱动条件。
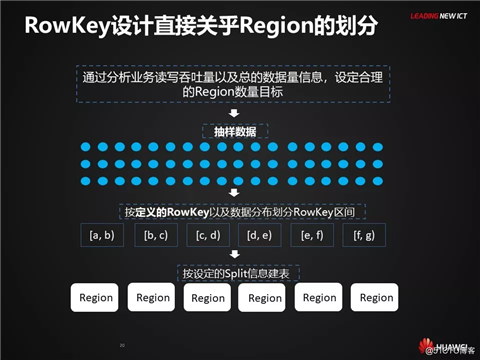
RowKey字段的选取
遵循的最基本原则:
唯一性: RowKey必须能够唯一的识别一行数据。
无论应用是什么样的负载特点,RowKey字段都应该参考最高频的查询场景。数据库通常都是以如何高效的读取和消费数据为目的,而不是数据存储本身。
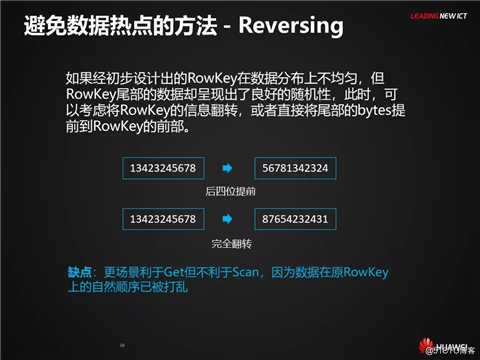
避免数据热点的方法 - Reversing
如果经初步设计出的RowKey在数据分布上不均匀,但RowKey尾部的数据却呈现出了良好的随机性,此时,可以考虑将RowKey的信息翻转,或者直接将尾部的bytes提前到RowKey的前部。
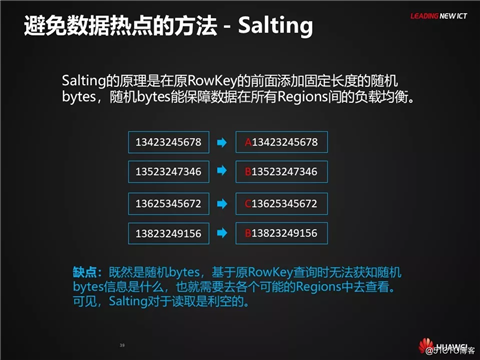
避免数据热点的方法 - Salting
Salting的原理是在原RowKey的前面添加固定长度的随机bytes,随机bytes能保障数据在所有Regions间的负载均衡。
缺点:既然是随机bytes,基于原RowKey查询时无法获知随机bytes信息是什么,也就需要去各个可能的Regions中去查看。可见,Salting对于读取是利空的。
避免数据热点的方法 - Hashing
基于RowKey的完整或部分数据进行Hash,而后将Hashing后的值完整替换原RowKey或部分替换RowKey的前缀部分。
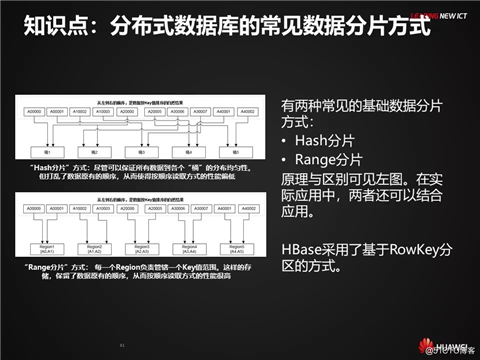
分布式数据库的常见数据分片方式
有两种常见的基础数据分片方式:Hash分片和Range分片
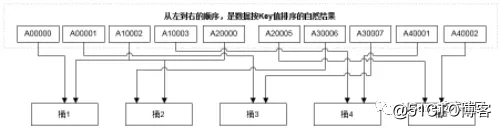
“Hash分片”方式:尽管可以保证所有数据到各个“桶”的分布均匀性。但打乱了数据原有的顺序,从而使得按顺序读取方式的性能偏低
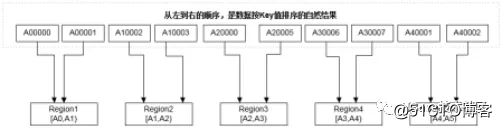
“Range分片”方式: 每一个Region负责管辖一个Key值范围。这样的存储,保留了数据原有的顺序,从而按顺序读取方式的性能很高
HBase采用了基于RowKey分区的方式。
实现Hash+Range分片的方法
RowKey构成: ID + OrderTime
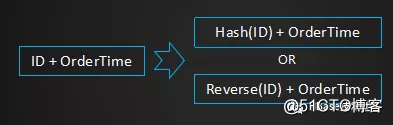
达成的效果:不同ID的数据可均匀打散到各个Region中,而同一个ID的数据则是相邻存放的。
HBase基于Range的方式可以为使用者带来很大的灵活度,但却提升了使用门槛!!!
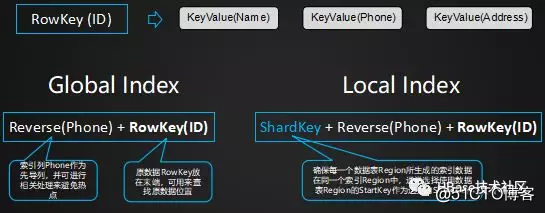
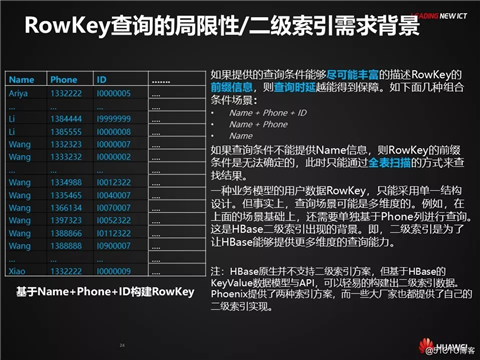
这是常见的设计思路,如果原数据RowKey中已经包含了索引列的信息,该设计容易导致数据冗余。
二级索引RowKey设计常见方法-有Schema模式

当原数据RowKey中的列与索引列有重叠时,该设计能避免一个列在索引列中被重复存储。但该设计需要事先支持Schema,也就是需要事先定义原数据的RowKey结构以及索引的结构信息。
二级索引字段的选取
对所有的价值查询场景进行详细分析,基于确实能够缩小查询范围的一部分列来构建二级索引。即,我们应该基于离散度较好的一些列来构建索引。
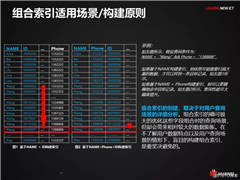
组合索引适用场景/构建原则
组合索引的创建,取决于对用户查询场景的详细分析。组合索引的确可极大的优化这些字段组合时的查询场景,但却会带来相对较大的数据膨胀。在不了解用户数据特点以及用户查询场景的情形下,盲目的构建组合索引,是要坚决避免的。
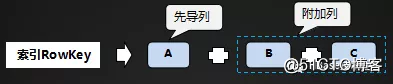
先导列的选取:
被选作先导列的列,一定是经常被用到的列
应选择设置了EQUALS查询条件的列作为先导列
先导列应该具备较好的离散度
尽量不要重复选择其它索引的先导列作为本索引的先导列
附加列的选取:
提供了EQUALS查询条件的列,应该放在前面部分
由于列的组合顺序将会影响到数据的排序,我们也应该考虑到业务场景关于排序的诉求
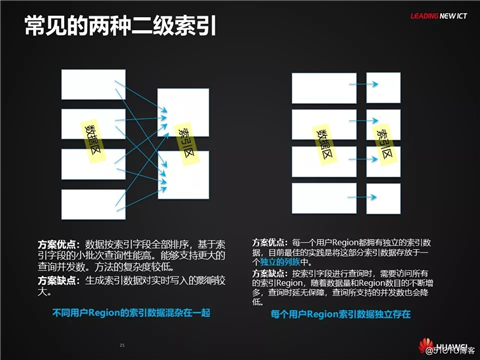
关于索引的其它建议
严格控制二级索引的数量
每一个索引所关联的索引数据总条数,与用户数据的总条数是1:1的。因此,在为一个用户表定义二级索引时,应该要考虑多个索引所带来的存储空间膨胀以及性能下降问题。建议在充分分析了各种查询场景的情况下,通过构建尽量少的索引,来满足更多的查询场景
Global Index在高并发/小批次查询场景中更有利
全文检索需求可考虑与Elasticsearch/Solr对接
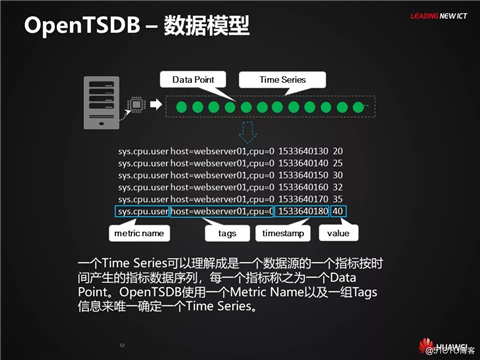
最后一部分围绕着OpenTSDB,JanusGraph以及GeoMesa三个典型的HBase生态技术,结合了它们各自的数据模型、查询场景,探讨它们的RowKey设计方案。
附上HBase RowKey与索引设计PPT:
备注:历届HBase Meetup会议的PPT: http://hbase.group/slides/






































原文:https://blog.51cto.com/15060465/2679163